
Data entry is time-consuming and error-prone. However, advancements in OCR APIs are changing the game. Optical Character Recognition (OCR) automates text extraction from images and scanned documents. It improves accuracy and significantly reduces manual effort.
Free OCR APIs are available for developers and businesses seeking cost-effective solutions to streamline data management. However, we must be careful when selecting these free tools. Not all free OCR APIs are created equal, and some have limitations that impact performance, security, or reliability.
In this article, we will explore the impact of free OCR APIs on data entry. We will also discuss their challenges and how solutions like Filestack can overcome them and optimize and enhance the process.
What is OCR technology?
Have you ever wished to magically convert a printed document or an image full of text into editable digital text? That’s exactly what optical character recognition (OCR) technology does. Instead of manually typing out information from scanned documents, OCR enables computers to “read” printed or handwritten text from images like a scanned document or photo and convert it into a machine-readable format.
A quick look at OCR’s evolution
OCR technology has come a long way. The early concept of Optical Character Recognition has ties to telegraphy, which started in the early 20th century. Both were involved in converting visual symbols into electrical signals.
The revolution of OCR technology started with the invention of the GISMO machine in the 1950s. This machine, also known as an “analyzing reader, “could convert printed text into machine language.
After that, many companies, such as IBM, contributed to developing OCR machines. In 1959, IBM introduced a machine called Optical Character Recognition (OCR) to capture data from documents and standardize this terminology in the industry.
After the 1970s, OCR technology grew to include the capability of handwritten text recognition, called intelligent character recognition (ICR). This invention revolutionized OCR technology and created the path for future machine learning (ML) driven improvements. Magnetic Ink Character Recognition (MICR) was also introduced to the banking industry for efficient check processing.
Later, with the advancements of algorithms, AI, and machine learning, modern OCR tools can now handle handwriting, multiple languages, and complex layouts with impressive accuracy. What once required specialized software is now accessible through free OCR APIs, making text extraction easier than ever.
How does OCR work?
The process behind OCR may sound complex, but here’s a simple breakdown:
- Image Capture – The OCR system takes in an image, whether a scanned document, a photo of a receipt, or a screenshot of a text-heavy webpage.
- Preprocessing – The image is cleaned up to improve readability. This can include adjusting brightness, removing noise, and sharpening blurry areas.
- Text Detection – The system identifies areas of the image that contain text and separates them from non-text elements like background images.
- Character Recognition – The OCR engine analyzes the text areas, matching them against known letters, numbers, or symbols. Advanced OCR tools use AI to improve recognition, even for tricky fonts or handwritten words.
- Text Output – Finally, the extracted text is converted into a usable format, like a plain text file, a Word document, or structured data for further processing.
The emergence of free OCR APIs
Earlier, OCR technology was available only with expensive software. Today, free OCR APIs have made text recognition widely accessible and allow developers, businesses, and even individuals to integrate OCR into their workflows.
Popular free OCR APIs you should know
In this section, we will discuss several free OCR APIs that are available today. Each offers different features and levels of accuracy.
- Filestack OCR API – A developer-friendly OCR API that offers high accuracy, robust security, and seamless integration with file uploads. It simplifies data extraction while ensuring scalability and reliable performance for businesses and applications.
- Tesseract OCR – An open-source OCR engine developed by Google. It supports multiple languages and can handle handwritten text, though it requires some fine-tuning for optimal accuracy.
- Microsoft Computer Vision API (Free Tier) – Part of Azure’s cognitive services, this API provides OCR capabilities along with additional image recognition features. The free tier has limited monthly usage.
- Google Cloud Vision OCR (Limited Free Use) – Google’s powerful OCR tool can extract text from images and even detect handwriting. The free tier offers a limited number of monthly requests.
- OCR.space API – A no-cost OCR service that works with various document formats and supports multiple languages. It’s an easy-to-use option for quick text extraction.
- Adobe PDF Extract API (Trial) – While Adobe’s OCR capabilities are typically part of its premium services, they offer a free trial with limited features for testing purposes.
Why are free OCR APIs game-changers?
Free OCR APIs are becoming popular among developers and businesses mainly due to their cost-effectiveness. Here’s what makes them a cost-effective and accessible solution:
- No Upfront Costs – Unlike traditional OCR software, free APIs allow businesses and developers to integrate text recognition without paying for expensive licenses.
