
If you’re a React developer, you’re probably using React 18, the latest major version of the React framework, to build your web apps. Ever since React 18 was released (back in 2022), it has been making waves among front-end developers with its new features and enhancements. These include automatic batching, streaming server-side rendering, suspense on the server, and the introduction of new APIs like createRoot and startTransition. These features play a significant role in creating more responsive UIs and optimizing the app’s performance.
Now, if you’re looking to create a modern React web app that requires features to automatically extract text from different documents, using an OCR SDK compatible with React 18 can be a great option. OCR is an advanced technology that automatically extracts text from various types of documents. It converts scanned documents (printed or handwritten), images, or PDFs into editable and searchable documents.
Using an OCR SDK for your React 18 app will allow you to integrate advanced OCR features directly into your app without developing them from scratch while enjoying React 18’s new and enhanced features.
This article will explore the core concept of OCR data extraction. We’ll also delve into various aspects of integrating OCR data extraction in React 18 applications.
Understanding OCR (Optical Character Recognition) algorithms
OCR is a technology that automatically converts a scanned document or an image (containing text) into an editable and machine-readable format. For instance, if you have a printed invoice and you want to extract information from it, you can use OCR. You’ll just need to scan the invoice and provide the scanned image as input to the OCR engine or software. The OCR software will then automatically extract information for the invoice, reducing errors and saving time and effort.
Early OCR solutions used pattern or template-matching algorithms to compare text in images (character by character) to various patterns saved in their internal database. In other words, these solutions stored a range of fonts and text patterns as templates in their internal database. The OCR engine then compared text, character by character, to its internal database using template-matching algorithms. However, these solutions weren’t very accurate as they could not detect all types of fonts and handwriting styles.
Today’s advanced OCR solutions leverage sophisticated machine learning algorithms and neural networks. These algorithms are trained to extract text like humans do, detecting a diverse range of fonts and handwriting styles. These algorithms analyze various image features, including loops, curves, intersections, and lines. They then combine all these results to provide a final and more accurate result.
Also read: Top 5 OCR use cases
Pre-processing images for OCR
Pre-processing images can significantly improve OCR data extraction accuracy. Modern OCR solutions come with built-in pre-processing features. However, users can also apply various image enhancement techniques to improve the quality of the image.
Common image pre-processing techniques for OCR include:
Deskewing
This technique is used to fix the alignment of the scanned document by tilting it a few degrees, clockwise or counterclockwise, as needed.
Despeckle
Despeckling involves smoothing the edges of scanned images or removing digital/ positive and negative spots.
Cleaning up Lines
Many documents contain lines and boxes in the form of tables, borders, and section lines. Cleaning up the lines and boxes in a scanned document enhances the document’s layout and structure. Thus making it clearer for improved OCR text extraction.
Image binarization
Image binarization involves converting an image into a binary or black-and-white image. This helps distinguish the text in the image from the background, making it easier for the OCR engine to detect and recognize text.
These techniques are often a part of advanced and reliable OCR solutions. However, if you’re looking to extract text from a poor-quality image, you can also apply image enhancement techniques. These include upscaling, cropping, resolution enhancement, etc.
Text recognition in OCR
Text recognition in OCR is done using algorithms. Pattern matching and feature extraction are the two main types of OCR algorithms for OCR data extraction.
As aforementioned, pattern matching involves storing different fonts and text patterns in the OCR software’s database. The OCR engine isolates a character, also called a glyph, and then matches it to its database. However, it’s almost impossible to store all types of fonts and handwriting styles in the database. Thus, pattern-matching isn’t very accurate.
Feature extraction divides a character into various features. These include loops, lines, and line direction and intersections. It then uses advanced machine learning algorithms and neural networks to find the best match for the character based on its features. Hence, this method recognizes text more efficiently.
When implementing OCR in your React 18 apps, it’s best to use feature extraction algorithms. This will ensure you get highly accurate OCR data extraction results. While you can develop OCR features from scratch, it’ll be time-consuming. Moreover, training machine learning algorithms is also challenging and resource-intensive. Fortunately, OCR APIs and SDKs are available that developers can integrate into their apps to implement advanced OCR features directly. When choosing an OCR solution for your React app, ensure it’s compatible with React 18 and offers the necessary OCR features.
Data parsing and extraction
Once the OCR recognizes text, the data is available in the form of characters. Data parsing converts these characters into meaningful data, such as words and sentences. In other words, it organizes the recognized characters in a structured form. The OCR software then converts the extracted data into a PDF or other computerized file.
OCR data extraction can be used in React 18 applications for various purposes. For instance, you can enable users to upload a scanned document or image. You can then use OCR to extract text from these images and populate form fields automatically. This significantly enhances the user experience. You can also use OCR to extract data from various scanned documents and visualize it in the form of interactive graphs and charts. Moreover, you can use OCR to implement search functionality within documents or scanned images in your React 18 app.
