



In today’s blog, we’re delving into the world of Filestack OCR. It is an essential tool for developers that makes text extraction from images super easy. Moreover, it can simplify OCR integration into your web applications. Optical Character Recognition helps computers understand text in images. Think scanned documents, photos of text, or even screenshots. OCR makes all that text accessible and usable.
Now, onto Filestack OCR API. It’s like a super-smart assistant that recognizes text in images and hands you back the essential details. We’ll guide you step by step on how to use it. But wait, there’s more! We’ll show you how to create Filestack OCR workflows. We will also break down the logic and parameters. For seamless integration into your apps, we’ll cover Filestack OCR Webhooks.
Let’s continue reading this article till the end.

Why do you need OCR?
Ever had a photo or a scanned document with words, and you wished your computer could understand them? That’s where OCR, or Optical Character Recognition, comes in.
Imagine you have an old paper document, a photo of a recipe, or a screenshot with text. Your normal application can’t really “see” the words in those pictures. But with OCR, it’s like giving your application special glasses to read the text.
✔️So, why do you need OCR? Because it helps your website or application understand words in images. This is super useful for businesses dealing with lots of paper documents. OCR turns those paper files into digital ones. As a result, it also makes everything faster and more organized.
OCR helps turn scanned textbooks or handwritten notes into digital text in education. It’s like turning pictures of words into something your computer can work with. OCR is also great for disabled users. It can enhance the accessibility of your web app. It makes text in images accessible by converting it into readable formats.

What is Filestack OCR API?
Filestack Capture is a robust document digitization service. It employs advanced digital image analysis to identify printed text characters and image qualities. The OCR engine meticulously examines features character by character. As a result, they into specialized identification codes.
✔️Boost your document processing and organizational efficiency securely with Filestack OCR. It minimizes errors in data extraction.
✔️Whether it’s OCR for W2s, credit cards, business cards, invoices, receipts, driver’s licenses, IDs, passports, images, or general documents, Filestack OCR has you covered.
Our OCR service is designed to scale effortlessly according to your business needs. Our OCR SDK can handle your data extraction requirements for large or small businesses.
Accuracy is our forte. Filestack employs Artificial Intelligence and Machine Learning for image and form reading recognition. This helps us reduce the risk of errors in data entry.
Efficiency is paramount. Say goodbye to manual data processing hassles. Filestack OCR easily integrates with your website or application. As a result, it allows for quick uploads and precise data entry. It functions with high efficiency irrespective of the coding language you use.

Response parameters generated by Filestack OCR
OCR is Filestack is available as a synchronous operation. You can use it through the “ocr” task.
Here is an example of a response by Filestack OCR. We have listed Filestack OCR response parameters in the table given below:
"text": "Filestack can detect",
"words": [
{
"bounding_box": [
{
"x": 957,
"y": 490
},
{
"x": 1833,
"y": 580
},
{
"x": 1802,
"y": 888
},
{
"x": 925,
"y": 797
}
],
| Field | Description |
| document | Contains detailed information regarding the OCR response. |
| text_areas | Consolidates extracted details related to text blocks, including their bounding boxes. |
| lines | Enumerates identified text lines along with corresponding bounding boxes. |
| bounding_box | Records coordinates for identified text blocks, lines, or words. |
| text | Holds the extracted text content found within blocks, lines, or individual words. |
| text_area_percentage | Represents the percentage of the image covered by text. |

