
OCR data extraction technology has been around for quite some time. However, its potential is only just being realized. OCR has the ability to convert images of printed or handwritten text into digital text. Moreover, it can then be easily edited, searched, and analyzed. In the world of business operations, OCR and data extraction are revolutionizing the way data is handled.
With OCR and data extraction, businesses can save time and money. Moreover, it eliminates tedious manual data entry and allows them to access and utilize their data more efficiently. Filestack’s OCR data extraction is one such solution that enables businesses to take advantage of this technology and streamline their operations.
In this blog post, we will explore the benefits of OCR data extraction and how Filestack’s solution can help businesses of all sizes.

What Is OCR Data Extraction?
OCR (Optical Character Recognition) Data Extraction is a technology that enables machines to extract text from scanned documents, images, or other sources. Moreover, it also allows us to convert it into digital data. OCR technology involves an algorithm that uses pattern recognition software to identify each character in an image and convert it into a digital form.
This digital form can be processed by software applications and used for a variety of purposes, such as data analysis, indexing, and search.
Note that OCR and NLP(natural language processing) work together to extract textual data from image files.
Filestack – An Advanced OCR Data Extraction Software
Filestack’s advanced OCR technology goes beyond conventional OCR techniques by using artificial intelligence and machine learning. Furthermore, it can help to identify document patterns and accurately segment them into structured fields.
This means that the technology can recognize characters in an image and understand the context in which they appear. For example, it can identify different sections of a document, such as the title, author, date, and body text, and extract them as separate fields.
The following code can help you get an OCR response on your image using Filestack:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/ocr/<HANDLE>If you want to use it with document classification or detection, you can use the following URL:
ttps://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/doc_detection=coords:false,preprocess:true/ocr/<HANDLE>Use Filestack OCR with external URL:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL>Use Filestack OCR with storage Aliases:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/src://<STORAGE_ALIAS>/<PATH_TO_FILE>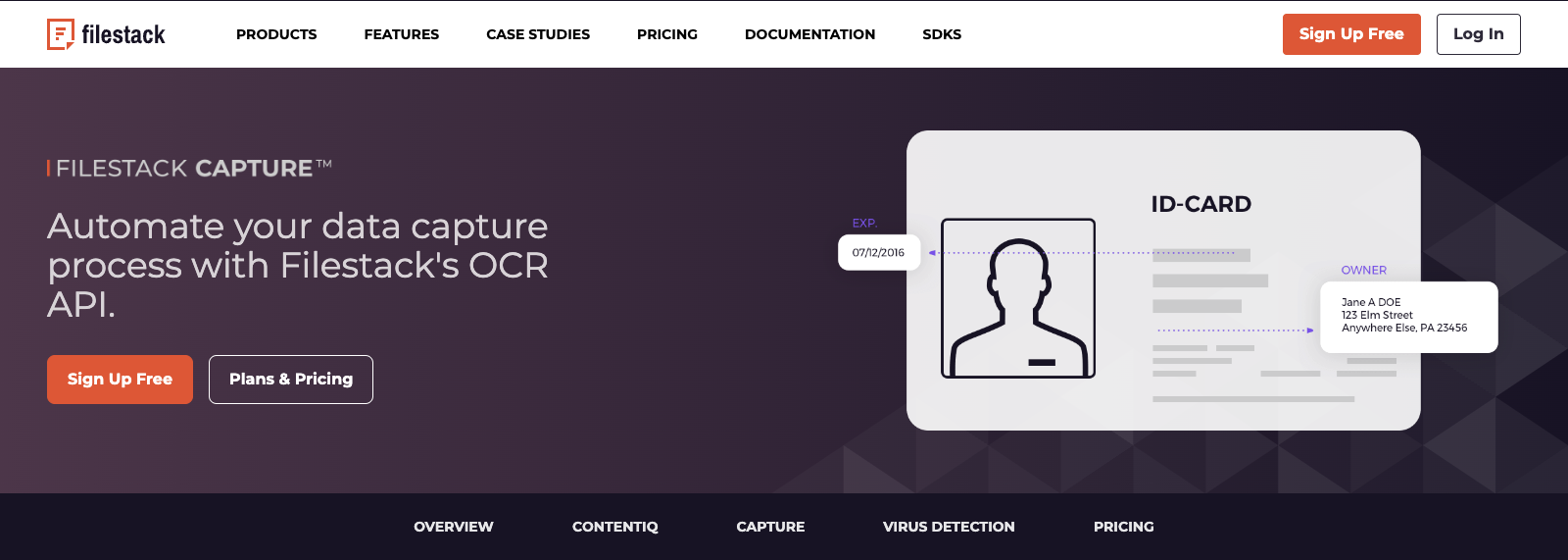
What Is the Importance of OCR in Document Management and Data Extraction, High-Accuracy Data?