A solution
Filestack OCR
Filestack offers a complete set of tools and APIs for efficient file uploading, delivery, and transformation. It also offers a specialized React SDK, which supports all of Filestack’s impressive file management features. These include:
- File uploader
- Online file delivery through CDN
- File transformation through Processing API
- Filestack intelligence services, such as image tagging, sentiment detection, and OCR, through Processing API
The best thing about Filestack React File Upload SDK is that it is updated for React 18. This means developers can now integrate Filestrack’s powerful file uploading and OCR features in their React apps while enjoying React 18 features. This update ensures seamless integration of the React SDK into your React 18 apps.
OCR Features
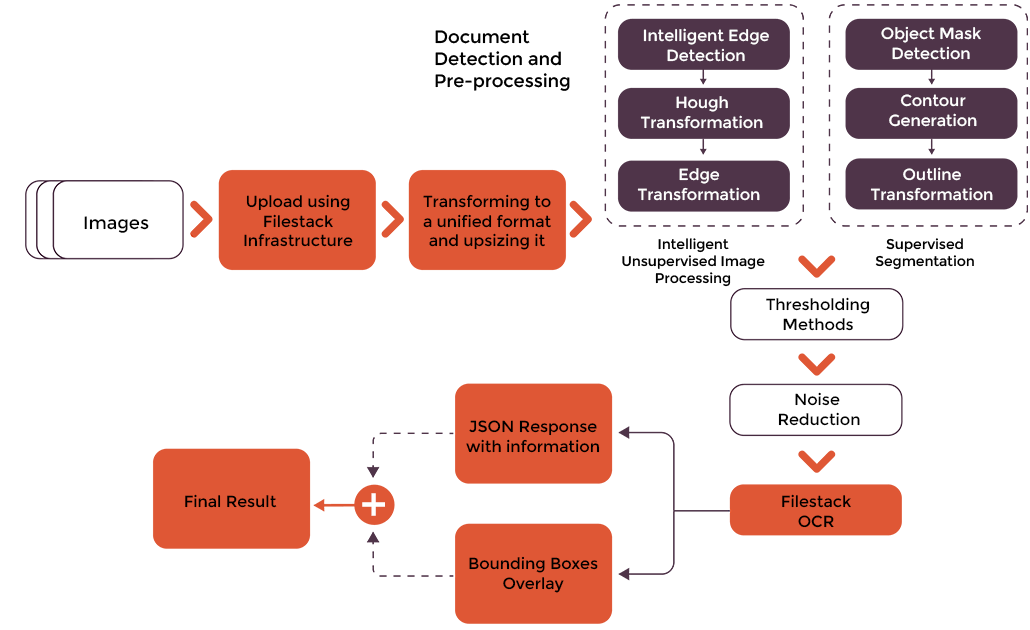
Filestack’s OCR leverages machine learning and neural networks for accurate OCR data extraction. It features a robust digital image analysis system to detect features character-by-character and translate these characters into specialized identification codes. Moreover, Filestack OCR utilizes advanced document detection and pre-processing solutions for high accuracy. The OCR engine can efficiently detect complex documents, such as wrinkled, rotated, or folded documents.
You can use the Filestack OCR API to extract data from various types of documents, such as:
- Invoice
- Business cards
- Driver’s licenses
- ID cards
- Credit cards
- Receipts
- Various types of financial documents
- Tax documents
- Passports, and more.
Integrating Filestack in React Apps
You can integrate Filestack into your React app using Filestack React SDK. To use Filestack services, you first need to sign up and create a Filestack account. Once you have your API key (available in your Filestack dashboard), here’s how you can integrate Filestack into your React app:
1) Install the SDK
npm install filestack-react2) Integrate the Filestack PickerOverlay component into your React 18 app
import { PickerOverlay } from 'filestack-react';
<PickerOverlay
apikey={YOUR_API_KEY}
onSuccess={(res) => console.log(res)}
onUploadDone={(res) => console.log(res)}
/>You can then upload your scanned documents or images using Filestack File Uploader. Once a file is uploaded, Filestack instantly returns a CDN URL that you can use to deliver files or perform OCR. To perform OCR, you can use the following URL:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL/CDN URL> .Sign up for Filestack and integrate its powerful OCR in your React 18 apps today!
Big data analysis with OCR in React 18
Developers can integrate OCR in data-driven apps for big data analysis. They can leverage OCR data extraction features while harnessing React 18’s advanced features, such as dynamic rendering, to process large volumes of data. They can visualize the extracted data in the form of interactive charts and graphs.
Conclusion
OCR is a powerful technology that converts scanned documents and images into machine-readable and editable formats. Moreover, it accurately extracts data from various types of documents, automating the data extraction process. When implementing OCR features in React 18 apps, it’s best to choose an OCR SDK or API that is compatible with React 18. This will allow for seamless integration while enabling you to leverage React 18’s powerful features.
Sidra is an experienced technical writer with a solid understanding of web development, APIs, AI, IoT, and related technologies. She is always eager to learn new skills and technologies.
Read More →