How do you use Filestack OCR API?
Using Filestack OCR API is simple. Retrieve the OCR response for your image using the following URL format:
1. For image uploaded directly:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/ocr/<HANDLE>2. Integrate OCR with other tasks like document detection in a sequential manner:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/doc_detection=coords:false,preprocess:true/ocr/<HANDLE>3. Utilize OCR on an external URL:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL> 4. Apply OCR to images stored using Storage Aliases:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<STORAGE_ALIAS_URL> How do you create Filestack optical character recognition workflows?
First, create an account at Filestack.
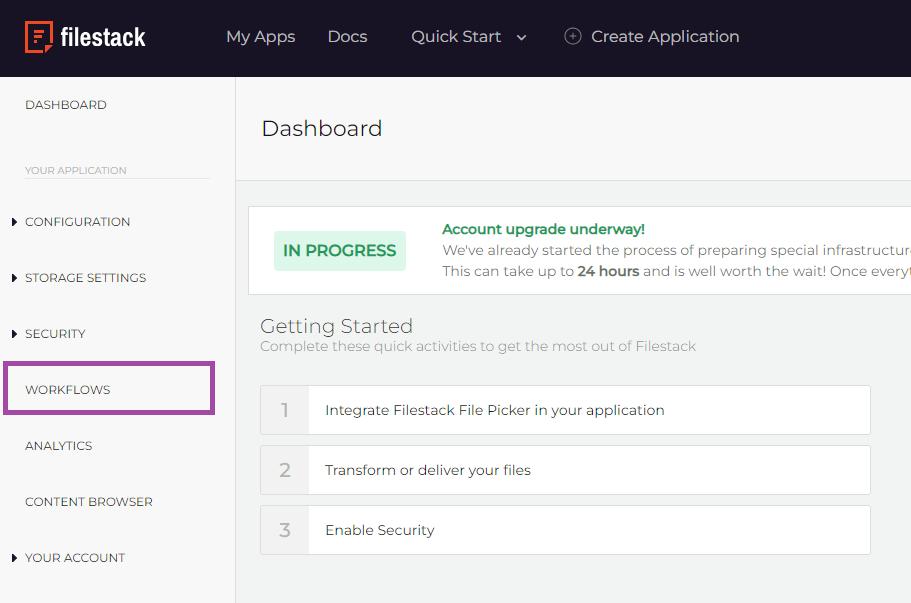
Navigate to the workflows after signing in to your account.
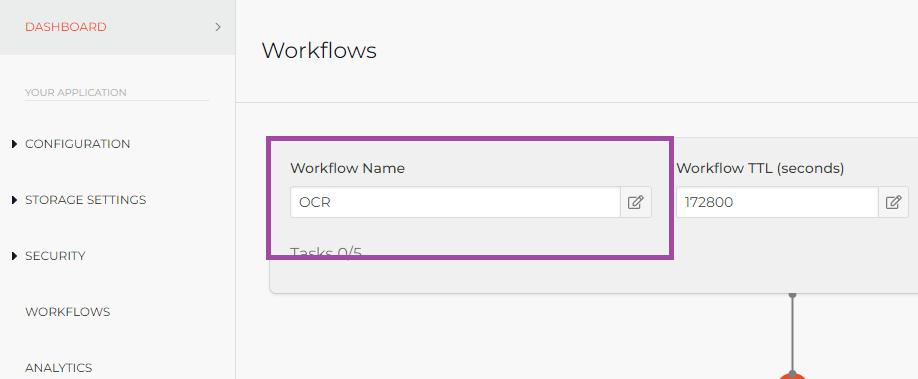
Rename your workflow as follows:

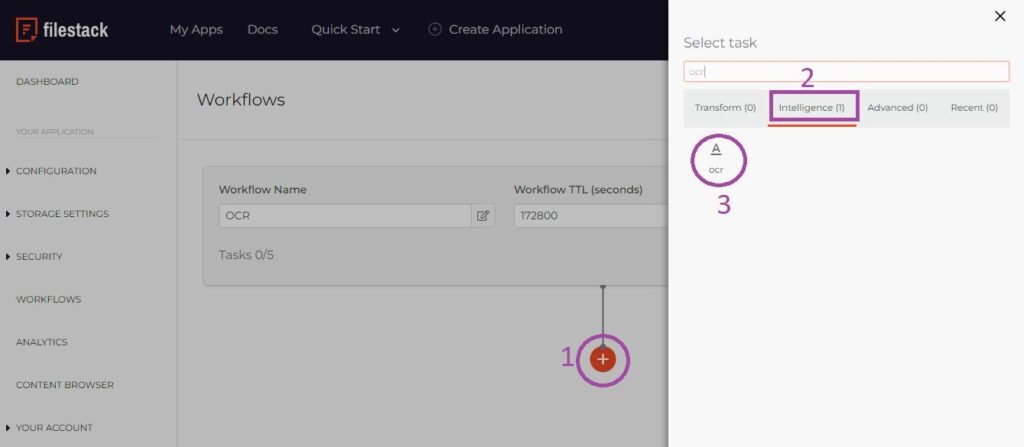
Follow the below steps to add OCR and click on save.


