
Every business deals with documents every day. Companies receive invoices in emails, store contracts in cloud folders, process patient forms, and verify ID documents during user onboarding. All these documents contain important information, but turning that information into usable data often takes a lot of manual work.
A modern data extraction SDK helps automate this process. Instead of employees reading documents and typing the information manually, the software can read the document, extract the important details, and send the data to other systems automatically.
But building a good document extraction system is not as simple as adding an OCR tool. Developers also need to think about document uploads, data accuracy, speed, scalability, and security throughout the entire process.
In this guide, we’ll explain how data extraction SDKs work, what features developers should look for, common problems in document processing pipelines, and why the document upload step plays a big role in the final results.
Key Takeaways
- A data extraction SDK uses OCR, machine learning, and data parsing to turn documents into structured and usable data automatically.
- Modern extraction tools do more than just read text. They can understand document layouts, identify fields, and connect related information.
- Poor image quality, difficult document designs, and handwritten text are some of the biggest challenges for accurate data extraction, but developers can reduce these issues with the right techniques.
- Security and scalability should be planned from the beginning, especially for industries that handle sensitive documents and user data.
- Filestack make document uploads easier with features like mobile capture, uploads, and image optimisation, helping extraction systems work with cleaner and higher-quality files.
To understand how modern document automation works, it’s important to first understand what a data extraction SDK actually does.
What Is a Data Extraction SDK?
A data extraction SDK is a software toolkit that helps developers automatically extract useful and structured information from documents. It uses technologies like OCR (Optical Character Recognition), machine learning, and smart data parsing to read and understand documents such as invoices, forms, PDFs, and ID cards.
Instead of building a complicated document-processing system from scratch, developers can use the SDK’s APIs and libraries to easily add document extraction features to web apps, mobile apps, or backend systems. This makes the entire process faster, simpler, and easier to manage.
Definition of a Data Extraction SDK
At its core, a data extraction SDK is a software toolkit that helps extract structured information from documents. It combines OCR, data parsing, and automation features into one system and can be easily integrated into web apps, mobile apps, and backend systems. This allows developers to add document extraction features without building the entire system from scratch.
Types of Data Commonly Extracted
Common types of data extracted from documents include names, addresses, invoice amounts, item details, dates, transaction information, passport or ID numbers, expiration dates, form responses, and table data from financial or medical records. The type of information you need to extract will help determine which features and capabilities are most important in a data extraction SDK for your project.
Common Document Formats Supported
Most modern data extraction SDKs support PDFs, including both text-based and scanned PDFs. They also work with image formats like JPEG, PNG, and TIFF, as well as scanned forms, receipts, invoices, purchase orders, and identity documents such as passports and driver’s licenses. Before choosing an extraction tool, it’s important to understand which document formats your workflow needs to handle.
Now that we understand what a data extraction SDK is, let’s look at why businesses are using these systems more than ever.
Why Businesses Need Automated Document Data Extraction
The benefits of automation are easy to see overall, but it’s also important to understand why manual document workflows often fail. These problems directly affect how a data extraction pipeline should be designed and what it needs to handle effectively.
Manual Data Entry Creates Operational Bottlenecks
Manual data entry is naturally slow because every document needs to be read and processed by a person. This takes time, increases the chance of typing mistakes, and requires trained employees. As the number of documents grows, especially during busy periods, the workload becomes harder to manage. Hiring more people can help temporarily, but it also increases costs and doesn’t solve the main problem.
Accuracy is another major challenge. Manual data entry often leads to errors, with mistake rates commonly ranging from 1% to 5%. In industries like finance and healthcare, even small errors can create serious issues such as failed payments, compliance problems, or incorrect records that take extra time and money to fix.
Automated Extraction Improves Operational Efficiency
Automated document data extraction replaces manual work with software and infrastructure. A well-designed system can process thousands of documents every hour while maintaining consistent accuracy. This reduces errors and cuts processing time from hours or days down to just seconds. It also makes costs more predictable and scalable, something manual workflows struggle to achieve, especially as document volumes continue to grow.
Industries Using Data Extraction SDKs
The biggest benefits of automated data extraction are seen in industries that handle large numbers of documents and where mistakes can be costly. This includes financial services, healthcare, legal technology, insurance, e-commerce, logistics, and supply chain operations. In these industries, automated extraction is not just a helpful feature; it’s an essential part of running workflows efficiently and at scale.
