
Extracting text/data from printed or digital documents is a common practice in the business world. However, with technological advancements, businesses are shifting from manual data entry/data extraction to automated data extraction processes. This is where document parsing software and OCR technology come in. These technologies are often used together to automate the process of extracting information from documents. While document parsing and OCR are closely related, they are distinct processes. Thus, it’s essential to know the differences between parsing vs OCR.
In this article, we’ll delve into the basics of OCR and document parsing and the key differences between these two processes. We’ll also discuss how these two technologies are used together to automate the data extraction process.
What is document parsing?

Document parsing is basically the process of extracting structured data from documents. These can include PDF files, Word documents, CSV files, and more. Moreover, document parsing can be used for structured or semi-structured documents, such as:
- Invoices
- ID cards
- Receipts
- Licenses
- Reports
- Forms
- Financial documents and more,
Parsing basically involves analyzing a document and extracting data/information from it. This data can then be stored as a JSON or CSV file, depending on the type of data. However, for parsing to work, we need data in digital/machine-readable form.
This means we can use parsing software to extract data from searchable documents. But what if we want to extract data from printed documents or image-based PDFs automatically? This is where we need OCR. Without OCR, document parsing tools cannot understand the textual content embedded in the images.
Examples of document parsing applications
Document parsing has diverse applications across various industries:
- Invoice processing
- Bank statement analysis
- Loan application processing
- Medical records management
- Insurance claims processing
- Inventory management
What is optical character recognition (OCR)?

