
Artificial Intelligence (AI) is changing how we use technology. Object detection APIs play a key role in this shift. Multi-object recognition API can detect multiple objects in a single image. This helps machines interpret visual information accurately. They can detect objects efficiently.
Industries like retail, healthcare, and transportation are using these APIs. Their usage is growing fast. They boost productivity and improve data interpretation. This blog focuses on object detection models. It starts with an explanation of these APIs and how they work.
Then, it highlights their features and benefits. Challenges faced by these APIs will also be discussed. Solutions to these issues will follow. Finally, recommendations for specific APIs will be shared. These APIs can track objects and extract multiple objects from images. Examples from real-world applications will also be included.
Stay with us to explore their potential. Let’s begin.
Key takeaways
- Multi-Object Recognition APIs or Artificial Intelligence APIs recognize multiple objects in a picture or video. They provide details about the surroundings, including object localization with bounding boxes.
- These systems rely on instant object detection and analysis. This is critical for time-sensitive environments. Examples include traffic management systems and live surveillance, where an object detector is essential.
- The models improve the recognition system. They offer high accuracy and support for different formats. Custom models, often built with pre-trained models, can be applied in industries like retail and healthcare.
- Object recognition APIs lower the requirements and resource allocation. They are useful for tasks like inventory tracking in retail and packet tracking in logistics, involving feature detection in local images.
- These APIs solve the problems of large dataset management, accuracy in complex environments, and evolving needs.
- In the transport industry, medical device detection and stock tracking in retail are powered by object detection APIs. By drawing bounding boxes around objects, the object detector can precisely track items in an entire image.
- Important aspects like structure, cost, use case, and relevance help decide which API to use. Options like Google Vision, AWS Rekognition, and Filestack file uploader are available, offering integration with Google Cloud for better performance.
- Multi-object recognition APIs enhance process automation, workflow improvement, and foster creativity within a company, even when working with local files.
What is a multi-object recognition API?
A multi-object recognition API is an AI-based tool. It helps applications recognize multiple objects in images or videos. These objects can be text, people, animals, or vehicles. They can also be furniture and other items. The API classifies objects even if they overlap or have different orientations.
These APIs streamline object recognition. Developers and businesses benefit from this. They offer off-the-shelf solutions, such as Azure Cognitive Services, which can be easily integrated into apps. Programmers save time by avoiding complex algorithms like deep learning models. This optimizes resources and reduces costs.
Multi-object recognition APIs can locate objects in images or videos. They classify these objects into categories using trained models. They also provide information about the objects and their environment in JSON format.
For example, an API can find items on a store shelf. It helps manage stock efficiently. It can also detect common objects like cars, trees, or dogs. In healthcare, it can locate surgical tools in images using a custom vision model.
These APIs bring advanced object recognition to users. They allow businesses to add powerful features to apps with minimal setup. With the following code snippet, developers can use the Vision API and start building applications. This makes AI accessible without much technical expertise.
To use these APIs in a Python script, you may need to install dependencies first.
Key features of advanced multi-object recognition API
Multi-object recognition is essential for image or video analysis. It enhances technologies for various uses. Let’s explore the key features of the advanced multi-object recognition API:
Real-time Detection and Analysis
These APIs analyze data in real time. This is crucial for security, traffic control, and live streams. They capture photos or videos instantly. This leads to quick and lasting solutions.
High Accuracy and Scalability
Advanced APIs use AI and machine learning. This ensures high accuracy even in complex environments. They are flexible and work well for small or large tasks.
Compatibility with Multiple Data Formats
These APIs support various formats like JPEG, PNG, and MP4. This allows integration across platforms. Developers don’t need to worry about format constraints.
Customizable Models for Specific Use Cases
Some APIs let you customize models. Retailers can train APIs to recognize their goods. This makes these APIs useful in sectors like health, agriculture, and manufacturing.
These features make them essential for building advanced applications.