Once the business need is clear, the next step is understanding how the extraction process actually works.
How a Data Extraction SDK Works
Now that the business need is clear, let’s look at what happens behind the scenes when a document goes through a data extraction pipeline. Each step in the process has its own technical challenges, and if one stage fails, it can affect the accuracy and quality of everything that comes after it.
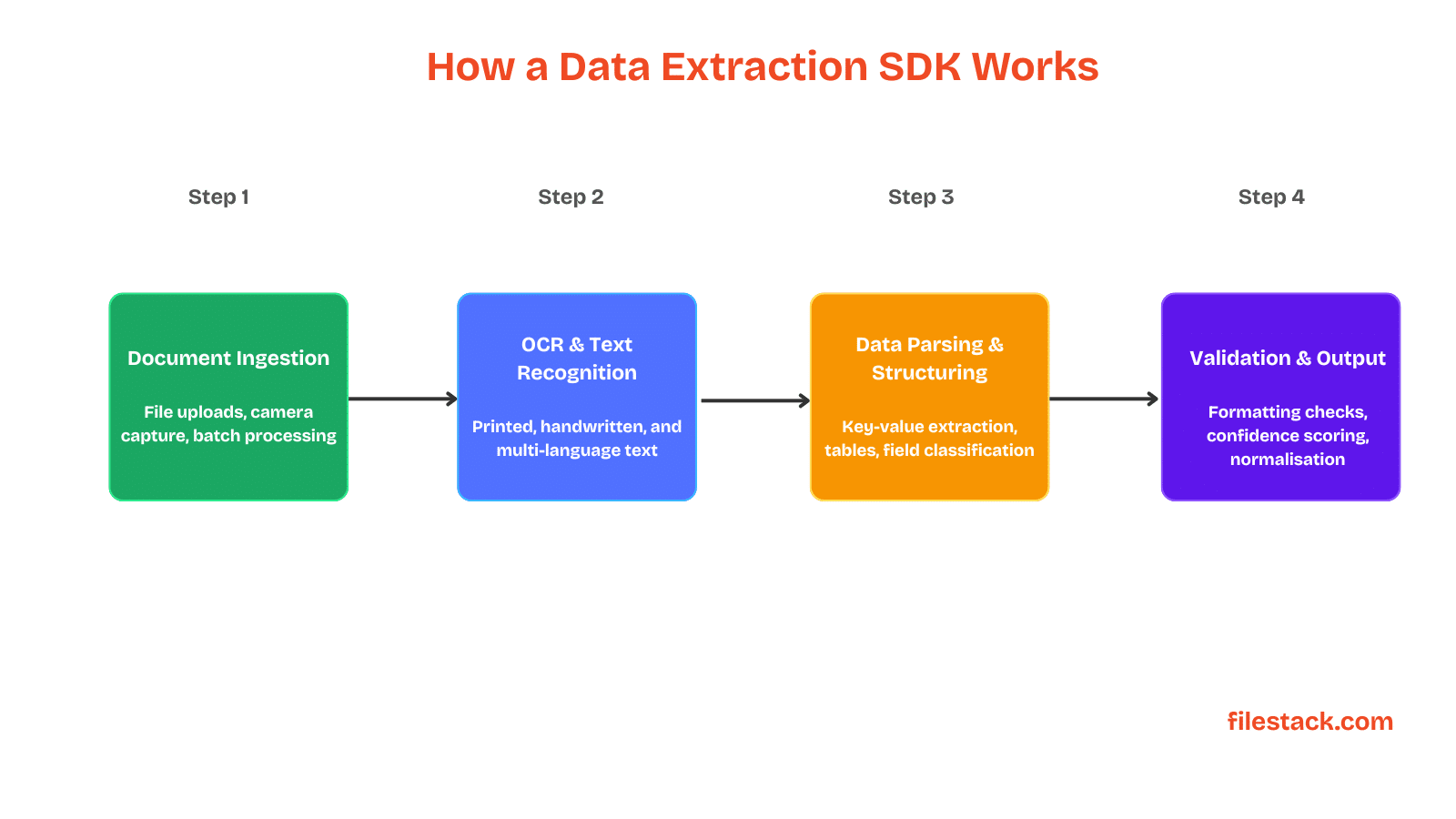
Step 1 — Document Ingestion
The process starts with getting the document into the system properly. This can include file uploads from websites or mobile apps, camera capture for users in the field, or batch uploads for large-scale business operations.
