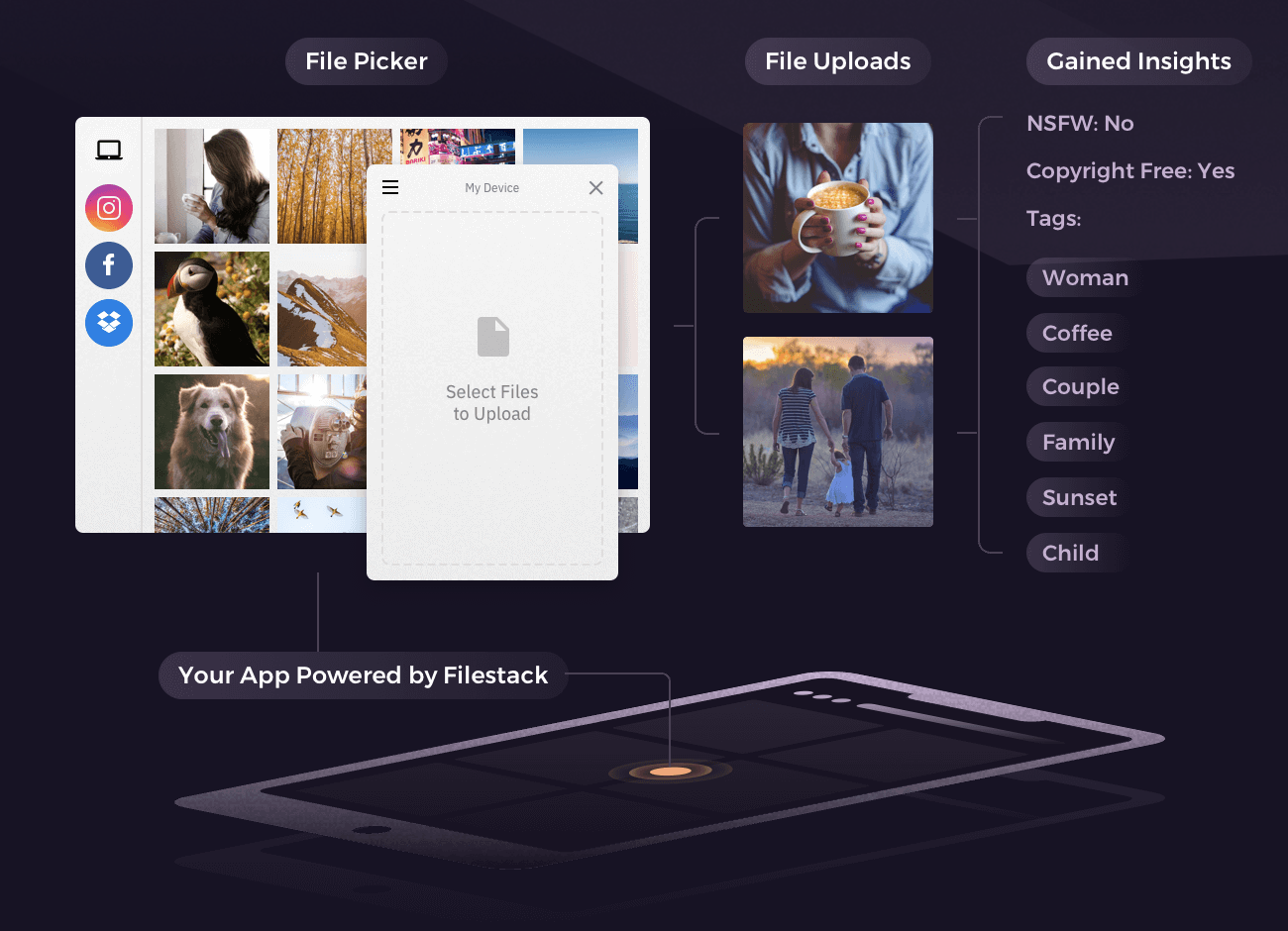
Picture this: you and your family are on a vacation at a beautiful resort. It includes fun, frolic, and the special moments that remind us why life is great. The trip is etched into your memory, and it will be preserved forever through the hundreds of pictures you took.
You want to share them with friends and family right away, so while you’re at the resort bar sipping on your favorite beverage, you fire up your favorite app to create the perfect collection. However, you immediately realize that the resort WiFi is unreliable. Shocking, I know. So you try another app, a website, and you finally give up out of frustration.
Your memories, it seems, will simply have to wait.
This is something many of us have dealt with. It’s reported that 2-4 billion images are uploaded to social networks daily. Whether you’re on a resort’s WiFi, at a conference, or a coffee shop, unreliable uploads plague us. For all of the businesses that rely on us to upload our content reliably and securely, this should be an eye opener. Your top line just dropped because a customer was denied the satisfaction of a creating a family photo book.
