
Do you think there is an affordable way to extract information in an editable format from images? Such technology does exist. Now, with the advantages of AI, JavaScript OCR APIs take it a notch higher. The accuracy of text recognition with OCR agents increases dramatically. In most cases, it reaches 90% or more. But how do you use JavaScript OCR API and AI together?
The objective of this blog is to show the advantages of using JavaScript OCR API and AI in text analysis. First, we will highlight the issue of unstructured data that many businesses encounter. You will appreciate how this combination provides successful results.
You will see the intersection of OCR and AI in practice. Before focusing on real-life applications, we will cover the positive features of both systems. Let’s get started.
Key Takeaways:
- Introduction to JavaScript OCR API and AI Appreciation:
Enables recognition of text. Technology changes improve comprehension. - Benefits of JavaScript OCR API and AI:
Provides more accurate results. Reduces human involvement. Enhances information extraction. - How JavaScript OCR API and AI Work Together:
Introduces the OCR technology’s working principles. Elaborates on how AI improves it. - Common Challenges:
Includes image quality issues. Involves complex integration. Can be expensive. - Solutions to Overcome Challenges:
Uses pre-processing methods. Follows an integrative approach. Offers budget-friendly options. - Industry Use Cases:
Includes healthcare, legal, and finance operations. - Best Practices for Implementation:
Develops documents for testing. Trains AI systems. Follows appropriate frameworks.
How do JavaScript OCR API and AI work together?
JavaScript OCR APIs extract words from images. This feature works like a built-in scanner on computer interfaces. Instead of scanning papers, the software scans images and looks for text in them. However, traditional OCR struggles with difficult layouts or poor image quality. That’s where AI assists.
AI advances OCR. These advancements make text recognition easier. Software can detect patterns and reconstruct extracted text contextually to reduce mistakes. AI-based OCR can identify different fonts and handwriting in multiple languages.
OCR handles basic text extraction. AI improves it. AI models use previous data to increase the efficiency of future text extractions. This also reduces human intervention.
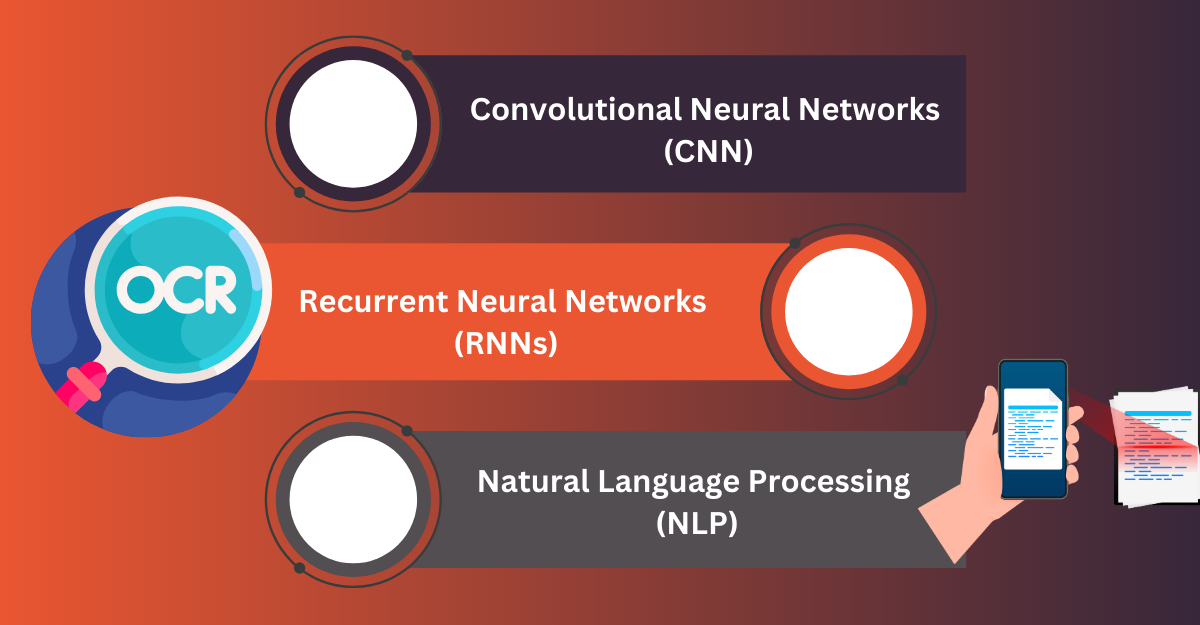
Examples of algorithms that expand OCR’s capabilities:
- Convolutional Neural Networks (CNNs) recognize text features in images.