This step is more important than many teams realise. If a document is blurry, rotated incorrectly, or cropped badly, the rest of the extraction process becomes less accurate because the system is working with poor-quality input.
Tools like Filestack Capture help improve this first step by handling secure uploads, mobile document capture, image optimisation, automatic edge detection, and perspective correction before the document reaches the OCR system. Better input quality usually leads to better extraction results, especially in real production environments.
Step 2 — OCR and Text Recognition
After the document is uploaded, OCR (Optical Character Recognition) converts the text inside the document into machine-readable data. Modern OCR systems can read printed text from many different fonts and layouts, recognise handwritten text to some extent, and support multiple languages, even in the same document.
However, OCR accuracy depends heavily on document quality. Low-resolution images, poor lighting, tilted pages, blurry scans, and complex layouts can reduce accuracy. That’s why image cleanup and preprocessing during the upload stage are so important. Better-quality documents lead to more accurate text extraction and fewer processing errors later in the pipeline.
Step 3 — Data Parsing and Structuring
Raw OCR output is just text; it is not organised or structured data yet. Parsing is the process that turns this text into useful information that applications can understand and use.
This includes identifying labels and their values, extracting data from tables, recognising patterns like dates or currency amounts, and classifying information into categories such as names, addresses, invoice totals, or ID numbers.
Modern data extraction SDKs often use machine learning models trained on specific document types like invoices, passports, insurance forms, and receipts. These models help the system understand real-world document layouts and improve accuracy much more than simple rule-based methods alone.
Step 4 — Validation and Normalisation
Before the extracted data is sent to other systems, it needs to be validated and standardised. This step checks whether dates, currency values, ID numbers, and other fields follow the correct format. It can also detect duplicate documents, assign confidence scores to extraction results, and convert data into consistent formats for easier use in downstream systems.
Confidence scoring is especially important because it helps identify uncertain or low-quality extractions that may need human review. This allows most documents to move through the workflow automatically, while only problematic cases are flagged for manual checking.
Without proper validation, incorrect or inconsistent data can enter the system, creating issues that are often hard and expensive to fix later.
Understanding the workflow makes it easier to see which SDK features matter most in real applications.
Core Features Developers Should Look For in a Data Extraction SDK
Not all data extraction SDKs offer the same features or level of performance. Choosing the right one early is important because it can prevent major problems and extra development work later. The capabilities of the SDK you choose will also affect how powerful, accurate, and scalable your document processing system can become.
OCR Accuracy and Language Support
The most basic requirement for any data extraction SDK is reliable OCR support for the document types and languages your system needs to handle. A good SDK should support multiple languages, including non-Latin scripts, offer handwriting recognition, and work well even with low-quality images.
This is important because real-world documents are often blurry, tilted, poorly scanned, or captured in bad lighting conditions. Your extraction pipeline needs to handle these situations reliably, not just perfect sample documents.
Structured Data Extraction Capabilities
Beyond raw OCR, a good data extraction SDK should include specialised features for the types of documents your business handles. This can include invoice parsing that works across different vendor layouts, receipt extraction for expense tracking, form field recognition for applications and intake forms, and table extraction that keeps rows and columns properly organised instead of converting everything into plain text.
API and SDK Flexibility
It’s also important to check whether the SDK works well with your existing system and development workflow. Look for features like REST APIs for backend integration, mobile SDKs for iOS and Android apps, web integrations for browser uploads, and cloud-based processing for handling large volumes of documents.
Good integration support gives you more flexibility and makes it easier to scale your system in the future. A poorly matched SDK can quickly become a limitation as your product grows.
Real-time and Batch Processing Support
Most production systems need both real-time and batch document processing. Real-time processing is important for tasks like identity verification during user onboarding or instantly processing uploaded invoices. Batch processing is useful for handling large numbers of documents at scheduled times, such as overnight financial reconciliation or backlog processing.
A good data extraction SDK should support both workflows. If it only works well for one type of processing, it can create limitations as your system and use cases grow over time.
At this stage, it’s important to understand the difference between basic OCR and intelligent data extraction.