OCR is a useful technology that automatically converts scanned PDFs/documents and images into searchable, editable, and machine-readable text. This can include scanned documents that were originally in printed or handwritten format, such as ID cards, invoices, etc.
OCR basically examines the scanned document to identify text (characters and words). Early OCR solutions used pattern-matching algorithms to recognize text in the documents. They had a wide range of fonts and text patterns stored as templates in their databases.
However, these solutions had their limitation, such as:
- Low accuracy
- Limited support for non-standard fonts
- Difficulty in recognizing handwritten text
- Limited capability to handle complex formatting and data types
However, today’s OCR solutions use advanced algorithms and feature extraction to overcome these limitations. They leverage machine learning and neural networks to detect and recognize text with high accuracy. They are capable of detecting a diverse range of handwriting styles and fonts with high efficiency.
Advanced solutions also often have OCR data extraction capabilities based on data parsing.
Some examples of advanced OCR software solutions include:
- ABBYY FineReader PDF
- Filestack OCR
- Amazon Textract
- IBM Watson
Common use cases of OCR
- Document digitization
- Document management
- Enhanced searchability
- Automated data entry
- Digitizing textbooks
Differences between document parsing and OCR
The table below highlights the key differences between document parsing and OCR technology (parsing vs OCR):
| Document Parsing | OCR | |
| Purpose | Used to extract text/specific information from documents, such as PDFs, Word documents, etc. | Converts scanned documents into searchable, editable, and machine-readable formats.
Advanced OCR systems also have data extraction capabilities. |
| Input | Digital and searchable documents | Scanned documents or images containing text |
| Process |
|
|
| Technology |
|
|
| Output | Structured data, such as JSON, XML or CSV files. | Plain text or searchable PDF |
Choosing between parsing vs OCR for data extraction depends on several factors, such as:
- The type of the PDF/document
- The type of data you want to extract
- Required accuracy and speed
- Available resources or tools
It’s best to use OCR when:
- You want to extract data from scanned documents or image-based PDFs
- Extracting text and preserving formatting and layout are preferred.
It’s best to use document parsing when:
- Dealing with native or digital PDFs.
- Extracting structured or semi-structured data
Combining document parsing and OCR
Integrating document parsing and OCR can help automate the process of extracting data from documents.
Here’s how we can combine both technologies:
- Use OCR to convert scanned or image-based documents into machine-readable text.
- Apply document parsing techniques or use a document parser to analyze the digitized text, extract structured data, and interpret the document’s content.
- Store the extracted data in your desired file format, such as JSON, Excel, CSV files, etc.
- Validate extracted data against predefined rules or databases.
Examples of systems utilizing both OCR and document parsing
Invoice processing systems
A system for processing invoices automatically can combine OCR to convert scanned invoices into machine-readable format. It can then use document parsing to identify and extract key invoice details such as vendor name, invoice number, date, and line items.
This integration streamlines invoice processing by automating data extraction and validation.
Identity verification systems
Identity verification systems can use OCR to convert documents, such as ID cards and passports, into digital format. They can then extract key information using document parsers. This can include name, country, date of birth, address, etc.
Document management systems
Document management systems can utilize OCR to digitize documents upon upload. OCR will help make these documents searchable, allowing users to retrieve documents based on content.
Document parsing can further enhance these systems by categorizing documents, extracting metadata, and facilitating content-based search.
OCR data extraction with Filestack
Filestack is a leading cloud-based file management solution. It provides a complete set of tools and APIs for:
- File uploading
- Online file delivery through CDN
- File transformation
Filestack also offers intelligence services, such as OCR, image tagging, and sentiment detection through its Processing API.
Filestack’s OCR uses machine learning algorithms and neural networks for accurate text recognition. It is backed by an advanced digital image analysis system that detects features character by character. Filestack OCR also leverages sophisticated document detection and pre-processing solutions for enhanced accuracy. It can efficiently detect complex documents, such as rotated, wrinkled, or folded documents.
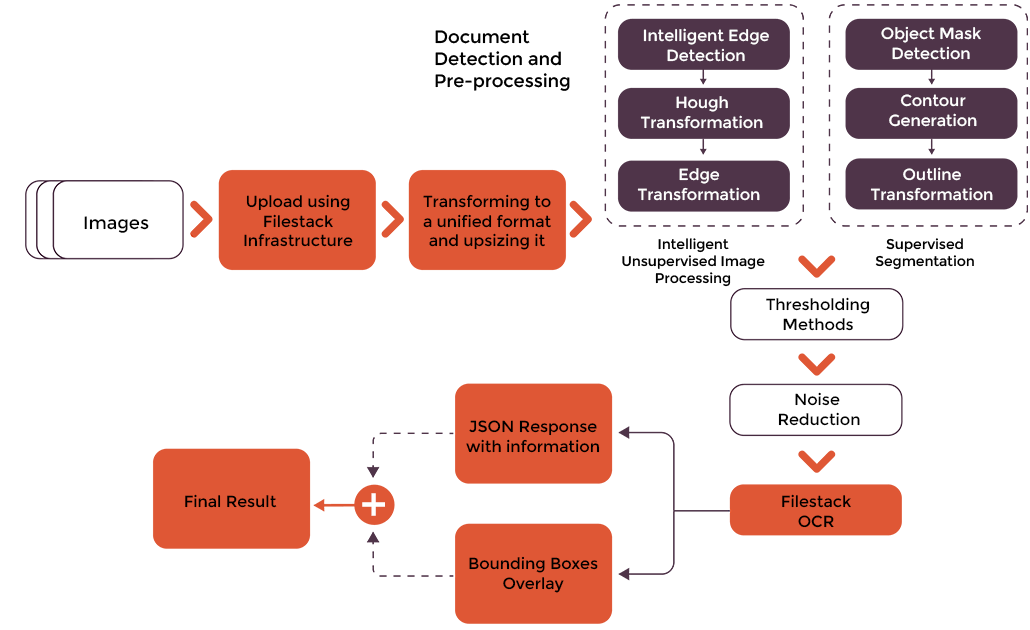
You can use the Filestack OCR engine to extract text from various document types, such as:
- Business cards
- Receipts
- Invoices
- Driver’s licenses
- Credit cards
- ID cards
- Tax documents
- Passports, and more.
Integrating Filestack OCR: Code Snippets
You can integrate Filestack into your apps using a suitable SDK. Filestack offers various SDKs, such as:
- JavaScript SDK
- React SDK
- Angular SDK
- iOS and Android SDKs
To use Filestack, you first need to sign up and create a Filestack account. You can then find your API key in your Filestack dashboard.
Here’s how you can integrate Filestack File Picker/Uploader using JavaScript SDK:
<script src="//static.filestackapi.com/filestack-js/3.x.x/filestack.min.js"></script>Next, configure the client with your API Key. Here is how to open the default File Picker:
const client = filestack.init(YOUR_API_KEY);
client.picker().open();Output:
You can also configure a list of services you want to display for users to choose files from:
const client = filestack.init(YOUR_API_KEY);
const options = {
fromSources: ["local_file_system","instagram","facebook"],
};
client.picker(options).open();You can now use this uploader to upload your scanned documents or images for OCR. Filestack provides a CDN URL for all the uploaded files. You can use this URL to perform OCR or deliver files.
You can use the following URL for OCR:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/ocr/<HANDLE>Conclusion
Document parsing means analyzing the structure and content of a document to extract specific information or data fields. OCR is an advanced technology that converts scanned paper documents and PDF files into editable and searchable text. Document parsing and OCR are both used together to automate data extraction from documents. They can be used for invoice processing, automated data entry, identity verification, document digitization, and more.
FAQs
What is OCR in parsing?
OCR plays a crucial role in the parsing process. Many documents that need to be parsed are initially in image formats or scanned copies. This makes the text inaccessible for direct analysis. OCR technology helps extract the text from these documents by converting them into digital text.
What is the difference between parsing and OCR (parsing vs OCR)?
Parsing refers to extracting text from documents. OCR helps convert scanned documents into searchable and editable text.
What is OCR used for?
OCR has a wide range of use cases, such as:
- Document digitization
- Document management
- Automated data entry
- Digitizing textbooks
Sign up for Filestack free today and integrate its accurate OCR API into your apps!

Sidra is an experienced technical writer with a solid understanding of web development, APIs, AI, IoT, and related technologies. She is always eager to learn new skills and technologies.
Read More →