
Optical Character Recognition technology is widely used today. This is for converting images of text into editable and searchable data. It is used to digitize documents and extract vital information from forms. OCR data extraction plays a major role in modern data management strategies. When integrated with Angular applications, OCR capabilities offer a range of benefits. These improve scalability and efficiency. Using OCR, applications can be made to easily parse and interpret text from images. In this article, we’ll discuss how OCR data extraction can enhance Angular apps. We’ll also share practical insights and highlight the transformative potential of this integration. We’ll also highlight the integration’s revolutionary potential and offer some useful observations.
Benefits of OCR in Angular applications
Integrating OCR into Angular applications offers many benefits. These benefits can improve efficiency and scalability across various domains. We will discuss some of them below.
Process automation
OCR facilitates process automation by reducing the need for manual data entry. This simplifies the work and frees up valuable human resources. Angular apps can easily integrate OCR to extract text from images. This allows the apps to fill out forms. Also, it allows them to update databases and trigger specific actions. This results in smooth operations and faster turnaround times.
Document digitization
OCR has the capability to digitize documents within Angular applications. It will change the way organizations manage their archives. Angular apps with OCR capabilities convert scanned documents and images into editable text. Users can quickly locate and retrieve relevant information. This can reduce the inefficiencies associated with manual document handling. It improves accessibility and promotes collaboration and knowledge sharing across teams.
Data insights
Finally, the integration of OCR into Angular applications can provide some valuable information. This is a result of extracting meaningful information from images. OCR-equipped Angular apps can extract product details from invoices. They can also capture customer information from identity documents. Additionally, they can analyze handwritten notes. These apps process and analyze textual content with high accuracy. Therefore, companies use these apps to get useful information from untapped data sources. Also, it encourages creativity and helps make decisions based on data.
Choosing an OCR library or API
When choosing an OCR library, several critical factors have to be considered. This is to ensure optimal performance and compatibility. Firstly, consider accuracy. Check the OCR library or API’s ability to recognize text across various image types and qualities. Additionally, check the supported languages. This is to ensure compatibility with the requirements of your application’s user base.
Ease of integration is another consideration. Look for libraries that offer straightforward integration with Angular frameworks. They should have clear instructions and strong support for TypeScript. TypeScript is the preferred language for Angular development. Below is a code snippet used to integrate the Tesseract library into an Angular-based component.
@Component({
selector: 'app-ocr',
templateUrl: './ocr.component.html',
styleUrls: ['./ocr.component.css']
})
export class OcrComponent {
extractedText: string = '';
constructor() { }
async performOCR(imageFile: File) {
const result = await Tesseract.recognize(
imageFile,
'eng',
{ logger: m => console.log(m) }
);
this.extractedText = result.data.text;
}
}Scalability is also important, especially for applications expecting increased usage over time. Ensure that the chosen OCR solution can scale easily. This is to accommodate growing demands without sacrificing performance.
Cost is also a significant factor in the decision-making process. Certain open-source OCR libraries like Tesseract.js offer cost-effective options. However, cloud-based OCR solutions like Filestack provide high accuracy and automatic scaling. They also give a broader range of image processing features. Filestack’s APIs and SDKs easily integrate with Angular applications using TypeScript. They offer a reliable and scalable solution for OCR data extraction workflows. Additionally, cloud-based solutions often reduce the burden of infrastructure maintenance. They provide convenient pay-as-you-go pricing models. So, they are attractive options for businesses. They seek efficiency and flexibility in their OCR implementations.
Integrating OCR into Angular applications
There is a certain process when Integrating OCR into Angular applications. The goal is to effectively extract text from images. Below, we explain the three main steps of the process.
Image pre-processing
Image pre-processing is necessary before text recognition can take place. The reason is that it improves image quality and boosts OCR accuracy. These pre-processing steps involve resizing and reducing noise. They also involve adjusting contrast and binarizing the image. Angular applications can use libraries such as ngx-image-cropper. They can also use custom image processing functions to prepare images for OCR. By integrating these tools, Angular apps can ensure better text recognition results.