Maybe they’ll try again…but maybe they won’t. That’s where we come in.
———-
Filestack’s Content Ingestion Network ensures seamless integration of edge content into an application – reliably, scalably, securely and intelligently.
We are very excited to offer some groundbreaking content intelligence capabilities to our Content Ingestion API platform. Also, we’ve hit over 1 billion files processed to date!
The value living inside content (especially content at scale) cannot be unearthed by manual processing. Content is now proving to be the gateway into understanding customer behavior, and intelligence derived from content can be harnessed to improve business processes and help accelerate the digital transformation of businesses for the future.
In fact according to IDC Futurescapes, two-thirds of Global 2000 Enterprises CEOs will center their corporate strategy on digital transformation, and by 2019, 40% of digital transformation initiatives will use AI services; by 2021, 75% of commercial enterprise apps will use AI as a major part of the strategy which would include machine-learning (ML) solutions.
The implementation of these solutions will change how these enterprises connect with their customers and how they operate today.
But here is the thing, as content grows exponentially, the chasm between content ingestion and actionable business insights grows. For content at scale, a rule based system that relies on manual process isn’t scalable. What’s required is a platform that learns as it processes more data.
Our platform becomes smarter and more efficient as more content is processed. We’ve processed over a billion files to date.
What we’re announcing today will introduce machine learning to process content and return insights that can connect your business to your users like never before. With a combination of image recognition, object detection and optical character recognition, we can now extract information from the images using machine learning models.
Introducing Filestack Content Intelligence
Object Recognition
We’ve partnered with Google Vision and Clarifai to bring you the best in image tagging technologies. Using Filestack Object Recognition, now you can categorize and tag your images without even looking at them.
Object Detection
Sometimes knowing which objects are in your images isn’t enough — you need to know where they are, too. Filestack Object Detection uses state-of-the-art neural networks to detect and locate common objects in photos.
OCR (Optical Character Recognition)
Optical character recognition extracts text from images so you don’t have to. Whether you are reading road signs, transcribing old documents, or grabbing license plate numbers from security footage, Filestack OCR provides the means to reliably extract printed and handwritten data from your images.
Trained machine learning models
Filestack has combined object detection and OCR to provide fine-tuned insights into your scanned physical mail envelope images (AddressOCR) and your bank checks (CheckOCR). By localizing relevant regions on a document and analyzing them using advanced OCR techniques, Filestack provides domain-specific intelligence for your data.
The OCR workflows are triggered when an image has been ingested. The image is then prepared and optimized for OCR by utilizing image transformations like filters, rotation to EXIF, lossless compression, up scaling and noise reduction. This prepares the image for ideal extraction of printed and written content using OCR.
AddressOCR
AddressOCR then processes the image of the physical envelope and extracts the following information from the image:
- Sender
- Sender Logo
- Recipient Name
- Recipient Address (with every component of the address made available)
- Intelligent Bar Code
- Nixie Label contents if the mail is forwarded
- Mail priority class
The recipient address can also be confirmed by integrating with third party address verification system like SmartyStreets to verify accuracy of OCR.
CheckOCR
CheckOCR processes the scanned images of bank checks and extracts the following information:
- Bank logo (if present)
- Sender name
- Sender return address (if present)
- Payee name
- Amount (Courtesy Amount Recognition (CAR) / Legal Amount Recognition (LAR))
- Micr line (check number, routing number, account number)
- Numerical check amount, cross-referenced against printed or handwritten check amount
- Handwritten notes (if present)
The entire workflow is executed as an asynchronous process and a webhook is returned when the processing is complete along with the information above in a JSON response.
These complex automation tasks can be executed with just a few lines of code. The simplicity of the integration and the business value of automation makes this capability a compelling necessity for any business that wants to transform itself into a productive, innovative business.
“A simple integration with Filestack’s content intelligence API allowed us to offload the analysis of a large volume of mail quickly and reliably. This automation has proven critically important as our team has more time to focus on enhancing our core product.”
Steven Maguire, VP Technology at Earth Class Mail
Copyright Detection:
The Content Ingestion API workflow can now detect images that are copyright protected. Upload a single image or millions of images, a single API call will display the copyright status of any image. This is especially useful for businesses that rely on user generated content and require their uploads to be free of copyrights. For example, TripAdvisor, has the following requirements (summarized) for uploading an image into their massive universe of reviews:
- Safe for work (no vulgar, offensive, inappropriate images)
- Free of copyright
- Image must adhere to specific size, type and resolution criteria.
With content intelligence within the Filestack API platform this criteria conformance can be performed with a single API call. We are extremely excited to make our API platform richer with content intelligence.
Ready to get started?
Create an account now!
Asset Management
As millions of assets (documents, images, audio files, video files) are uploaded, it is important to be able to manage this content at scale. We are thrilled to release capabilities within the API platform that allow you to upload and manage these assets at scale.