Advantages of using a multi-object recognition API
These APIs save time and resources. They improve object detection. For example, creating custom systems is expensive. APIs like Google Vision and AWS Rekognition simplify this. In retail, an algorithm can find missing items on shelves. This reduces physical checks. Let’s explore the benefits with real-life examples:
Saves time and resources
Teaching a system to recognize objects is expensive. It needs big datasets and specialists. APIs like Filestack, Google Vision, or AWS Rekognition solve this problem easily. For example, in retail, these APIs check stock by recognizing out-of-stock products.
Easy integration
APIs can be deployed on current frameworks quickly. For example, a traffic management system can integrate an API. It identifies cars and people as they move.
Enhanced efficiency and accuracy
Pre-trained models boost efficiency. Warehouses use these APIs to manage packet movement. They do this without physical tagging.
Accelerates innovation
Business development involves creating new features. APIs reduce the need for recognition logic. For example, self-driving cars use APIs to recognize road signs and obstacles.
Object detection is faster with APIs in business. Costs are lower, and processes are more streamlined.
Challenges in multi-object recognition and how APIs address them
Multi-object recognition faces challenges. These include dataset size, accuracy, and new needs. APIs address these problems effectively.
Handling Large Datasets Efficiently
Object recognition needs large datasets. Collecting, labeling, and processing this data is expensive. For example, online shopping platforms must identify millions of products. APIs like Google Vision and AWS Rekognition handle such tasks. They process data quickly without requiring many resources.
Achieving High Accuracy in Complex Environments
Systems often fail in difficult situations in terms of accuracy. Poor lighting, background noise, and hidden regions are common problems. For example, security cameras may struggle in low light or crowded areas. Tailor-made solutions may not work. APIs use powerful machine learning models trained on diverse data. This improves performance in challenging environments.
Adapting to Evolving Requirements and Edge Cases
Business goals change over time. New object classes or edge cases arise. For example, autonomous vehicles may encounter unfamiliar traffic signs. Traditional systems need costly retraining. APIs like Microsoft Azure Computer Vision handle these changes efficiently. They adjust with ease and accuracy.
APIs make object recognition systems smarter and more cost-effective. They automate tasks and solve complex issues in real time.
Choosing the right multi-object recognition API
Selecting the right API is crucial. Factors like scalability, cost, usability, and compatibility are key. Let’s explore these unique factors:
Factors to Consider
Scalability
The API should handle future growth. For example, a retail app processing 1,000 images a day may scale to millions during sales. AWS Rekognition is a good option for this.
Ease of Use
APIs should integrate smoothly. Google Vision provides documentation and SDKs for easy integration.
Compatibility
The API should support the platform and language in use. Microsoft Azure Computer Vision works well with Windows and cross-platform apps.
Cost
Budget often matters. Startups may prefer Clarifai for its affordable pay-per-use pricing.
Comparison of Popular APIs
Filestack
Filestack focuses on image processing and object recognition. It supports uploading, processing, and storage. Its AI image tagging is useful for media-rich apps. It suits photo-sharing websites, content management, and e-commerce.
Google Vision API
Google Vision is affordable and accurate. It detects text, objects, and landmarks in images. It is often used in e-commerce and travel.
AWS Rekognition
AWS Rekognition excels in facial recognition and scalability. It is popular in security and retail.
Microsoft Azure Computer Vision
This API is strong in OCR and object localization. It is ideal for enterprise projects.
Clarifai
Clarifai is cheap and flexible. It is commonly used by startups and small apps.
Carefully consider these options. This will help you choose the best API for your needs.
Integrating Filestack Multi-Object Recognition API
First, you should get an API key from Filestack.
Next, you should get the policy and signature to ensure the security of Filestack API integration.
Then, you should create an index.html file inside the Visual Studio Code and add the following code to it:
HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Instagram Hashtags Generator</title>
<script src="https://static.filestackapi.com/v3/filestack.js"></script>
<style>
/* CSS goes here */
</style>
</head>
<body>
<div class="container">
<h2>Instagram Hashtags Generator</h2>
<button id="uploadBtn">Upload Image</button>
<h3>Generated Hashtags:</h3>
<p id="hashtags"></p>
</div>
<script>
/* JavaScript goes here */
</script>
</body>
</html>
Explanation
- <!DOCTYPE html> specifies the document type as HTML5.