- Natural Language Processing (NLP) analyzes text and extracts meaning.
- Recurrent Neural Networks (RNNs) recognize handwriting and generate text.
Using Filestack’s JavaScript OCR API and AI
To use Filestack optical character recognition or OCR technology API, navigate to the https://www.filestack.com/
Next, you should click on the Documentation tab:

Next, you should search for the Optical character recognition option in the left column:
Example Response
Here is the example response by the Filestack OCR engine:
{
"document": {
"text_areas": [
{
"bounding_box": [
{
"x": 834,
"y": 478
},
{
"x": 3372,
"y": 739
},
{
"x": 3251,
"y": 1907
},
{
"x": 714,
"y": 1646
}
],
"lines": [
{
"bounding_box": [
{
"x": 957,
"y": 490
},
{
"x": 3008,
"y": 701
},
{
"x": 2977,
"y": 1009
},
{
"x": 925,
"y": 797
}
],
"text": "Filestack can detect",
"words": [
{
"bounding_box": [
{
"x": 957,
"y": 490
},
{
"x": 1833,
"y": 580
},
{
"x": 1802,
"y": 888
},
{
"x": 925,
"y": 797
}
],
"text": "Filestack"
},
{
"bounding_box": [
{
"x": 1916,
"y": 589
},
{
"x": 2266,
"y": 625
},
{
"x": 2235,
"y": 932
},
{
"x": 1884,
"y": 896
}
],
"text": "can"
},
{
"bounding_box": [
{
"x": 2336,
"y": 632
},
{
"x": 3008,
"y": 701
},
{
"x": 2977,
"y": 1009
},
{
"x": 2304,
"y": 939
}
],
"text": "detect"
}
]
},
{
"bounding_box": [
{
"x": 860,
"y": 858
},
{
"x": 3330,
"y": 1049
},
{
"x": 3301,
"y": 1421
},
{
"x": 831,
"y": 1229
}
],
"text": "printed and handwritten",
"words": [
{
"bounding_box": [
{
"x": 860,
"y": 858
},
{
"x": 1550,
"y": 912
},
{
"x": 1521,
"y": 1283
},
{
"x": 831,
"y": 1229
}
],
"text": "printed"
},
{
"bounding_box": [
{
"x": 1677,
"y": 922
},
{
"x": 2047,
"y": 951
},
{
"x": 2018,
"y": 1321
},
{
"x": 1648,
"y": 1292
}
],
"text": "and"
},
{
"bounding_box": [
{
"x": 2107,
"y": 954
},
{
"x": 3330,
"y": 1049
},
{
"x": 3301,
"y": 1421
},
{
"x": 2078,
"y": 1326
}
],
"text": "handwritten"
}
]
},
{
"bounding_box": [
{
"x": 749,
"y": 1305
},
{
"x": 2504,
"y": 1486
},
{
"x": 2469,
"y": 1826
},
{
"x": 714,
"y": 1645
}
],
"text": "texts using OCR",
"words": [
{
"bounding_box": [
{
"x": 749,
"y": 1305
},
{
"x": 1233,
"y": 1355
},
{
"x": 1198,
"y": 1695
},
{
"x": 714,
"y": 1645
}
],
"text": "texts"
},
{
"bounding_box": [
{
"x": 1317,
"y": 1364
},
{
"x": 1910,
"y": 1425
},
{
"x": 1875,
"y": 1765
},
{
"x": 1282,
"y": 1704
}
],
"text": "using"
},
{
"bounding_box": [
{
"x": 1972,
"y": 1431
},
{
"x": 2504,
"y": 1486
},
{
"x": 2469,
"y": 1826
},
{
"x": 1937,
"y": 1771
}
],
"text": "OCR"
}
]
}
],
"text": "Filestack can detect\nprinted and handwritten\ntexts using OCR"
}
]
},
"text": "Filestack can detect\nprinted and handwritten\ntexts using OCR\n",
"text_area_percentage": 23.40692449819434
}OCR Endpoints
