
Object localization and object detection are computer vision techniques that automatically detect objects in images and videos and also pinpoint their location. These techniques are used in autonomous vehicles for identifying objects, such as other vehicles, people, and road signs. An object recognition API is also used for security and surveillance (detecting intruders) and medical imaging (identifying tumors). While object localization and detection are quite similar, there are slight differences between them.
In this article, we’ll discuss key differences between object localization and object detection and the key concepts related to these techniques.
Key Takeaways
- Object localization identifies a single object in an image and provides its location using a bounding box.
- Object detection goes further by identifying and classifying multiple objects, assigning labels and bounding boxes to each.
- The main difference lies in scope—localization handles one object, while detection handles many, often using CNNs for classification.
- These techniques are widely used in autonomous vehicles, retail, healthcare, and security applications.
- Neural networks, especially CNNs, power these systems by extracting image features, predicting object locations, and assigning class labels.
- Filestack’s AI tagging feature integrates object detection/localization to automate image tagging for faster content management.
Before we discuss the differences between object localization and object detection, it’s better to understand the key concepts related to these techniques. These include:
Image classification
Image classification assigns a label to an entire image based on its content. The purpose is to determine what category the image belongs to.
Object classification
Object classification identifies and classifies individual objects within an image. It involves detecting objects and assigning labels to them, such as cat, dog, car, and people. Object classification differs from object localization in that it only assigns labels to objects – it doesn’t pinpoint their location.
Object classification helps autonomous cars recognize objects like cars and pedestrians. It is also used in medical imaging to detect multiple tumors.
Bounding Box
A bounding box is basically a rectangular box that object localization or detection tools draw around the detected object. The purpose of the bounding box is to locate the position of the object within an image.
By drawing bounding boxes around multiple objects, object detection tools determine the position of multiple objects within an image. On the other hand, object localization draws a bounding box around a single object.
Object detection algorithms
Common object detection algorithms include YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector), and R-CNN (Region-based Convolutional Neural Networks).
YOLO is known for its fast and real-time object detection, but it’s not very accurate for small objects. SSD works well for both small and large objects, but it’s not as accurate for complex images with overlapping objects. R-CNN provides highly accurate results even for complex images, but it is computationally expensive.
Computer vision
Object detection and localization are fundamental to many computer vision applications. They enhance the system’s ability to understand and interact with images. These techniques are used in autonomous vehicles to detect other vehicles and people, in medical imaging to detect tumors, and in inventory management and automated checkout systems.
Machine learning
Machine learning is the key technique used for image detection and localization. Most object detection tasks are supervised. This means the ML model learns from labeled datasets with images containing objects.
Neural network
Neural networks and deep learning are basically subsets of machine learning. Most modern object detection tools utilize Convolutional Neural Networks (CNNs) to detect and classify objects. CNNs are known for their efficient feature extraction. They automatically extract features from images. This helps the model learn to recognize complex patterns and objects.
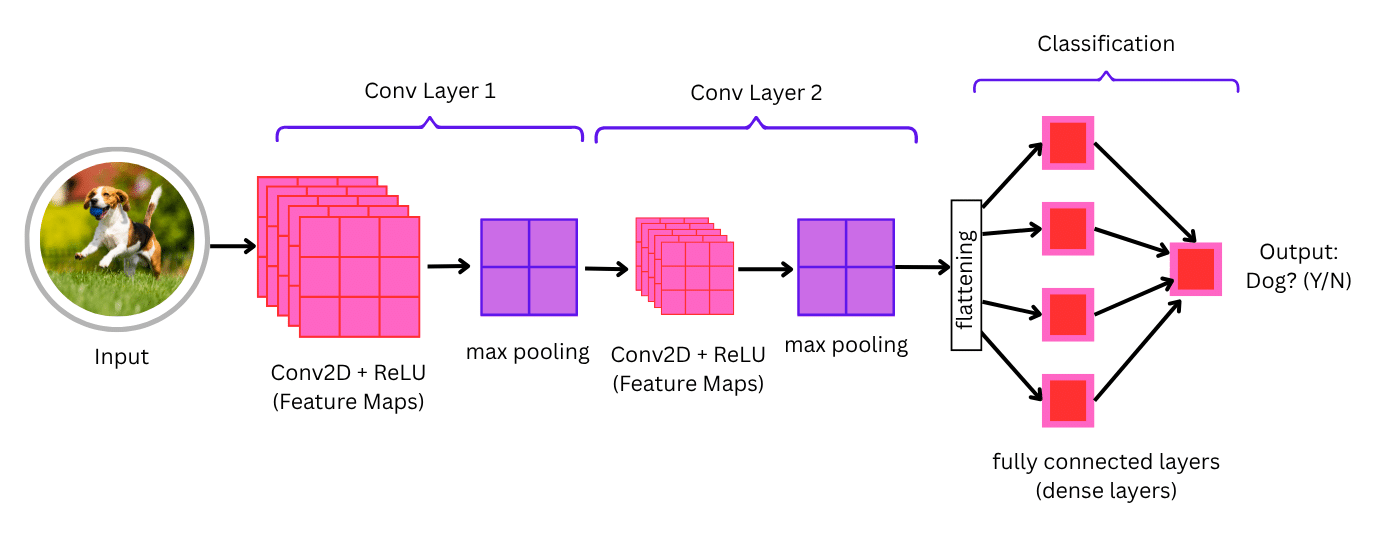
How neural networks process images for object detection
Neural networks—specifically Convolutional Neural Networks (CNNs)—are at the heart of most modern object detection systems. Here’s a simplified breakdown of how they process images:
- Input layer:
The input image (typically in RGB format) is converted into a matrix of pixel values and fed into the neural network. - Convolutional layers:
These layers apply filters (also called kernels) that scan the image to extract features like edges, textures, shapes, and colors. Each filter detects a specific pattern in the image. The result is a feature map representing those patterns. - Activation function (ReLU):
The Rectified Linear Unit (ReLU) introduces non-linearity to the network, helping it learn complex patterns beyond simple lines or curves. - Pooling layers:
Pooling reduces the spatial size of the feature maps (downsampling), which helps reduce computation and overfitting. Max pooling is commonly used—it selects the most important features by picking the maximum value in a given region. - Fully connected layers:
After several rounds of convolution and pooling, the network flattens the feature maps and feeds them into one or more fully connected layers to interpret the learned features. - Bounding box and classification output:
In object detection, the network outputs:- The coordinates of bounding boxes (usually in the format [x, y, width, height])
- The class labels of detected objects (e.g., “car,” “dog,” “person”)
- A confidence score that reflects how likely the prediction is correct
- Loss function & backpropagation:
During training, the model compares its predictions with ground truth labels using a loss function (e.g., Intersection over Union (IoU) loss + classification loss). It then adjusts its internal weights using backpropagation to improve accuracy.
Modern object detection models like YOLO (You Only Look Once), SSD (Single Shot Multibox Detector), and Faster R-CNN build on these principles with specialized architectures that allow for real-time detection or higher accuracy depending on the use case.
What is object localization?
Object localization is a technique that automatically detects and pinpoints the location of a single object in an image or video. When it detects an object, it creates a bounding box around it, allowing us to see the location of the object. For example, if an object localization tool localizes a dog in an image, it will create a bounding box around it.
The following values usually define the bounding box:
- Coordinates of the top-left corner
- The horizontal and vertical span of the object.
An object localization tool first preprocesses the image to improve its quality. It then uses regression models to extract features like edges and shapes. Finally, it creates a bounding box around the detected object. These tools typically don’t classify the detected object.
What is object detection?
Object detection is also a computer vision technique that identifies multiple objects in an image or video. It creates a bounding box around each detected object, determining their location. It goes beyond object localization by not only detecting multiple objects but also classifying them.
Object classification essentially means assigning relevant class labels to detected objects such as cats, dogs, people, and cars. This is usually done using CNNs or pre-trained models like ResNet. Object detection tools also provide a confidence score for each classified object.
The confidence tool shows how confident the tool/model is that the detected object belongs to a certain class. For example, the tool could provide a confidence score of 90% for a detected cat but a 50% score for a person in the same image.
When to choose object localization vs object detection
Choosing between object localization and object detection depends on the complexity of the task, number of objects, and use case requirements:
- Use object localization when:
- You need to detect only one object per image (e.g., a face on an ID card or a single tumor in a scan).
- You don’t require classification—just the location of an object.
- You need a lightweight and fast solution for simple tasks with minimal computing power.
- Your application must run in real-time with low latency and doesn’t involve multiple overlapping objects.
- Use object detection when:
- You need to detect and classify multiple objects within the same image or video frame.
- The system must handle diverse or crowded scenes (e.g., traffic monitoring, retail shelf scanning, or group surveillance).
- You require accurate object categorization (like differentiating between pedestrians, vehicles, and road signs).
- You’re building AI-powered tagging tools or applications that automate content analysis at scale.
In summary, use localization for focused tasks that prioritize speed and simplicity, and detection for complex scenarios requiring multi-object awareness and classification.
Object localization vs Object detection
The table below shows the key differences between object localization vs object detection:
| Object localization | Object detection | |
| Functionality | Detects a single object within an image or video | Detects multiple objects within an image or video |
| Object classification | Doesn’t typically classify the detected object | Classifies the detected objects by assigning class labels to them |
| Output | Creates a bounding box around the detected object. | Returns bounding boxes and class labels for all the objects. |
| Complexity | Simpler than object detection as it focuses only on a single object | More complex as it handles multiple objects |
| Algorithm | Uses regression models to predict object location | Uses CNN-based models to detect and classify multiple objects |
| Processing time | Faster, as it handles only one object | Slower, as it processes multiple objects. |
| Use cases |
|
|
Object recognition and detection with Filestack
Filestack offers advanced image processing capabilities by utilizing object detection and localization. Its efficient AI image tagging provides accurate tags for multiple objects present in an image. Thus, it allows users to automatically classify images and manage them efficiently.