- Easy Integration—Many free OCR APIs have simple RESTful interfaces, making them developer-friendly and easy to integrate into existing applications.
- Cloud-Based Convenience – Most of these APIs run in the cloud, meaning there’s no need for complex installations or local processing power.
- Support for Multiple Languages – Free OCR tools often include multilingual support, making them valuable for businesses dealing with international documents.
How do free OCR APIs enhance data entry?
Manual data entry is slow and prone to errors. We may process invoices, digitize receipts, or extract information from business documents, but the traditional way of typing data is inefficient. OCR APIs automate text extraction and improve the accuracy. In addition to this, free OCR API has become a cost-effective way of extracting data from scanned documents and images.
Let’s discuss how free OCR APIs enhance data entry.
Speeding up data entry
Speed data entry is one of the biggest advantages of free OCR APIs. No more manual typing is required spending hours; businesses can simply upload images and extract text in seconds. We can reduce processing time significantly in this way and focus on more critical tasks.
Improving accuracy
Human errors like typos and misinterpretations are a common problem in manual data entry. OCR-powered text extraction eliminates these issues by using AI-driven recognition. This technology converts text with precision. While OCR APIs might not be 100% accurate, they still outperform manual data entry in speed and efficiency.
Handling large volumes of data
For businesses dealing with large amounts of paperwork—like invoices, contracts, or legal documents—free OCR APIs help automate bulk data extraction. Instead of inputting data one file at a time, APIs can process multiple documents in one go, making workflows significantly more scalable.
Supporting multiple formats
Most free OCR APIs don’t just recognize printed text; they also support:
- Handwritten text (depending on the API)
- Multiple languages for international documents
- Different file formats (JPG, PNG, PDF, etc.)
This flexibility makes them valuable for a wide range of industries, from finance and healthcare to retail and logistics.
Making OCR more accessible
Free OCR APIs enable startups, small businesses, and developers to integrate OCR capability into their applications at no cost. We don’t have to spend on expensive software packages to leverage OCR technology. Free OCR APIs provide an affordable way to improve efficiency for different tasks like document automation, digitizing records, etc.
Also read: OCR Data Extraction vs. Manual Data Entry: A Comparative Analysis
What are the common issues with free OCR APIs?
While free OCR APIs are a great way to start automating text extraction, they also come with some limitations. Let’s look at some of the most common issues.
1. Limited language support
Many free OCR APIs work well with widely used languages like English, Spanish, and French, but they often struggle with complex scripts such as Asian languages (Chinese, Japanese, Korean), Arabic or right-to-left scripts, rare or indigenous languages and handwritten text in different languages.
2. Accuracy drops with poor-quality scans
OCR accuracy heavily depends on the quality of the scanned image. If the image is blurry, distorted, or contains background noise, the OCR tool might:
- Misinterpret characters (turning “8” into “B” or “1” into “l”)
- Skip words or entire lines
- Struggle with complex fonts or handwritten text
Free OCR APIs may not have the advanced image preprocessing features that premium tools offer, meaning you might need additional software to clean up your images before processing them.
3. Data security concerns
Most free OCR APIs operate on third-party servers, meaning your documents are processed outside your local system. This raises serious security concerns, especially for businesses handling sensitive data such as legal documents, medical records, financial reports, and confidential contracts.
Since free OCR services often don’t include strong encryption or compliance guarantees, using them for sensitive data could expose your information to security risks.
4. API rate limits and processing speed
Most free OCR APIs impose limits on the number of requests per day or month. If you’re processing large volumes of documents, you might hit request limits quickly and experience delays due to throttling. Also, you might get slower processing speeds compared to premium alternatives.
For businesses that require bulk document processing, free OCR APIs might not be the most efficient solution.
How to mitigate risks while using free OCR API
Free OCR APIs are great for basic tasks. But if your business depends on accuracy, security, and scalability, it’s worth considering these approaches to reduce risks while having the advantages of the free OCR APIs.
- Use hybrid approaches: Combine free and premium OCR APIs
- Preprocess images to improve accuracy
- Secure sensitive data before uploading
- Set up API request limits and failover plans
- Regularly evaluate API performance
Free OCR APIs can be useful for basic tasks, but when accuracy, security, and scalability become priorities, upgrading to a premium OCR API like Filestack is a smart investment.