Text recognition
Here, the OCR library steps in to analyze images and identify text elements. Angular applications can integrate certain OCR libraries. You can use Tesseract.js or Google Cloud Vision API for this task. Developers can use Angular services to interact with these OCR libraries. This facilitates the text recognition process. By integrating these OCR solutions, Angular apps can efficiently extract text from images. This enables various use cases, such as document scanning and image-based data entry.
Data extraction
First, the application processes the extracted data. Angular components are key here. They display the text to users and support specific functionalities. The process involves parsing recognized text. Then, it conducts validations. Finally, it stores the data in a database. This ensures the data enhances the user experience. It also supports functionalities within the Angular app.
Let’s try out an example code sample shown below. It features an Angular component named OcrComponent. This component leverages the Tesseract.js library. It performs OCR on an image file. The performOCR() method recognizes text asynchronously. Then, it updates the extractedText property with the result. This functionality allows real-time text extraction from uploaded images.
import { Component } from '@angular/core';
import Tesseract from 'tesseract.js';
@Component({
selector: 'app-ocr',
templateUrl: './ocr.component.html',
styleUrls: ['./ocr.component.css']
})
export class OcrComponent {
extractedText: string = '';
constructor() { }
async performOCR(imageFile: File) {
const result = await Tesseract.recognize(
imageFile,
'eng',
{ logger: m => console.log(m) }
);
this.extractedText = result.data.text;
}
}Consider this code snippet. It features an Angular component named OcrComponent. This component leverages the Tesseract.js library. It performs OCR on an image file. The performOCR() method recognizes text asynchronously. Then, it updates the extractedText property with the result. This functionality allows real-time text extraction from uploaded images.
I have tested the above code using the following image and I have displayed the output I got with a GIF.

Output
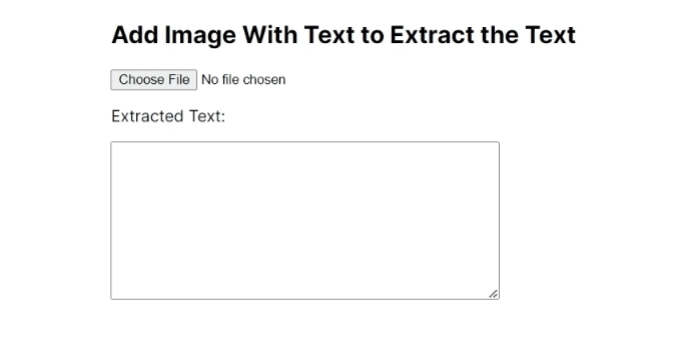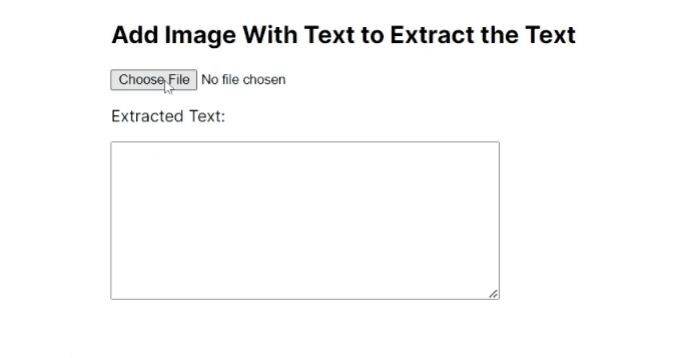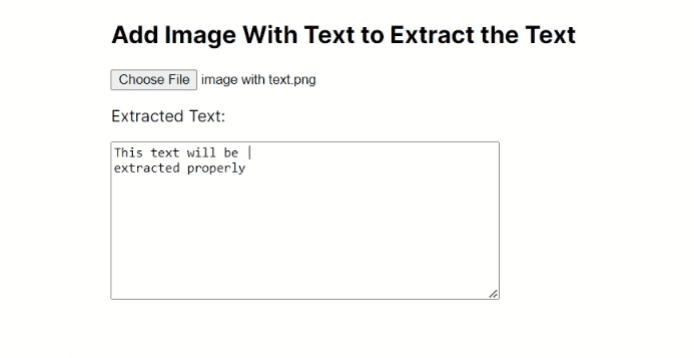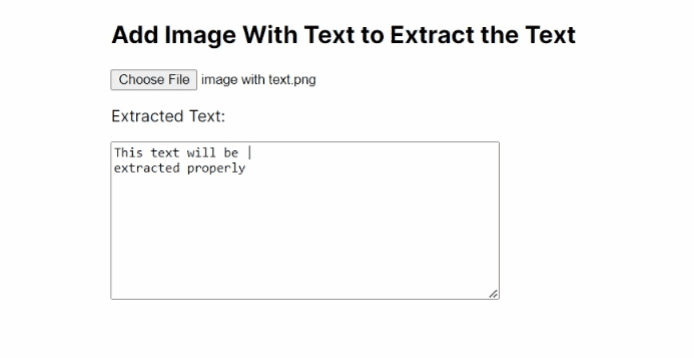
You can find the code of the above app on GitHub.