- Advanced Search: Search assets with a Quick Search or use advanced filters to search for the assets. This enables users to quickly find assets that have been uploaded.
- Asset analytics: Know your users through the content they upload. We have added the following analytics to the platform to help you gain invaluable insights based on the content that is ingested:
1. Timelapse usage of number of files uploaded, content transformations and the CDN bandwidth utilized.
2. Distribution of type of content uploaded
3. Second-level distribution of image, audio and video file types
4. Distribution of the upload sources that allows businesses to understand where their users have their files stored, which can help their targeted marketing programs.
- Download and delete assets: Many users want to search for particular assets and download them or delete them from the developer portal. Now with the click of a button, multiple assets can be downloaded as a single zip file.
Product Performance
Content Instant Access: Many open source and DIY implementations of content ingestion have a significant drawback where the content (an image for example) can’t be transformed (resolution, red-eye reduction, filters, etc.) or served using a CDN until all its contents are successfully transferred to its destination storage location. But if your users are uploading a large number of large files, network latency can cause a significant lag in the transformation and delivery of the assets. Filestack has developed a groundbreaking approach to solve the problem.
The content that is uploaded with the Content Ingestion API is first uploaded to the closest point of presence (POP). At this time, the content can be transformed and served while the bytes are transferred from the point of presence to the destination storage location. With Content Instant Access, uploads can be approximately 10x faster than traditional file uploading approaches.
———-
Product Updates
Storage Aliases
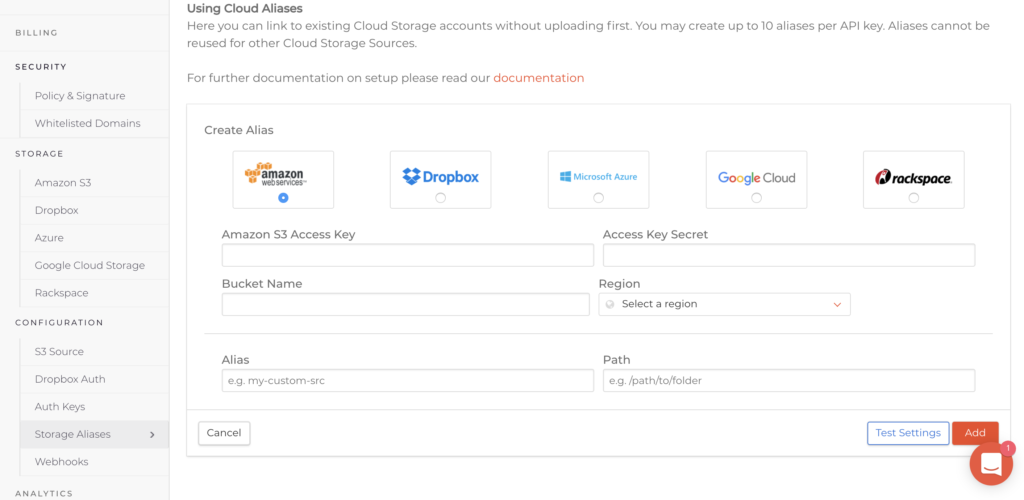
Filestack has been the leader in integrating a multitude of cloud sources, allowing users to upload files from their favorite storage platform or social media network. Businesses may have hundreds of thousands of images or TBs of data already stored within cloud storage platforms like Amazon S3, Azure Blobs, Google Cloud Storage, Box or Rackspace cloud. Re-uploading this content to perform asset transformations is both expensive and time consuming.
A workaround is to make the storage location public and then access, transform and serve that content. But the security gap of exposing content publicly is one that most businesses refuse, and rightfully so. In this context, how does one access and serve content from a private storage area without re-uploading content?
Introducing Filestack Storage Aliases. Simply create aliases for private cloud storage areas (at the granularity you desire) and we create a secure, abstracted url for the content within that storage that can be transformed and served – without re-uploading content and keeping the storage private.
iOS Files and iCloud integrations
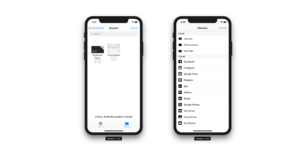
Files is the new Finder app for iOS 11. Files is a central place from which to access all the files on your iDevice, and in iCloud. You can find, organize, open, and delete all the files on your device, in iCloud, and on 3rd-party storage services like Dropbox. Filestack’s iOS SDK now fully integrates with Files app. Browse, select and upload content from the Files integration within the Filestack File Picker.
———-
We’ll be rolling these features to our entire customer base over the next couple of weeks within the Content Ingestion API platform to help address the challenge of seamlessly integrating edge content into an application – reliably, scalably, securely and intelligently. Be sure to sign up for a free account and be sure to post any questions.
Sameer Kamat, CEO at Filestack
Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.
Read More →