Last month, Filestack sponsored an AI meetup wherein I presented a brief introduction to reinforcement learning and evolutionary strategies. Beforehand, I had promised code examples showing how to beat Atari games using PyTorch. In reality, I did not have time for that kind of side project and so I found some other examples of training agents to play Flappy Bird using Keras, which were entertaining but not complete enough for me to recommend as a springboard for further exploration.
Luckily, I recently found some time to develop the promised training scripts. Therefore, I would like to provide an in-depth look of how we can use the PyTorch-ES suite for training reinforcement agents in a variety of environments, including Atari games and OpenAI Gym simulations.
Understanding Evolutionary Strategies
In deep reinforcement learning that uses the Q-learning algorithm, which has become very popular, training an intelligent agent includes distinct phases for “observation” and “learning”. During both, there can be pre-determined statistical strategies for “exploration”, which essentially means picking random actions with some probability (in lieu of the agent making its own prediction) in order to accidentally stumble upon optimal solutions, mimicking the way curiosity and stochasticity drive organic life to learn about its environment. These phase distinctions are necessary because Q-learning reinforcement agents get better via backpropogation, which is a complex form of parameter updating involving calculus, and one that needs to know how each recorded action affects the overall outcome of each episode. Essentially, to train the agent, you must first collect “replay memories” from many, many episodes before learning can even begin.
This is obviously not an optimal solution for real-time learning. Animals do not often have the luxury to sit back and “observe” themselves succeed and fail before going back through their memories and getting feedback at their convenience. Success and failure in real life often translate to immediate rewards or immediate consequences, which are used for immediate neuronal feedback. Reacting to these signals summarily could be the difference between success and failure, life and death, passing on your genes or losing them to time.
Finding a reinforcement strategy that harnesses the power of deep learning without being hamstrung by the requirements of backpropogation has been an active area of research. Last year, OpenAI decided to dig a bit into the past and rediscover evolutionary strategies, a form of reinforcement learning invented decades ago that uses dozens, hundreds or thousands of individual agents to simulate a “survival of the fittest” game. In these strategies, similar in some ways to genetic algorithms, a model is created and initialized with a set of parameters. Clones of the model are then sent out as a “population”, with each member receiving a slightly different version of the original weights (typically modified by adding Guassian noise of varying intensities).
The addition of noise acts as a means of “exploration”: by randomly altering the original parameters, each clone will react slightly differently to the same stimuli, for the worse or for the better. The clones each run through a training episode completely ignorate of each other, and report back with the rewards they earned (or didn’t earn). Those rewards are collected, normalized and summed, and used to create a “best version” of the population weights by intensifying those which performed well and suppressing those that did not. This is then used to update the original parameters, ideally by nudging it slightly in the direction of higher rewards. The process is repeated, with the mother parameters cloned, jittered, and updated over and over, until the agent “solves” the given environment.
In this, we achieve a similar outcome to reinforcement learning via backpropogation, namely an ideal, generalized set of weights for a specific problem, but without any backpropogation at all. This is why OpenAI included “scalable” in the paper for their algorithm: by eschewing backpropagation, evolutionary strategies can be highly parallelized with less memory footprint.
OpenAI’s blogpost on their algorithm included an example showing how “simple” it could be:
[code lang=”python”]
# simple example: minimize a quadratic around some solution point
import numpy as np
solution = np.array([0.5, 0.1, -0.3])
def f(w): return -np.sum((w – solution)**2)
npop = 50 # population size
sigma = 0.1 # noise standard deviation
alpha = 0.001 # learning rate
w = np.random.randn(3) # initial guess
for i in range(300):
N = np.random.randn(npop, 3)
R = np.zeros(npop)
for j in range(npop):
w_try = w + sigma*N[j]
R[j] = f(w_try)
A = (R – np.mean(R)) / np.std(R)
w = w + alpha/(npop*sigma) * np.dot(N.T, A)
[/code]
Playing Atari Games