OCR vs. Intelligent Data Extraction
This difference is important for teams trying to decide how advanced their document extraction system needs to be. It’s also a common source of confusion because many tools are marketed with similar terms, even though their actual capabilities can vary a lot.
| Feature | OCR Only | Intelligent Extraction |
| Layout Detection | ✗ | ✓ |
| Field Mapping | ✗ | ✓ |
| Relationship Extraction | ✗ | ✓ |
| Structured Output | Limited | ✓ |
| Confidence Scoring | ✗ | ✓ |
OCR Only Extracts Raw Text
OCR simply reads text from an image or document and converts it into machine-readable text. However, it does not understand the structure or meaning of the document. It cannot tell which text is a label, which is a value, how rows in a table are connected, or whether “Total Amount” refers to the final total or a subtotal.
Because of this, raw OCR output usually needs extra processing before it becomes useful for other systems. Many teams underestimate how much work is needed to organise, clean, and structure OCR data properly for real-world applications.
Intelligent Extraction Identifies Structured Fields
Intelligent extraction goes beyond basic OCR by understanding the structure and meaning of a document. It can detect different sections of a document, such as headers, tables, footers, and signature areas. It can also automatically match labels with their correct values without relying on fixed rules.
More advanced systems can even understand relationships between pieces of information, for example, identifying which price belongs to which product or which date matches a specific transaction. This makes the extracted data much more accurate and useful for real-world workflows.
Why Structured Extraction Matters
Most real-world document workflows involve many different document formats and layouts. In these situations, intelligent extraction is essential for achieving high accuracy in production systems.
It helps automate document processing faster, reduces the need for manual corrections, and produces cleaner data for other systems to use. This is possible because intelligent extraction understands the structure and meaning of a document, not just the text written on the page.
With the technical concepts covered, let’s look at how these systems are used in real-world applications.
Common Use Cases for Data Extraction SDKs
To better understand these technical concepts, let’s look at some common real-world use cases and the specific capabilities each one needs from a document extraction pipeline.
Invoice and Receipt Processing
Accounts payable automation is one of the most common and high-volume use cases for document extraction in finance teams. The system needs to extract information such as vendor names and addresses, invoice numbers, product line items, quantities, prices, tax amounts, totals, and payment terms.
The biggest challenge is that invoices come from many different vendors, and every invoice may have a completely different design and layout. Because of this, the extraction system needs to understand different document formats instead of depending only on fixed templates.
Identity Verification Workflows
KYC onboarding and age verification systems need to extract and verify information from passports, driver’s licenses, and national ID cards. This includes details like names, dates of birth, ID numbers, and expiration dates.
These workflows require very high accuracy because even small mistakes, such as reading a birth date or document number incorrectly, can lead to compliance and verification issues. They also need strong security and privacy protections since they handle sensitive personal information.
Form Digitisation and Automation
Healthcare forms, insurance claims, and government applications are often submitted as paper documents or scanned PDFs. To digitise these documents, extraction systems need to read printed labels as well as handwritten or typed responses and then convert them into structured data for backend systems.
This process usually combines OCR, layout detection, and handwriting recognition together to accurately understand and organise the information from the document.
Contract and Legal Document Processing
Legal teams often need to extract information such as contract clauses, party names, effective dates, and obligation terms from legal documents. This is more advanced than simple field extraction because the system must understand the meaning of sentences and paragraphs, not just labels and values.
Many legal document workflows begin with clause extraction and document indexing, which help teams organise, search, and analyse large numbers of contracts more efficiently.
Although modern extraction systems are powerful, real-world documents still create several accuracy challenges.
Accuracy Challenges in Document Data Extraction
No document extraction system is perfectly accurate from the start. Understanding where errors come from helps teams build pipelines that can detect, manage, and recover from problems instead of allowing incorrect data to pass through unnoticed.
Poor Image Quality Affects OCR Accuracy
Blurry scans, poor lighting, low-contrast images, and tilted or rotated documents are some of the most common causes of OCR errors. If a document is scanned in low quality or photographed from an angle, the extracted text will usually be less accurate, even when using a powerful OCR system.
Problems with document quality at the upload or capture stage can affect every step that comes later in the extraction pipeline.