If you are thinking about the importance of OCR in the mentioned field, here are five reasons to know:
- It can help you convert paper documents accurately and quickly into digital documents when extracting data.
- Recognizing text with high-accuracy results in high-quality data and reduced errors.
- The digitized documents are easily accessible across multiple platforms.
- You can save money that manual data extraction costs.
- You can easily track, store, and organize documents through OCR.
- It can give us reliable data insights to help us make informed decisions for our business.
What Is OCR Technology?
OCR (Optical Character Recognition) technology is a process that uses algorithms and pattern recognition software to recognize printed or handwritten characters in an image and convert them into a digital form. This data extraction pipeline converts physical documents, such as scanned paper documents or images, into searchable and editable digital files.
Furthermore, it can also help us detect key-value pairs, unstructured or structured data.

OCR Algorithms and Programming Languages
OCR algorithms and programming languages, such as Python and C++, are used to develop OCR software. Moreover, it can recognize and extract text from images. You can use the extracted data for multiple business documents.
Advancements in OCR Technology
The development of OCR technology has seen significant advancements in recent years. It includes the use of artificial intelligence and machine learning algorithms to perform data extraction on printed or handwritten documents.
OCR technology has a wide range of applications, including document scanning, automated data entry, and text recognition in images and videos. Moreover, it is a crucial tool for digitizing paper-based records, enabling businesses to process and manage large volumes of data more efficiently.
What Is OCR Data Extraction Process?
The OCR data extraction work processes in a few simple steps when performing data extraction. Here are those steps:
Steps Involved in OCR Data Extraction
Inputting Data
The first step in OCR data extraction is to input the image or scanned document into the OCR software. This can be done using a scanner or by uploading the image file to the software.
Pre-processing Image
Before the text in the image can be recognized, the image needs to be pre-processed to enhance its quality. This involves removing any noise or distortion, adjusting contrast and brightness, and correcting any skew or orientation issues.
Text Recognition
The OCR software then uses optical character recognition (OCR) technology to recognize the text in the image. Moreover, the software identifies individual characters and groups them together to form words and sentences.
Data Parsing and Extraction
Once the text is recognized, the software parses the text to identify specific data fields such as names, addresses, and phone numbers.
Post-processing and Validation
The extracted data is then validated against predefined rules and standards to ensure accuracy. Finally, the data can be exported to other applications or databases for further analysis and processing.
Role of Machine Learning in the OCR Data Extraction Process
Machine learning plays a significant role in the OCR data extraction process by improving the accuracy and efficiency of the system. By training the OCR software with machine learning algorithms, the software can learn to recognize and extract data with higher accuracy.
Hence, resulting in improved data quality and reduced manual effort. Machine learning also allows for continuous improvement and adaptation to new data sets, making the OCR system more efficient over time.
What Is Data Extraction Accuracy?
Data extraction accuracy refers to the level of correctness and precision in extracting specific data from a given source. Here are some factors that affect OCR data extraction accuracy.
Factors Affecting OCR Data Extraction Accuracy
Quality of Input Document
The quality of the input document can affect OCR accuracy. Factors such as document age, paper quality, ink quality, and smudges can affect OCR accuracy, as the software may have difficulty recognizing the text on the document.
