






One of the coolest papers to come out of the deep learning renaissance has been A Neural Algorithm of Artistic Style. Presumably, it’s what drives Prisma, and it’s completely open to the world. Anyone can build their own neural filters if they have the time and inclination — which is exactly what we are going to do.
Using a combination of Filestack and PyTorch, by the end of this tutorial you should have a functioning website, where users can upload two images and get back a result sharing the content of one and the style of the other.
Building the Website
We could use open-source implementations with pretrained filters — useful if you are building a real production application and need speed — but for learning and aesthetic purposes, we will train each image combo from scratch. It takes a bit longer, but the results are more powerful and informative.
The first thing our users need is the ability to upload two files: the original content image and the one whose style they wish to replicate. Admittedly, working with files on the browser can often be cumbersome and frustrating. Luckily, Filestack makes uploading as easy as adding a script tag to an HTML file and writing a few lines of Javascript.
<html>
<html lang="en">
<head>
<meta charset="utf-8">
<script src="https://static.filestackapi.com/v3/filestack-0.5.2.js"></script>
</head>
<body>
<button id="file-input">Choose File to Upload</button>
<img id="image"></img>
<script>
var uploadOptions = {
maxFiles: 3,
accept: ['image/jpeg', 'image/png'],
fromSources: ['local_file_system', 'imagesearch', 'facebook', 'instagram',
'googledrive', 'dropbox', 'flickr', 'github', 'gmail', 'onedrive']
}
var client = filestack.init('<YOUR_API_KEY_HERE>')
var pickFile = function(options){
client.pick(options).then(function(results){
var files = results.filesUploaded
var fd = new FormData()
fd.append('content', files[0].url)
fd.append('style', files[1].url)
var xhr = new XMLHttpRequest()
xhr.responseType = 'blob'
xhr.addEventListener('load', function(response){
var data = response.target.response
var image_field = document.getElementById('image')
image_field.src = URL.createObjectURL(data)
})
xhr.open('POST', 'http://localhost:5000')
xhr.send(fd)
})
}
var input = document.getElementById('file-input')
input.addEventListener('click', function(){pickFile(uploadOptions)})
</script>
</body>
</html>
With the Picker loaded into the browser, all we have to do is create an upload form (which can be as basic as a single button) and call the upload function. Filestack has many different plans to suit various usage needs, but the free tier should be perfect for our tutorial. And it’s always easy to upgrade if you need higher uploading limits.
Connecting the Backend
As you might have imagined, we cannot rely on the client to perform our machine learning magic. We will need a backend for this, and since Python is very convenient for both machine learning and backend work, we will use Flask to integrate with our client.
from flask import Flask, render_template, request, send_file
from neural_style import train
app = Flask(__name__)
@app.route('/', methods=['GET'])
def hello():
return render_template('index.html')
@app.route('/', methods=['POST'])
def get_url():
new_image = train([request.form['content'], request.form['style']])
return send_file(new_image, mimetype='image/jpeg')
if __name__ == '__main__':
app.run(debug=True)
The Model
While it would be best to read the original algorithm in its entirety, the math will be slightly confounding if you are not well-versed in machine learning, calculus and linear algebra. However, understanding some of how the model works will help you customize training settings and hyper-parameters as you may need, so we will do a crash course.
The foundation of A Neural Algorithm of Artistic Style, and most image-based machine learning models, is the convolutional neural network. When you use Google Vision, or when Facebook guesses the names of your friends in a photo, or anytime a service you are using seems to know too much about an image you’ve uploaded, convolutional neural networks are probably involved. Using linear algebra and calculus, they break up images into hundreds or thousands of progressively smaller squares that are then used to find abstract patterns in data. By tweaking millions of parameters a little bit at a time over thousands or millions of training images, convolutional neural networks can map various, abstracted visual “features” from images to some kind of human-understandable classification.
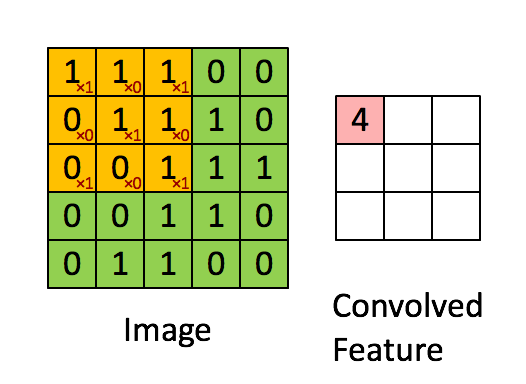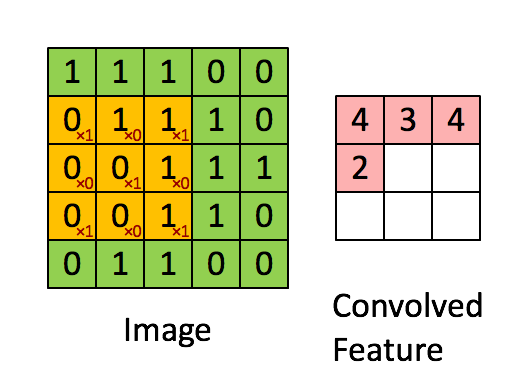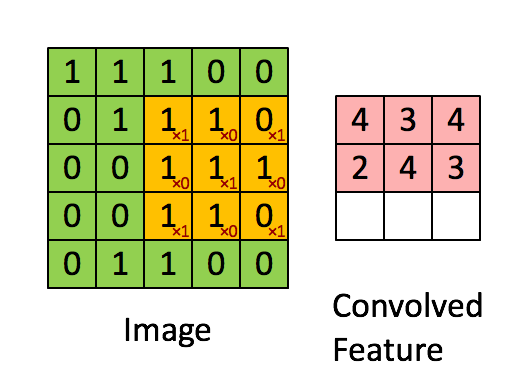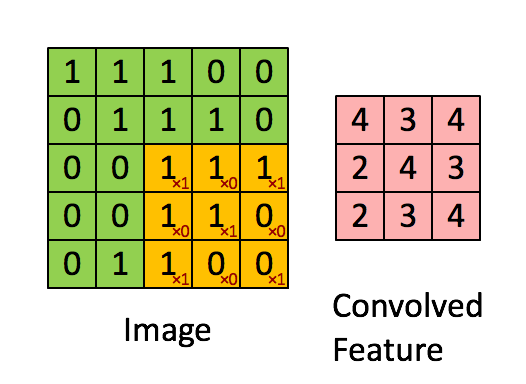