Complex Document Layouts Create Parsing Difficulties
Complex document layouts can make data extraction much harder. Multi-column pages, nested tables, watermarks, and sections that combine text with charts or images often confuse systems that are designed for simpler document structures. In many cases, headers and footers may also be incorrectly treated as important data fields.
As document formats become more varied, template-based and rule-based extraction systems are more likely to fail, especially when they encounter layouts they were not specifically designed to handle.
Improving Extraction Accuracy
Some of the best ways to improve extraction accuracy happen before OCR even begins. This includes image preprocessing steps like straightening tilted documents, removing noise, and improving image contrast. These improvements help OCR systems read documents more clearly and accurately.
AI-based field recognition is also important because it can understand different document layouts without depending only on fixed templates. This makes the system more flexible for real-world documents.
Another useful approach is human review for low-confidence extractions. If the system is unsure about certain fields, those documents can be sent to a person for verification instead of allowing incorrect data into the workflow.
Improving document quality during the upload stage can make a big difference as well. Filestack automatically optimise uploaded images, helping OCR systems work with cleaner inputs and improving overall extraction accuracy without changing the extraction system itself.

Accuracy is important, but production systems also need to handle growing document volumes efficiently.
Performance and Scalability Considerations
A document extraction pipeline that works well for 100 documents a day may struggle or completely fail when processing 10,000 documents daily. That’s why scalability should be planned from the beginning instead of being added later after performance issues appear in production.
Building for scale early helps ensure the system can handle growing document volumes without slowing down, crashing, or creating processing bottlenecks.
High-volume Document Workflows Require Scalable Infrastructure
Batch processing systems help handle large numbers of documents more efficiently. Instead of processing every document immediately during a user request, documents are added to a queue and processed later by worker systems running in the background.
As document volume increases, more workers can be added to handle the extra load. This makes the system easier to scale horizontally instead of relying on a single powerful server. For very large workloads, distributed processing or cloud-based extraction services are often more scalable and cost-effective.
Optimising Extraction Speed
Several technologies help improve the speed and performance of document extraction pipelines. Parallel OCR workflows allow multiple documents to be processed at the same time, while GPU acceleration helps machine learning models run faster during extraction. Some systems also use incremental processing, where parsing begins before the entire document upload is complete, reducing overall processing time.
The upload infrastructure also affects performance. Globally distributed file upload systems can reduce the time it takes for documents to reach the processing pipeline, helping improve the total speed from document upload to final extraction.
Reducing Latency in Real-time Applications
Several technologies help improve the speed and performance of document extraction pipelines. Parallel OCR workflows allow multiple documents to be processed at the same time, while GPU acceleration helps machine learning models run faster during extraction. Some systems also use incremental processing, where parsing begins before the entire document upload is complete, reducing overall processing time.
The upload infrastructure also affects performance. Globally distributed file upload systems can reduce the time it takes for documents to reach the processing pipeline, helping improve the total speed from document upload to final extraction.
As document processing scales, security becomes just as important as performance and accuracy.
Security Best Practices for Document Data Extraction
Documents processed through extraction pipelines often contain highly sensitive information, such as personal details, financial records, healthcare data, and legal documents. Because of this, security should be built into the system from the beginning instead of being added later only for compliance requirements.
A secure architecture helps protect sensitive data throughout the entire document processing workflow.
Sensitive Documents Require Strong Security Controls
Financial documents, identity records, and legal paperwork are all subject to strict rules about how they are stored, shared, and accessed. Because these documents contain highly sensitive information such as bank details, ID numbers, medical records, and legal data, any security breach or compliance failure can create serious risks for both businesses and users.
Essential Security Measures
Any production-ready document extraction pipeline should include strong security protections from the start. This includes encrypting documents while they are being transferred and while they are stored, using secure storage systems that separate document data from normal application data, and applying access controls so only authorised users or services can view sensitive documents.
It’s also important to maintain audit logs that track which documents were accessed, when they were accessed, and which systems or users interacted with them. These measures help improve security, compliance, and accountability across the entire pipeline.
Minimising Exposure of Sensitive Information
Beyond basic security measures, reducing how long sensitive documents stay in your systems can greatly lower security risks. Good practices include temporarily storing files only during processing, automatically deleting them afterwards, using secure, isolated environments for document processing, and setting automatic data retention policies that remove old files after a defined period.
These security practices are best implemented from the beginning instead of being added later only to meet compliance requirements.