If your business requires:
- High-volume processing without rate limits
- Better accuracy for complex documents
- Stronger security and data compliance
- Advanced features like AI-powered OCR and preprocessing
…then it’s worth transitioning to a premium solution for a seamless, risk-free OCR experience.
The role of Filestack in simplifying OCR data entry
Filestack offers free and paid subscription plans with different capabilities to choose from based on your requirements. Filestack OCR API offers a faster, more secure, and highly accurate solution for automating data entry and document processing.
Why should you choose Filestack OCR API?
✅ Higher Accuracy – AI-powered OCR ensures better text recognition, even for complex fonts and layouts.
✅ Strong Security – End-to-end encryption and GDPR/HIPAA compliance make it safe for handling sensitive data.
✅ Fast & Scalable – No rate limits, allowing bulk document processing without delays.
✅ Easy Integration – A developer-friendly API with simple implementation and multi-platform support.
Whether you’re automating invoice processing, form extraction, or AI-driven text analysis, Filestack streamlines OCR workflows with efficiency and reliability.
How to use Filestack OCR API in real-world applications
Here’s a full web-based OCR application using Filestack OCR API, HTML, CSS, and JavaScript. This app lets users upload a scanned report (image/PDF) and extracts the text into an editable format.
Features of This Web App:
- User-friendly interface with a modern design
- File upload support for scanned reports (images/PDFs)
- Filestack API integration for OCR text extraction
- Editable text output in a text area
HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>OCR Text Extractor</title>
<script src="https://static.filestackapi.com/filestack-js/3.x.x/filestack.min.js"></script>
<style>
/* Add CSS styling here */
</style>
</head>
<body>
<div class="container">
<h2>Upload a Scanned Report & Extract Text</h2>
<button onclick="uploadFile()">Upload File</button>
<div id="image-preview"></div>
<textarea id="text-output" placeholder="Extracted text will appear here..."></textarea>
</div>
<script>
window.onload = function() {
const filestackClient = filestack.init('YOUR_API_KEY'); // Replace with your Filestack API Key
window.uploadFile = function() {
filestackClient.picker({
accept: ['image/*', 'application/pdf'],
uploadInBackground: false, // Disable background upload if cropper is used
onUploadDone: (response) => {
const fileUrl = response.filesUploaded[0].url;
const fileHandle = response.filesUploaded[0].handle;
displayImage(fileUrl);
extractText(fileHandle);
}
}).open();
};
function displayImage(fileUrl) {
document.getElementById('image-preview').innerHTML =
`<img src="${fileUrl}" class="uploaded-image">`;
}
function extractText(fileHandle) {
const policy = 'YOUR_POLICY'; // Replace with your generated policy
const signature = 'YOUR_SIGNATURE'; // Replace with your generated signature
fetch(`https://cdn.filestackcontent.com/security=p:${policy},s:${signature}/ocr/${fileHandle}`)
.then(res => res.json())
.then(data => {
document.getElementById('text-output').value = data.text || 'No text detected.';
})
.catch(error => {
console.error('Error extracting text:', error);
document.getElementById('text-output').value = 'Error processing file.';
});
}
};
</script>
</body>
</html>Get the complete code from our GitHub repository.
How This Works:
- User clicks “Upload File” – Opens a Filestack file picker.
- User selects a scanned report (image/PDF) – The file is uploaded to Filestack.
- Filestack OCR API processes the file – Extracts text from the uploaded document.
- Extracted text appears in the text box – The user can edit or copy it.
Next Steps
- Replace ‘YOUR_API_KEY’ with your Filestack API key.
- Replace ‘YOUR_POLICY’ and ‘YOUR_SIGNATURE’ with the Filestack policy and signature generated programmatically or through the Filestack dashboard.
- Host this code on a local server or deploy it online.
- Customize the UI to fit your brand.
Output
When you run the script, it will display this initial screen in your browser.

It will show you the Filestack file picker when you click the ‘Upload File’ button. Then, you can choose an image or a PDF file for data extraction.