Filestack leverages neural networks and deep learning to automatically generate accurate tags for objects within an image. It supports various categories, such as animals, people, and transportation.
Example code
Here is an example code to implement Filestack auto image tagging:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Image Upload and Tagging</title>
<script src="https://static.filestackapi.com/v3/filestack.js"></script>
<style>
/* CSS Styling goes here */
</style>
</head>
<body>
<div class="container">
<h2>Image Upload and Tagging</h2>
<button id="uploadBtn">Upload Image</button>
<img id="uploadedImage" style="display: none;" alt="Uploaded Image">
<h3>Image Tags:</h3>
<p id="tags"></p>
</div>
<script>
// Replace with your Filestack API key, policy, and signature
const apiKey = 'YOUR_API_KEY';
const policy = 'YOUR_POLICY';
const signature = 'YOUR_SIGNATURE';
// Initialize Filestack client
const client = filestack.init(apiKey);
// Add click event listener to the upload button
document.getElementById('uploadBtn').addEventListener('click', () => {
client.pick()
.then(result => {
// Get the handle and URL of the uploaded file
const handle = result.filesUploaded[0].handle;
const imageUrl = result.filesUploaded[0].url;
// Display the uploaded image
const uploadedImageElement = document.getElementById('uploadedImage');
uploadedImageElement.src = imageUrl;
uploadedImageElement.style.display = 'block';
// Construct the URL to fetch tags
const tagsUrl = `https://cdn.filestackcontent.com/security=p:${policy},s:${signature}/tags/${handle}`;
// Fetch the tags for the uploaded image
fetch(tagsUrl)
.then(response => response.text())
.then(text => {
console.log('Response:', text); // Debug the raw response
const data = JSON.parse(text);
// Check if tags exist and display them
if (data.tags && data.tags.auto) {
const tagNames = Object.keys(data.tags.auto);
const tags = tagNames.join(', ');
document.getElementById('tags').textContent = tags;
} else {
document.getElementById('tags').textContent = 'No tags found for this image.';
}
})
.catch(error => {
console.error('Error fetching tags:', error);
document.getElementById('tags').textContent = 'Error fetching tags.';
});
})
.catch(error => {
console.error('File upload error:', error);
document.getElementById('tags').textContent = 'Error uploading image.';
});
});
</script>
</body>
</html>You can get the complete code from our GitHub repository.
Output
The code above will display the following screen:
When you click the ‘upload’ button, Filesack File Picker will appear. You can use it to upload the image for which you want to generate tags.
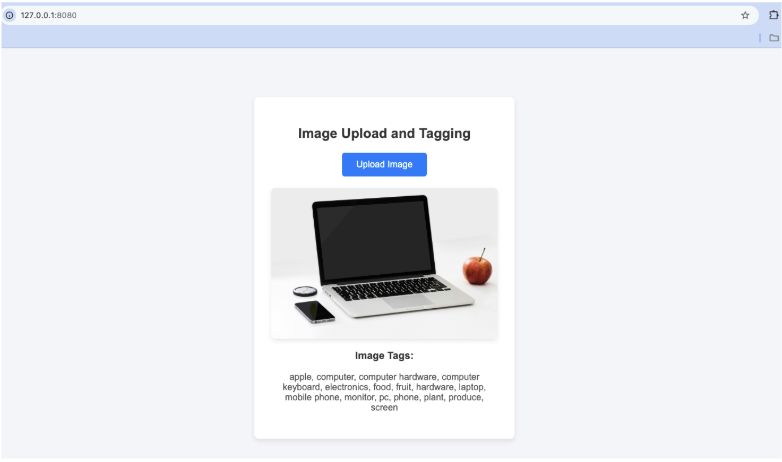
Once you upload the image, it’ll generate relevant tags:
Conclusion
Object localization and object detection are both computer vision that involves detecting the position of an object/objects within an image. The key difference between these techniques is that object localization detects a single image, while object detection detects multiple objects. Object detection also provides labels for the detected objects.
Object localization can be used for:
- Detecting a single face in an ID photo
- Identifying a single tumor in an MRI scan
- Find the position of a pedestrian in an autonomous vehicle
- Locating a barcode on a product
Object detection can be used for:
- Detecting multiple faces in a group photo
- Identifying multiple tumors in an MRI scan
- Detecting pedestrians and cars in real time
- Detecting multiple products on store shelves
Sign up for free at Filestack and generate highly accurate tags for your images!
FAQs
What is the difference between object detection and localization?
Object localization detects a single object in an image, whereas object detection detects multiple objects in an image. Object detection also classifies objects by assigning them labels.
What is the difference between object detection and object tracking?
Object Detection identifies and locates objects in a single image or video. In contrast, object tracking follows a detected object across multiple frames in a video.
What are the use cases of object localization and object detection?
Automotive, retail, and healthcare industries use these techniques for tasks like detecting other vehicles and pedestrians in autonomous vehicles, detecting multiple products on store shelves, and detecting multiple tumors.
Sidra is an experienced technical writer with a solid understanding of web development, APIs, AI, IoT, and related technologies. She is always eager to learn new skills and technologies.
Read More →