Beyond performance and security, developer experience also plays a major role in long-term success.
Developer Experience Considerations for Data Extraction SDKs
Even a powerful data extraction SDK can become difficult to use if the integration process is complicated. Poor developer experience can slow down development, make the system harder to maintain, and increase long-term costs.
Good developer tools, clear documentation, simple APIs, and reliable integrations help teams build and manage document extraction pipelines more quickly and confidently over time.
Easy Integration Accelerates Implementation
A good developer experience starts with clear and detailed SDK documentation that includes practical examples. Helpful sample applications should show how to handle common document types as well as difficult edge cases.
The SDK should also provide consistent API behaviour across different document formats so developers can work with it more easily. In addition, developer tools that allow local testing without needing a complete cloud setup can make development faster and simpler.
Features That Simplify Adoption
Prebuilt workflows for common documents like invoices, receipts, and ID cards can help teams launch much faster, especially if they are new to document extraction systems.
Useful features like file upload integrations for popular storage services, webhook-based event processing instead of constant polling, and clear error messages that explain what went wrong and how to fix it can make the integration process much simpler and easier to maintain.
Cross-platform Support Developers Expect
Modern document processing systems need to work across many different environments. This includes web apps for browser uploads, mobile apps that use phone cameras to capture documents, backend services that process files automatically, and cloud-based systems that need scalable infrastructure.
A production-ready data extraction SDK should support all of these environments consistently and provide similar integration patterns across platforms to make development and maintenance easier.
Even with the right tools, many teams still run into common implementation mistakes.
Common Mistakes Teams Make When Building Extraction Workflows
These are common patterns and challenges that many teams face when building their first real-world document extraction pipeline. Understanding them early can save a lot of time, money, and engineering effort compared to discovering the problems later in production.
Treating OCR as Complete Extraction
OCR and data extraction are not the same thing. OCR only converts text from a document into machine-readable text. That text still needs to be organised, validated, and converted into structured data before other systems can use it properly.
Many teams make the mistake of adding an OCR tool and assuming the job is finished. In reality, most of the difficult engineering work happens in the extraction layer, where the system needs to understand document structure, identify fields, and handle different layouts correctly.
Without this structured extraction layer, pipelines can become fragile and may fail silently when documents do not match the expected format.
Ignoring Image Preprocessing Requirements
Many teams delay image preprocessing because it seems like an optional improvement. In reality, it is one of the most effective ways to improve OCR accuracy for real-world documents.
Simple preprocessing steps like straightening images, reducing noise, and improving contrast can significantly improve extraction results. Using a document upload platform that handles these optimisations automatically can save a lot of time and reduce debugging problems later in the pipeline.
Underestimating Operational Complexity
Running a document extraction pipeline at scale involves much more than just extracting data from documents. Teams also need to manage queues, handle errors and retries, monitor system health, scale infrastructure, and maintain or update machine learning models over time.
These operational challenges often become noticeable only after the system moves from testing into real production environments. Planning for scalability, monitoring, and maintenance early makes the pipeline more reliable and much easier to manage later.
One area that often gets overlooked is the document upload and ingestion layer.
How Filestack Supports Document Upload and Data Processing Workflows
A document extraction system is only as good as the documents it receives. The way documents are uploaded and entered into the system has a major impact on extraction accuracy, user experience, and overall reliability.
Many extraction problems actually begin during the upload and capture stage, even though the issues may appear later during processing. Poor-quality uploads, incorrect document captures, or incomplete files can all reduce extraction performance.
Features Developers Need for Document Ingestion Workflows
Filestack Capture provides the document upload and ingestion tools that many extraction pipelines rely on. It supports secure file uploads from web apps, mobile devices, and cloud storage platforms.
It also includes mobile document capture features like automatic edge detection and perspective correction, helping users capture cleaner document images. In addition, it integrates with storage services such as Amazon S3, Google Cloud Storage, and Azure Blob Storage for easier document management and processing.
How Filestack Improves Document Handling Workflows
Filestack includes image optimisation features that can resize documents, improve contrast, fix rotation issues, and optimise images before they reach the OCR or extraction system. This helps improve extraction accuracy without requiring developers to build their own preprocessing workflows.
Its globally distributed upload infrastructure also helps reduce upload delays for users in different locations. In addition, Filestack provides APIs and SDKs with consistent integration patterns across web, mobile, and backend environments, making development simpler across platforms.