The Filestack’s intelligent document processing can be achieved through the given endpoints:
Get the OCR response on your image request body:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/ocr/<HANDLE>Use OCR with other tasks such as doc_detection:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/doc_detection=coords:false,preprocess:true/ocr/<HANDLE>Use OCR with an external URL of handwritten text:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL>Use OCR with Storage Aliases:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/src:/Code Example
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>OCR App</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 20px;
background-color: #f7f7f7;
}
h1 {
color: #333;
}
#result {
margin-top: 20px;
padding: 10px;
background-color: #e7e7e7;
border: 1px solid #ccc;
white-space: pre-wrap;
word-wrap: break-word;
}
</style>
</head>
<body>
<h1>OCR Application</h1>
<input type="file" id="fileInput">
<button onclick="uploadAndRecognizeText()">Upload and Recognize Text</button>
<div id="result"></div>
<script src="https://static.filestackapi.com/filestack-js/3.x.x/filestack.min.js"></script>
<script>
// Provide your Filestack API key here
const apiKey = '<YOUR_FILESTACK_API_KEY>';
const client = filestack.init(apiKey);
function uploadAndRecognizeText() {
const fileInput = document.getElementById('fileInput');
const file = fileInput.files[0];
if (!file) {
alert('Please select a file!');
return;
}
client.upload(file)
.then((response) => {
const handle = response.handle;
const policy = '<POLICY>';
const signature = '<SIGNATURE>';
const ocrUrl = `https://cdn.filestackcontent.com/security=p:${policy},s:${signature}/ocr/${handle}`;
fetch(ocrUrl)
.then((response) => response.json())
.then((data) => {
document.getElementById('result').textContent = JSON.stringify(data.text, null, 2);
})
.catch((error) => {
console.error('Error:', error);
document.getElementById('result').textContent = 'Error: ' + error.message;
});
})
.catch((error) => {
console.error('Upload error:', error);
alert('Failed to upload file.');
});
}
</script>
</body>
</html>
Note: You can modify the CSS styles based on your preferences. Plus, you should add the API key, security, and policy when running the code.
Let’s suppose I add the below image when running the above app:

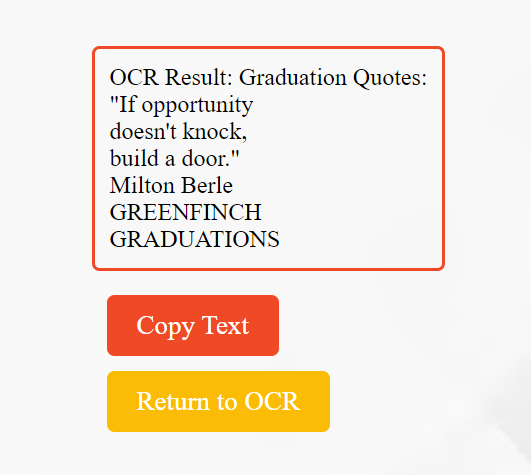
Benefits of using JavaScript OCR API and AI for text analysis
JavaScript OCR API and AI integration work well together for several reasons:
Improved accuracy
Traditional OCR often produces incomplete texts due to clutters from poor images or complex fonts. AI enhances accuracy by learning from previous mistakes, allowing higher precision even in difficult scenarios.