This is how Google can take an image of a dog and tell you not only that it’s a dog, but often what kind of dog. After millions and millions of training examples, the model has learned to associate certain collections of visual patterns (represented as matrices) with certain words. The above image demonstrates that these patterns end up being just real numbers (or zeros and ones, for black and white images) that represent single pixels, summed over an image patch to create a smaller image patch. Do this enough times, over all color channels, and you can eventually get a probability over a set of classes.
For a more depth look into convolutional networks and the math behind them, check out this post, with lots of helpful visualizations and intuitive explanations.
Convolutional Style
The breakthrough in the paper by Gatys et al was to find that as images go through this convolutional process, being slowly broken down from fewer larger features into many smaller ones, their style and their content become separable. What that means is higher layers, where the features are still relatively large, seem to preserve the content features — what humans would identify as the objects or features in an image (cat, dog, hat, ocean, etc) — whereas the lower layers preserve the visual style, the textures, the colors, particular brush strokes or how the edges bleed.
Because of this hierarchical distinction between content and style, it is possible to take a noise image and train a model to slowly morph it until it conforms to the style of one image and the content of another.
Spinning Up the Model
Hard though it may be to believe, with modern machine learning libraries and a pretrained SqueezeNet network, the implementation of this algorithm is not terribly complicated (all things relative, of course). I am using a modified version of this PyTorch script, and you can play around to find the settings that work best for you.
Effectively, what we need to do is take the images our user has selected from the Filestack upload widget and send them through. As an added bonus, this code works on a CPU! So no need to worry about spinning up a CUDA instance to get this going (although that would speed up your processing times).




Here are a few things you might want to tweak to achieve better or more personalized results:
- The learning rate and number of iterations. The script’s settings use high learning rates out-of-the-box, which means faster training, but the potential to get stuck in local minima. If you find your results are blowing out, have lots of noise, or just aren’t as good as you would like, try lowering the learning rates before trying anything else.
- The style weights. In the code there are options telling the model how much to blend the style and content of each layer. Changing this will influence the output.
- A different pretrained model. If you feel adventurous, you can always substitute the pretrained Squeezenet model for VGG or InceptionResNet. These are deeper models with more parameters, and will probably give you better results, but at the expense of processing time.


Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.