OCR Software Used
Different OCR software may have different levels of accuracy and performance. Furthermore, some OCR software may be better suited for specific document types or languages. And choosing the appropriate software can impact the accuracy of the data extraction process.
Language and Font
The language and font used in the document can affect OCR accuracy. Therefore, complex languages with unique characters and symbols or fonts with low contrast or unusual spacing can make recognizing the text difficult for the software.
Formatting and Layout of the Document
The formatting and layout of the document also play a role in determining accuracy. Tables, charts, and images can be challenging for OCR software. Moreover, it may require additional processing to extract data accurately.
Note that the columns and headers of your documents can also impact the accuracy.
Techniques for Improving OCR Data Extraction Accuracy
We have listed the two most common ways to improve OCR data extraction accuracy. Let’s explore them:
Correction and Verification
In this technique, we verify the document output that current the errors. Note that we can achieve it using a software tool or manual checking.
Quality Assurance
It involves selecting the appropriate OCR software, using high-quality input documents, and optimizing layout and formatting. The interesting part to know here is that it also involves training OCR software by using machine learning. However, we can also use pre-built models for this purpose.
What Are OCR Data Extraction Applications?
Since we know the importance of OCR data capture, we must know it has several applications. Some most common applications are listed below:
- Accounting and Finance
- Healthcare
- Law Enforcement
- Retail and E-commerce
- Government and Bureaucracy

What Are Future Trends and Developments In OCR Data Extraction?
Here are some future trends and developments in OCR data extraction.
Potential Advancements in Filestack OCR Data Extraction Technology
Filestack OCR data extraction technology is expected to continue to evolve, with advancements in OCR algorithms and machine learning models.
Improved Accuracy and Speed
Advancements and machine learning and computer vision techniques will play a huge role in this case. Therefore, the accuracy and speed of OCR data extraction will enhance accordingly.
Integration With Other Software and Systems
OCR technology is expected to become more integrated with other software and systems, such as document management systems, enterprise resource planning systems, and customer relationship management systems. Moreover, this integration will enable seamless data extraction and processing across different platforms.
Introduction of AI and Machine Learning
AI and machine learning are expected to play an increasingly important role in OCR data extraction. Moreover, the OCR software will be able to learn from previous data extraction tasks, improving accuracy and reducing errors.
Impact of OCR Data Extraction on Document Management and Big Data Analysis
OCR data extraction has had a significant impact on document management and big data analysis. Here are some ways in which OCR data extraction has impacted these areas:
- Improved Efficiency
- Increased Accuracy
- Data Standardization
- Access to Unstructured Data

Final Thoughts
OCR data extraction is transforming the way businesses process and analyze data. The accuracy and efficiency of OCR technology are expected to continue to improve, with advancements in machine learning, computer vision, and integration with other systems.
As businesses generate more data, OCR technology will become increasingly important in enabling organizations to process and analyze large volumes of information quickly and accurately. In the future, OCR data extraction will likely become an essential tool for businesses looking to streamline their operations and gain a competitive edge.
FAQs
What Is Data OCR?
There is no specific term for “data OCR.” However, OCR (Optical Character Recognition) refers to the technology that enables the conversion of scanned images, PDFs, or other types of documents into searchable and editable formats.
How Do I Extract Data From a PDF in OCR?
You can use a software for this purpose.
Can You Extract Data From a Scanned Document?
Yes, it is possible to extract data from a scanned document using OCR (Optical Character Recognition) technology.
How to Extract Text From an Image Using OCR?
To extract text from an image using OCR (Optical Character Recognition) technology, you can follow these steps:
- Choose an OCR software
- Import the image
- Start OCR
- Check and edit
- Save the extracted text
Ayesha Zahra is a Geo Informatics Engineer with hands-on experience in web development (both frontend & backend). Also, she is a technical writer, a passionate programmer, and a video editor. She is always looking for opportunities to excel in her skills & build a strong career.
Read More →