To translate the algorithm above into something we can use to play Atari games, we move from numpy arrays to PyTorch tensors. First, we need to create a model that can take in environment observations. Since we will be beating Space Invaders, whose observations come in the form of screen buffers, we will use a deconvolution architecture to process our predictions:
[code lang=”python”]
cuda = args.cuda and torch.cuda.is_available()
num_features = 16
transform = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor()
])
class InvadersModel(nn.Module):
def __init__(self, num_features):
super(InvadersModel, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, num_features, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_features, num_features * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(num_features * 2),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_features * 2, num_features * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(num_features * 4),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_features * 4, num_features * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(num_features * 8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_features * 8, num_features * 16, 4, 2, 1, bias=False),
nn.BatchNorm2d(num_features * 16),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(num_features * 16, 6, 4, 1, 0, bias=False),
nn.Softmax(1)
)
def forward(self, input):
main = self.main(input)
return main
model = InvadersModel(num_features)
if cuda:
model = model.cuda()
[/code]
PyTorch-ES takes in a list of PyTorch variables, as well as a function to generate rewards. This function should accept an argument for the cloned weights (mine also takes in the model, which I will come back to in a moment), run the episode in question, and return the total reward:
[code language=”python”]
def get_reward(weights, model, render=False):
cloned_model = copy.deepcopy(model)
for i, param in enumerate(cloned_model.parameters()):
try:
param.data = weights[i]
except:
param.data = weights[i].data
env = gym.make("SpaceInvaders-v0")
ob = env.reset()
done = False
total_reward = 0
while not done:
if render:
env.render()
image = transform(Image.fromarray(ob))
image = image.unsqueeze(0)
if cuda:
image = image.cuda()
prediction = cloned_model(Variable(image, volatile=True))
action = np.argmax(prediction.data)
ob, reward, done, _ = env.step(action)
total_reward += reward
env.close()
return total_reward
[/code]
In the above function, I am passing in the model (the model could also be created anew inside each function — this is to ensure we are dealing with a model object with unique memory so our multithreaded processes aren’t competing) and the cloned weights. Before running everything, the model is copied and the new weights are loaded. Then we run the episode, similar to how we would in an exploration phase in deep Q-learning, and return the reward. This is run for each cloned model and the returned reward is what we use to understand their successes and failures.
Finally, we load up the EvolutionModule, which takes in a few arguments:
[code language=”python”]
partial_func = partial(get_reward, model=model)
mother_parameters = list(model.parameters())
es = EvolutionModule(
mother_parameters, partial_func, population_size=50,
sigma=0.3, learning_rate=0.001,
reward_goal=200, consecutive_goal_stopping=20,
threadcount=15, cuda=cuda, render_test=True
)
start = time.time()
final_weights = es.run(10000, print_step=10)
end = time.time() – start
pickle.dump(final_weights, open(os.path.abspath(args.weights_path), ‘wb’))
final_reward = partial_func(final_weights, render=True)
print(f’Reward from final weights: {final_reward}’)
print(f’Time to completion: {end}’)
[/code]
Running this, over the course of hundreds of iterations, we eventually end up with an agent that can fare decently in Space Invaders:
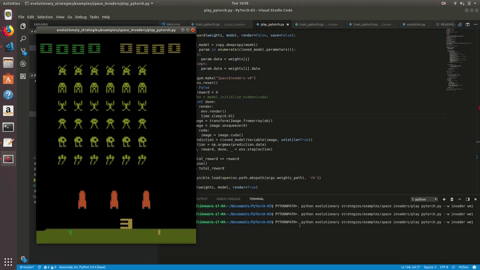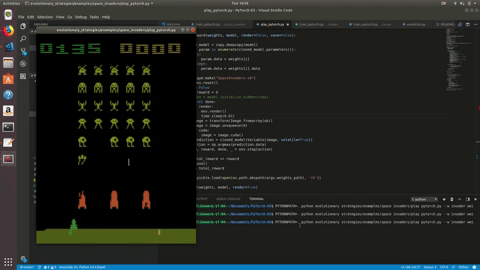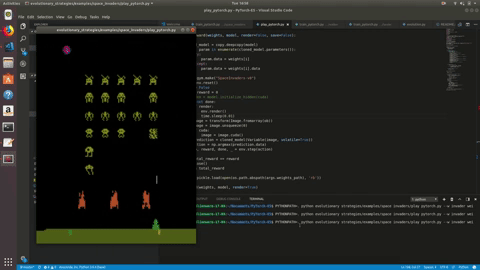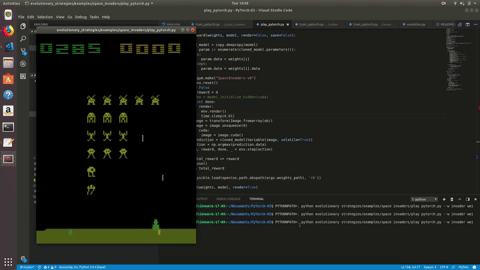
However, it seems to learn to jolt over to the far right of the screen, which may be the best strategy but it seems like this can be improved with better design of the model and playing around with different numbers for the sigma, learning rate and population size. Using images also means models with more parameters, and thus longer training times, so it may just be a matter of finding the right training duration. The Atari environment is also unfortunately not threadsafe, whereas other Gym environments can be safely run in multiple processes at a time. You can see the source code for the Space Invaders agent here, and I encourage you to run through some of the many environments offered, using different hyperparameters and testing out different kinds of PyTorch architectures. Please also feel free to make a PR if you see ways to improve or optimize the ES algorithm.
Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.
Read More →