Automation of complex tasks
Manually analyzing large amounts of text is time-consuming. JavaScript OCR APIs, combined with AI, save time. These systems handle tasks such as error correction and content categorization, boosting productivity.
Better data extraction
Analyzing unstructured documents, like scanned images and PDFs, takes effort. AI-based OCR excels at extracting and organizing data from images, simplifying the process. It has multiple supported languages. Moreover, it can easily process handwritten documents using client libraries.
Use cases of JavaScript OCR API and AI in different industries
JavaScript OCR API and AI are useful in various industries. Here are examples from healthcare, legal, and financial sectors:
Healthcare
OCR techniques help manage clinical data and prescriptions. AI enhances handwritten note extraction, improving patient information systems and reducing prescription errors. A hospital using OCR to store medical documents electronically saw increased data availability and time savings.
Legal sector
Law firms use OCR to scan, capture, and analyze contracts and case files. AI performs these tasks quickly, reviewing large documents and identifying important clauses. One law firm used OCR to process thousands of pages in days rather than weeks.
Financial
In finance, OCR and AI automate invoice processing. They extract data from financial statements. This improves accuracy in bookkeeping. It also boosts efficiency. A financial institution adopted an OCR solution. As a result, it cut processing time by 50%.
Challenges and solutions in implementing JavaScript OCR API and AI
Implementing JavaScript OCR APIs and AI can bring benefits, but it also presents challenges. Here are common obstacles and ways to overcome them.
Common Obstacles
- Poor image quality leads to inaccurate text extraction. Blurry images and complex layouts create issues.
- Integrating OCR and AI into existing systems is complicated. Compatibility problems with legacy software may arise.
- Premium OCR APIs and AI model training are expensive. This may deter small businesses from adopting these technologies.
Solutions
To tackle these challenges, consider these solutions:
- Pre-processing techniques are used to improve image quality before OCR processing. Noise reduction and image sharpening yield better results.
- Design systems with modular architectures. This allows smoother integration of OCR and AI without disrupting operations.
- Evaluate open-source OCR options and scalable cloud-based APIs. This reduces costs while maintaining functionality.
Best Practices for Successful Integration
- Test OCR performance with various image types. This helps identify weaknesses and areas for improvement.
- Continuously train AI models with new data. Incorporate user feedback for ongoing enhancements.
- Keep clear documentation of integration steps. This aids in future updates and helps new team members.
Conclusion
Combining JavaScript OCR APIs with AI offers powerful solutions for text analysis. This synergy significantly enhances text recognition accuracy. It often improves by up to 90%. Businesses can automate complex tasks and streamline data extraction. This leads to better efficiency in managing unstructured documents.
Industries like healthcare, legal, and finance are adopting these technologies. From digitizing patient records to processing contracts and invoices, the applications are vast and impactful.
However, successful implementation comes with challenges. Data quality and integration complexity can hinder progress. To overcome these, organizations should follow best practices. Thorough testing and continuous training of AI models are essential for maximizing investments.
Embracing JavaScript OCR API key and AI can transform how businesses handle text data. It makes workflows more efficient and accurate. The future of text analysis is bright. The time to start is now.
FAQs
Can AI do OCR?
Yes. AI can perform OCR by accurately recognizing and extracting text from images. You can achieve it through the Filestack API.
Can JavaScript do OCR?
Yes. JavaScript can perform OCR on an image file by using libraries like Tesseract.js to extract text from images.
What is the difference between OCR and AI OCR?
OCR extracts text from a local image; AI OCR uses machine learning and computer vision to enhance accuracy and context.
What is the best open-source OCR AI?
Tesseract is widely regarded as the best open-source OCR AI available today to extract text from a remote image.
Sign Up for free at Filestack to use an AI OCR with a highest accuracy.

Ayesha Zahra is a Geo Informatics Engineer with hands-on experience in web development (both frontend & backend). Also, she is a technical writer, a passionate programmer, and a video editor. She is always looking for opportunities to excel in her skills & build a strong career.
Read More →