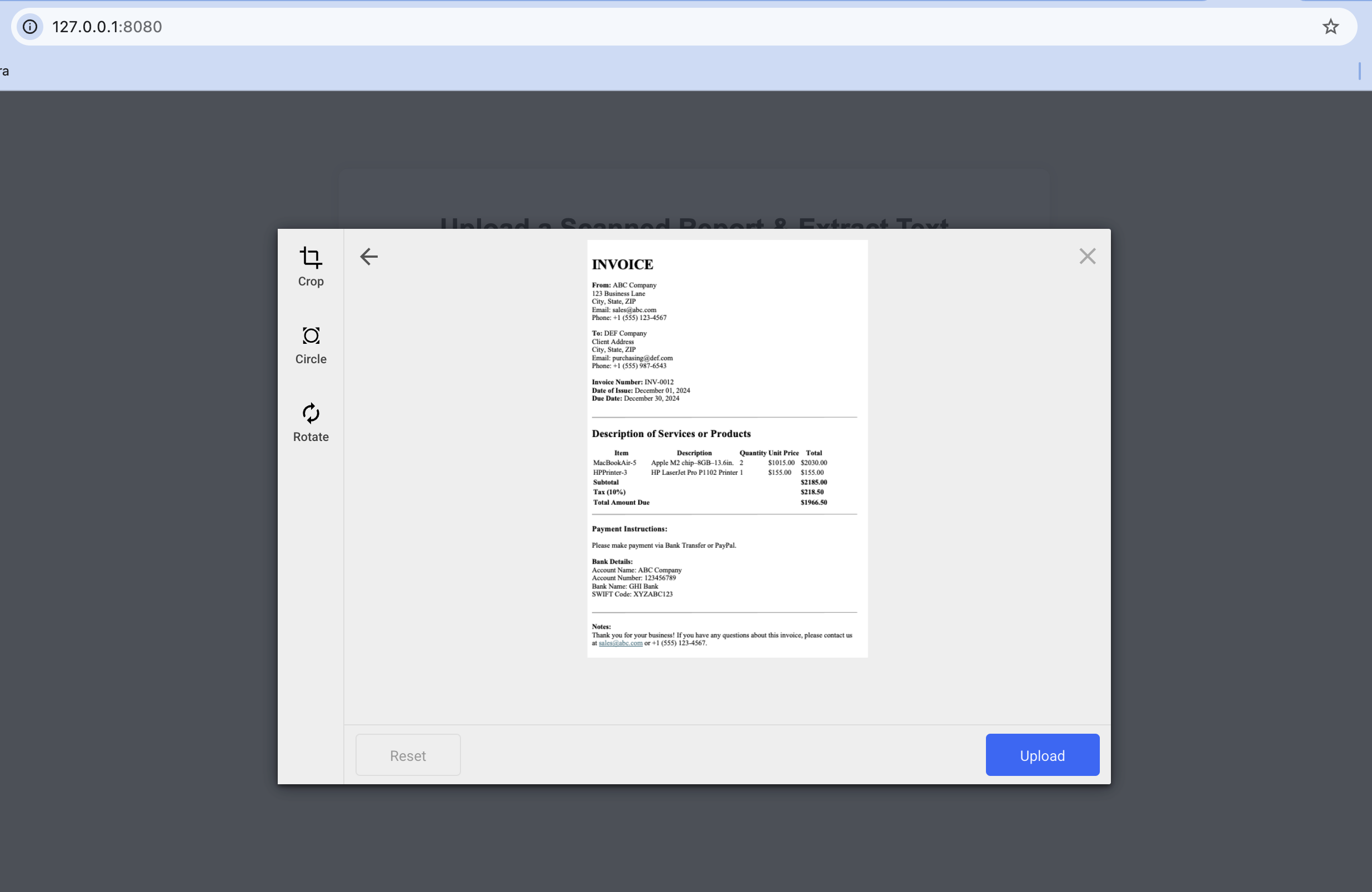
Then click ‘Upload’ and see the result. Filestack OCR API will extract text from your image or PDF file and show it in the editable text area below the uploaded image.