Benefits of Integrating Upload and Extraction Workflows
When document uploads and data extraction are treated as one connected system instead of separate parts, the entire workflow becomes faster and more reliable. Users get a smoother experience during document capture and upload, while developers benefit from a simpler system that is easier to maintain and scale.
For applications that process large numbers of documents, such as invoice automation, identity verification, and form digitisation, this connected approach is often what makes the difference between a pipeline that only works in demos and one that performs reliably in real production environments.
Putting all these pieces together is what makes a reliable document extraction pipeline possible.

Conclusion
Document data extraction may seem simple at first, but building a reliable system for real-world documents is much more challenging. While technologies like OCR, parsing, and validation are well established, real-world problems such as poor image quality, different document layouts, handwriting, large document volumes, security requirements, and ongoing system maintenance add significant complexity.
A good data extraction SDK can handle much of the parsing and extraction work automatically. However, extraction quality depends heavily on document quality. If documents are uploaded with poor lighting, incorrect rotation, blur, or missing sections, those problems can affect the entire pipeline.
That’s why the document upload and ingestion layer is just as important as the extraction system itself. Improving document quality early can significantly improve accuracy throughout the workflow.
For teams building document-heavy applications, Filestack Capture helps manage secure uploads, mobile document capture, and image optimisation so extraction pipelines receive cleaner and more reliable document inputs from the start.
FAQs
What is a data extraction SDK?
A data extraction SDK is a software toolkit that provides APIs and libraries to help developers automatically extract structured data from documents like PDFs, invoices, IDs, and forms using OCR, machine learning, and validation tools in one system.
How does OCR differ from data extraction?
OCR converts document images into machine-readable text. Data extraction goes further by understanding the document layout, matching labels with values, extracting tables, and turning the information into clean, structured data. OCR is only one part of the data extraction process.
What types of documents can be processed?
Most modern data extraction SDKs support PDFs, including scanned and text-based files, along with JPEG and PNG images, invoices, receipts, ID documents, and forms. However, support for handwritten text and complex document layouts can differ depending on the platform.
How accurate are document extraction SDKs?
Accuracy depends on factors like document quality, layout complexity, and how well the SDK is trained. Clean scanned PDFs with consistent layouts can achieve accuracy above 99%. However, documents with different formats or handwritten content often need confidence scoring and human review to maintain reliable production-level accuracy.
Can data extraction SDKs process handwritten text?
Yes, most modern data extraction SDKs support handwritten text recognition. However, handwriting is usually harder to read than printed text, especially cursive writing, so accuracy can be lower. Many production systems use confidence scoring and human review for low-confidence results to improve reliability.
What industries use document extraction technology?
Financial services, healthcare, legal technology, insurance, e-commerce, and logistics are some of the biggest users of automated document extraction. In general, any industry that handles large numbers of documents and depends on accurate data can benefit from automated extraction systems.
How can extraction accuracy be improved?
The best ways to improve extraction accuracy are image preprocessing during upload, ML-based layout detection instead of fixed templates, confidence scoring for human review, and clean document capture that prevents poor-quality files from reaching the OCR system.
What security features should a data extraction SDK include?
Basic security requirements for document extraction pipelines include encryption during storage and transfer, access controls, audit logs, retention and deletion policies, and compliance standards like SOC 2, HIPAA, GDPR, and PCI DSS for handling sensitive documents.
How do developers integrate extraction workflows into applications?
Most data extraction SDKs offer REST APIs, client libraries for different programming languages, and webhook support for event-based processing. Integration usually involves uploading documents, sending them to the extraction API, processing the structured response, and passing the extracted data to systems like databases, ERPs, or CRMs.
What features should teams look for in a data extraction SDK?
When choosing a data extraction SDK, focus on OCR accuracy for your document types and languages, structured extraction features for the fields you need, flexible APIs and SDKs that match your architecture, and support for both real-time and batch processing. Developer experience also matters. Good documentation, sample apps, and clear error handling can greatly speed up the path from integration to production.
Shefali Jangid is a web developer, technical writer, and content creator with a love for building intuitive tools and resources for developers.
She writes about web development, shares practical coding tips on her blog shefali.dev, and creates projects that make developers’ lives easier.
Read More →