Building for scalability with Angular
Certain Angular applications are built to handle large-scale image and document processing. In such cases, following the architectural best practices is important for scalability. Angular’s component-based architecture and flexible design make it ideal for managing OCR workflows. By breaking down complex functionalities into reusable components, developers can isolate OCR-related logic. This ensures maintainability and scalability as the application grows.
Additionally, using lazy loading for modules and optimizing routing can improve performance. This is by loading only the necessary components when required. It will contribute to minimizing the initial loading times. Angular’s dependency injection mechanism allows for the integration of OCR libraries and services. This promotes code reusability and testability. With these principles, Angular applications can handle the demands of large-scale processing tasks. Also, It ensures that we maintain scalability, performance, and maintainability.
Beyond basic OCR: advanced techniques
There are some techniques that are beyond basic OCR capabilities. Advanced techniques improve the accuracy and effectiveness of OCR data extraction processes. There is a list of such concepts below.
Layout analysis
Layout analysis involves identifying and understanding the structure of documents. It includes text blocks, tables, and relationships between different data elements. Advanced OCR systems can analyze document layouts to accurately extract text. It can preserve the organization of the content in the document as well. This is important for maintaining document integrity and readability.
Language detection
Handling multi-lingual documents requires reliable language detection capabilities within OCR systems. Advanced OCR solutions can detect the language of the text being processed. This allows accurate recognition and extraction. The language diversity of the document will not matter here. Also, language detection improves versatility and usability, particularly in globalized environments. These environments may have documents that contain many languages.
Error correction
Error correction techniques can reduce the impact of poor-quality images on OCR results. Advanced OCR algorithms use error correction mechanisms to improve accuracy. It accomplishes this by recognizing and rectifying common errors. Errors may include misinterpretations due to smudges, distortions, or varying fonts. OCR systems can improve results even in challenging conditions. They achieve this by intelligently analyzing and processing image data.
Conclusion
The integration of OCR technology surely improves the capabilities of Angular applications. OCR makes Angular applications more intelligent and efficient. This is done by automating repetitive operations, simplifying data extraction, and enabling document digitization. Furthermore, scalability is important for the architecture of these systems. This makes sure that they can manage large-scale image and document processing tasks. If organizations combine OCR with Angular’s structure, they can achieve higher productivity. This will allow them to reach their targets and goals. Therefore, it is clear that you need an OCR solution like filestack. Therefore, don’t wait any further; subscribe to filestack today!
FAQs
What is OCR optimization?
OCR optimization refers to refining the OCR process. It includes improvingthe accuracy, speed, and efficiency of text extraction from images.
How is OCR used in real life?
OCR helps digitize documents and extract data from forms. It is also used for automating data entry tasks and enabling text search.
What software is used for OCR?
Software commonly used for OCR includes filestack, Tesseract, and Google Cloud Vision API.
Does OCR use AI?
Yes, OCR often incorporates AI techniques, such as machine learning algorithms. It improves accuracy and handles complex document layouts.

Shanika Wickramasinghe is a software engineer by profession and a graduate in Computer Science. Her specialties are Web and Mobile Development. Shanika considers writing the best medium to learn and share her knowledge. She is passionate about everything she does, loves to travel, and enjoys nature whenever she takes a break from her busy work schedule.
Read More →