- <html lang=”en”> indicates the start of the HTML document and sets the language to English.
- <head>:
- <meta charset=”UTF-8″> sets the character encoding to UTF-8.
- <meta name=”viewport” content=”width=device-width, initial-scale=1.0″> ensures the page is responsive by setting the viewport width to the device’s width.
- <title> sets the title of the page to “Instagram Hashtags Generator.”
- <script> links the Filestack JavaScript library for file handling.
- <style> contains CSS for styling the page.
- <body>:
- <div class=”container”> wraps the content inside a styled box.
- <h2> displays the heading “Instagram Hashtags Generator.”
- <button> adds a button labeled “Upload Image.”
- <h3> displays a subheading “Generated Hashtags.”
- <p id=”hashtags”> is an empty paragraph to show the generated hashtags
CSS
The CSS section styles the webpage, ensuring a visually appealing design. It centers content, applies gradients, and adds animations like fade-ins and pulsating effects. Buttons have hover effects with shadows and scaling. The layout is responsive, ensuring proper alignment and spacing. Custom animations and gradients enhance user experience and interactivity.
You can get the existing CSS styles here. You can also customize the styles.
JavaScript
const apiKey = 'add-api-key-here';
const policy = add-policy-here';
const signature = ‘add-signature-here';
const client = filestack.init(apiKey);
document.getElementById('uploadBtn').addEventListener('click', function() {
client.pick().then(function(result) {
const handle = result.filesUploaded[0].handle;
const tagsUrl = `https://cdn.filestackcontent.com/${apiKey}/security=p:${policy},s:${signature}/tags/${handle}`;
fetch(tagsUrl)
.then(response => response.json())
.then(data => {
if (data.tags && data.tags.auto) {
const tagNames = Object.keys(data.tags.auto);
const hashtags = tagNames.map(tag => `#${tag}`).join(' ');
document.getElementById('hashtags').textContent = hashtags;
} else {
document.getElementById('hashtags').textContent = 'No hashtags found for this image.';
}
})
.catch(error => {
document.getElementById('hashtags').textContent = 'Error fetching hashtags.';
});
}).catch(function(error) {
console.error('File upload error:', error);
});
});
Explanation
The JavaScript section provides functionality:
- Filestack Initialization:
- const client = filestack.init(apiKey); initializes the Filestack client using the provided API key.
- Button Click Event:
- document.getElementById(‘uploadBtn’).addEventListener(‘click’, …) sets up an event listener for the “Upload Image” button.
- File Upload Process:
- client.pick() opens the Filestack file picker to upload an image.
- On successful upload, it retrieves the image’s handle for further processing.
- Hashtag Retrieval:
- Constructs a URL using Filestack’s API to fetch tags for the uploaded image.
- Uses fetch() to get tag data in JSON format.
- Displaying Hashtags:
- If tags are available, it formats them into hashtags and displays them in the <p> element.
- If no tags are found or an error occurs, it shows an appropriate message.
- Error Handling:
- Catches and logs any errors during the file upload or tag fetching process.
Get the complete code from our GitHub repository.
