Framing and composition are fundamental in any kind of photography and imagery. As is the case for many art forms, there are multiple levels of perfection that you can aim for when dealing with those concepts. Images come in an endless variety of dimensions and aspect ratios, making smart image cropping important for faster, more performant, more user-friendly and visually appealing applications.
If you are working on web applications, where you have to manage large quantities of user-generated content, there’s a high chance that you can’t afford to have a design team go through all of the images and adjust framing and shapes of all so that they fit in your application nicely. If you’re building something similar to an Instagram, it is possible to make users take care of cropping, but if this is out of the question or you want to make your application more user friendly, you can get the job done with software.
Let’s say you want to crop an image to the dimensions of 500×200. If the algorithm in your software is not content aware in some way, the results you get will be far from optimal as illustrated in this example:

Input image (source)

Output – 500×200 – NOT smart crop
So how do you build a smart crop that highlights the best or most important parts of an image?
Face detection comes to mind, but will not work in images where no faces are present. We need a model that works regardless of the content contained within the image. We propose a set of methods that will allow you to programmatically manipulate your images in a way that provides a version of the image that is exactly the shape and dimensions you want, while keeping the correct aspect ratio and cutting out the least interesting fragments of the input image.
The distribution of interesting information present on an image is often called a “saliency map”. Applying our method to the example input image yields the following saliency map:
Input image
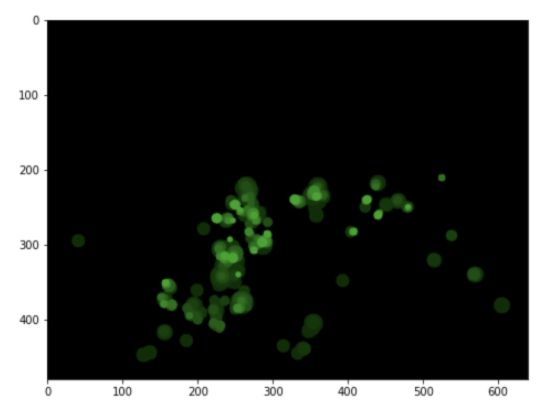
Input saliency map
The saliency of an image is not a well defined property, and by its nature can be very subjective. Due to this subjective nature, there are many different methods and no great way to measure performance. On one hand, this offers more flexibility in terms of computational requirements and runtime, but there is no clear winner. For more on saliency, check out this research for a review of “non-differentiable” methods or how social media giant Twitter attacked this problem with the full might of deep learning.
Enter Filestack Smart Crop
Calculating the saliency map is the first step in the process of automated image cropping or trimming. Assuming that you have a target width and height for your output image, you will need to somehow squeeze the region of interest into that shape. At Filestack, we tried many different methods and found the most satisfying results when using the Jaccard index, also known as “intersection over union” to detect a bounding box that covers the salient features of the image most efficiently.
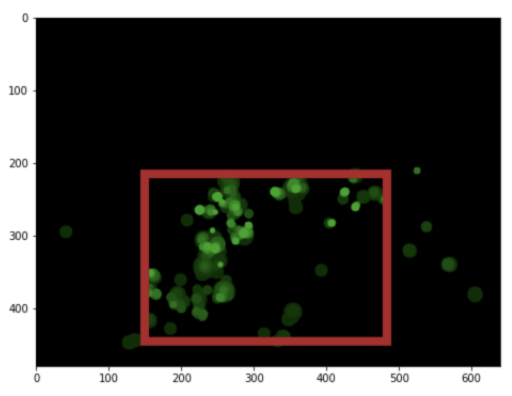
Maximum saliency bounding box

Maximum saliency image crop
The dimensions of the output image so far are arbitrary and depend on the saliency detection and bounding box finding algorithm. Using what we developed for Filestack Smart Crop, it is easy to extend the output to any dimensions. Applying this algorithm to the desired dimensions of 500×200 in the example that we started with, here’s the resulting output:
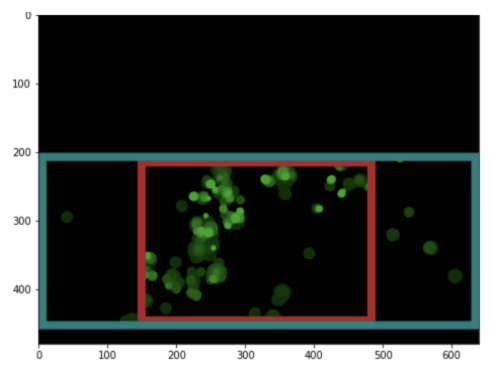
Desired output dimensions overlay for saliency crop box

Output – 500×200 – saliency box smart crop
And that’s it! A quick way to add smart image cropping to your Filestack based application. To get started, simply follow our documentation: https://www.filestack.com/docs
More examples of Filestack Smart Crop

Original

Smart Cropped

Original

Smart Cropped
Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.
Read More →