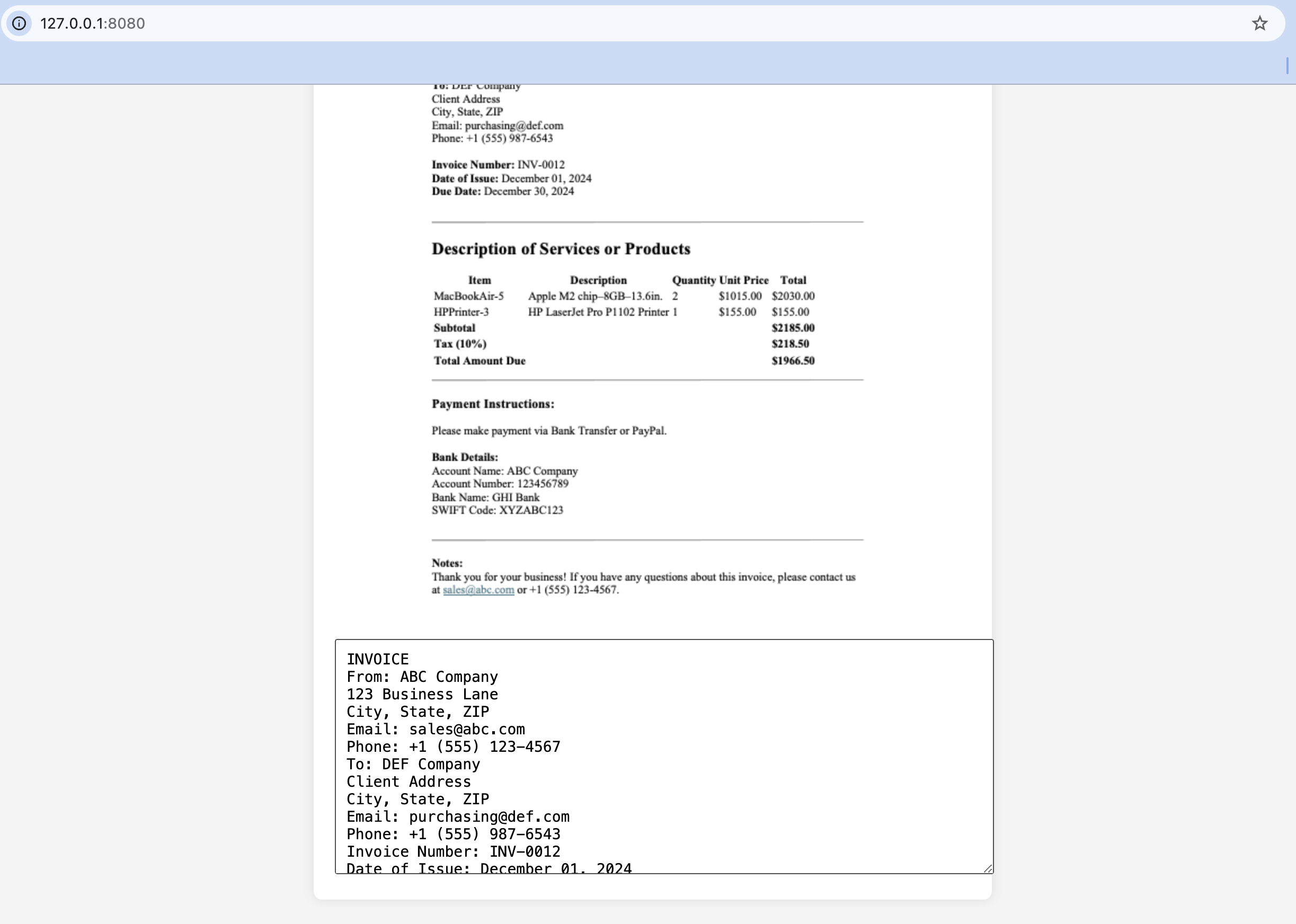
Conclusion
Free OCR APIs have revolutionized data entry by making text extraction faster, more accessible, and cost-effective. However, they come with limitations like accuracy issues, security risks, and processing constraints.
For businesses that need higher precision, security, and scalability, solutions like Filestack OCR API offer a powerful, AI-driven alternative with better accuracy, encryption, and seamless integration.
If you’re looking to streamline your data entry process, consider integrating OCR technology into your workflow. Whether you choose a free OCR API or a premium solution like Filestack, automation can save time, reduce errors, and boost efficiency.
Ready to transform your document processing? Explore OCR solutions today!

Shamal is a seasoned Software Consultant, Digital Marketing & SEO Strategist, and educator with extensive hands-on experience in the latest web technologies and development. He is also an accomplished blog orchestrator, author, and editor. Shamal holds an MBA from London Metropolitan University, a Graduate Diploma in IT from the British Computer Society, and a professional certification from the Australian Computer Society.
Read More →