Output


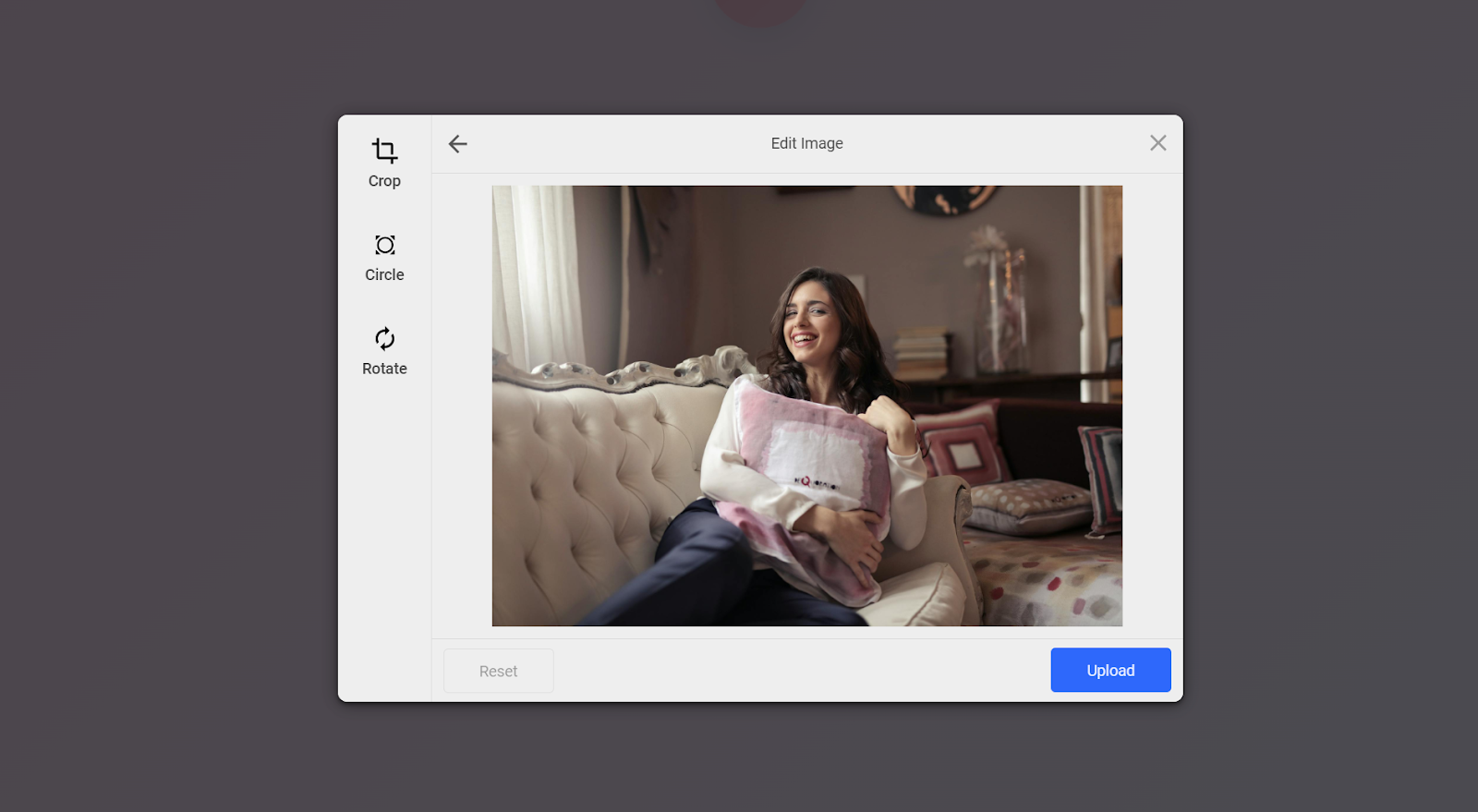
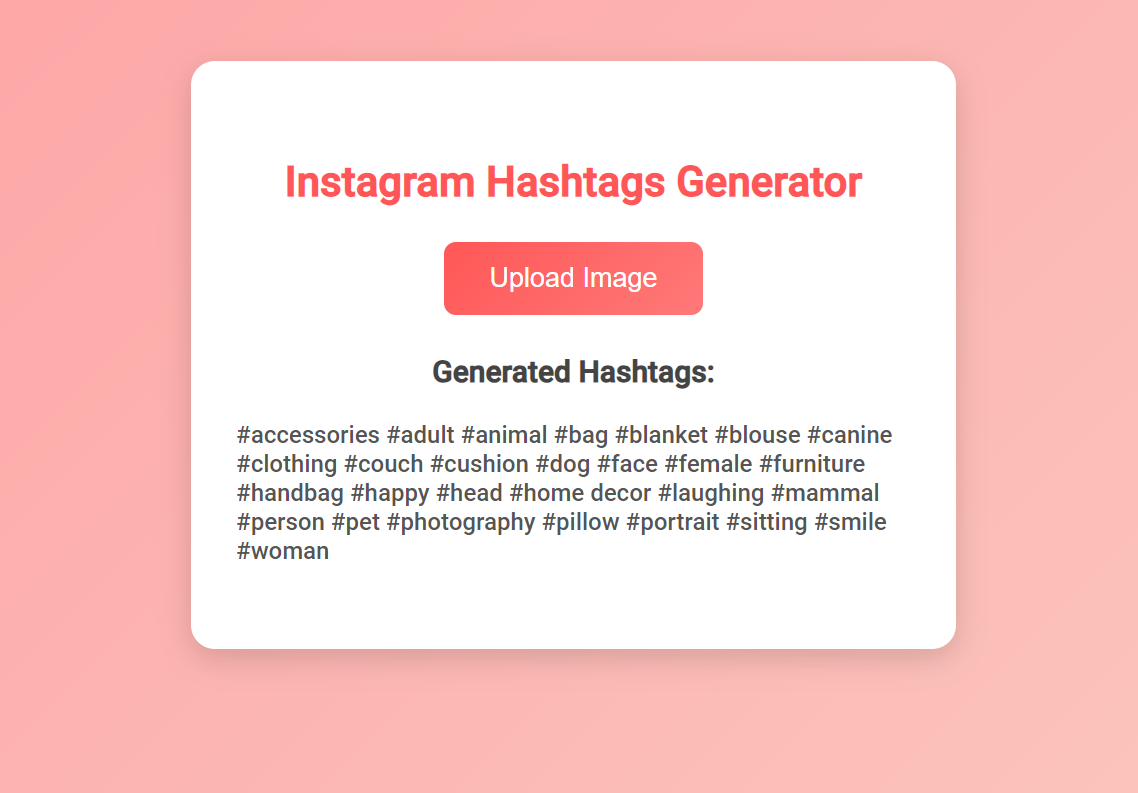




Conclusion
Artificial Intelligence (AI) is transforming industries. Multi-object recognition API plays a key role in this transformation. These APIs identify and analyze multiple objects quickly and accurately in a single image or video stream.
They save developers time and reduce costs. This allows businesses to focus on innovation. Industries like retail, healthcare, and transportation use them widely. For example, APIs track retail inventory and detect medical tools in healthcare.
These APIs work by identifying rectangular bounds around objects. You must know that localized object annotation identifies information about each object, including confidence score and lighting conditions. It is used by object detection APIs
APIs solve challenges like handling large datasets. They ensure accuracy in complex environments and under varying lighting conditions. By choosing the right API, businesses unlock AI’s potential. This drives innovation and improves workflows across various applications.
FAQs
Can multi-object recognition APIs differentiate between overlapping objects in an image?
Yes, they can identify and separate overlapping objects, like cars, in a crowded parking lot.
What industries are leveraging multi-object recognition APIs for their operations?
Retail, healthcare, security, and automotive industries use these APIs for tasks like inventory management and surveillance.
How do multi-object recognition APIs improve the accuracy of data analysis?
They analyze objects with high precision, enhancing data insights in sectors like e-commerce and healthcare.
Are there any limitations in the types of objects that can be recognized by these APIs?
Yes, they may struggle with recognizing highly abstract or uncommon objects, like rare artifacts.
What are some innovative use cases of multi-object recognition APIs in everyday applications?
They are used in self-driving cars to detect obstacles, road signs, and pedestrians.
Sign Up at Filestack today – Explore the versatile benefits of our multi-object recognition API.

Ayesha Zahra is a Geo Informatics Engineer with hands-on experience in web development (both frontend & backend). Also, she is a technical writer, a passionate programmer, and a video editor. She is always looking for opportunities to excel in her skills & build a strong career.
Read More →