Then, you can copy the below configuration and add it to your app’s code:
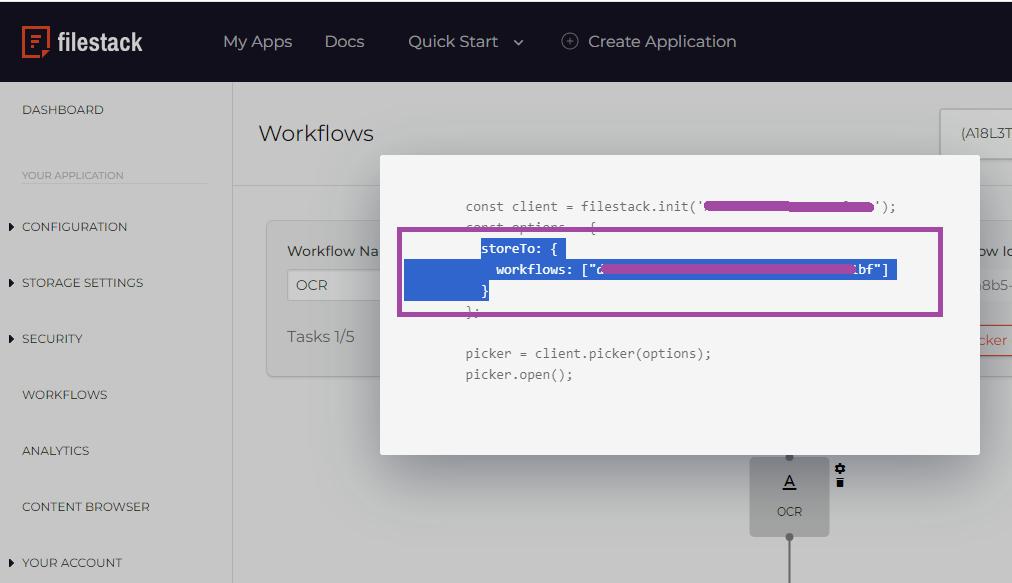

Let’s suppose we upload the below image:

We get the following response:
{
"id": 317133172,
"action": "fs.workflow",
"timestamp": 1704789482,
"text": {
"workflow": "d50ca8b5-90e9-4340-a493-64e9bdcc71bf",
"jobid": "3812550a-4535-4253-a6d3-261c8c0d8c7b",
"createdAt": "2024-01-09T08:37:25.528124281Z",
"updatedAt": "2024-01-09T08:37:26.658502646Z",
"sources": [
"7lbnNWYeT3yIhUsDrIPQ"
],
"results": {
"ocr_1704787922489": {
"data": {
"document": {
"text_areas": [
{
"bounding_box": [
{"x": 81, "y": 106},
{"x": 1272, "y": 106},
{"x": 1272, "y": 207},
{"x": 81, "y": 207}
],
"lines": [
{
"bounding_box": [
{"x": 81, "y": 106},
{"x": 1272, "y": 106},
{"x": 1272, "y": 207},
{"x": 81, "y": 207}
],
"text": "OCR with Filestack",
"words": [
{"bounding_box": [{"x": 81, "y": 106}, {"x": 349, "y": 106}, {"x": 349, "y": 207}, {"x": 81, "y": 207}], "text": "OCR"},
{"bounding_box": [{"x": 388, "y": 106}, {"x": 654, "y": 106}, {"x": 654, "y": 207}, {"x": 388, "y": 207}], "text": "with"},
{"bounding_box": [{"x": 709, "y": 106}, {"x": 1272, "y": 106}, {"x": 1272, "y": 207}, {"x": 709, "y": 207}], "text": "Filestack"}
]
}
]
},
{
"bounding_box": [
{"x": 423, "y": 575},
{"x": 453, "y": 575},
{"x": 453, "y": 584},
{"x": 423, "y": 584}
],
"lines": [
{
"bounding_box": [
{"x": 423, "y": 575},
{"x": 453, "y": 575},
{"x": 453, "y": 584},
{"x": 423, "y": 584}
],
"text": "HTML"
}
]
},
{
"bounding_box": [
{"x": 509, "y": 376},
{"x": 574, "y": 378},
{"x": 573, "y": 412},
{"x": 508, "y": 410}
],
"lines": [
{
"bounding_box": [
{"x": 509, "y": 376},
{"x": 574, "y": 378},
{"x": 573, "y": 412},
{"x": 508, "y": 410}
],
"text": "PHP"
}
]
},
{
"bounding_box": [
{"x": 497, "y": 436},
{"x": 524, "y": 436},
{"x": 524, "y": 441},
{"x": 497, "y": 441}
],
"lines": [
{
"bounding_box": [
{"x": 497, "y": 436},
{"x": 524, "y": 436},
{"x": 524, "y": 441},
{"x": 497, "y": 441}
],
"text": "www."
}
]
}
],
"page_height": 768,
"page_width": 1366,
"text": "OCR with Filestack\nHTML\nPHP\nwww.",
"text_area_percentage": 11.715699731576379
},
"status": "Finished",
"ttl": 172800
}
}
}
}
}
Optical Character Recognition: Conclusion
Filestack OCR helps easily extract text from images. Whether scanned documents, pictures of text, or screenshots, Filestack OCR turns them into usable words. It’s accurate and works well for documents like W2s, credit cards, etc. Plus, it’s user-friendly and fits any business size.
Creating workflows with Filestack OCR is also the simplest. We performed the process in the above article and showed you the output. Follow the steps, and your app will read text from images quickly.
Optical Character Recognition: FAQs
Why should you choose Filestack OCR?
Filestack OCR ensures easy text extraction, accuracy, and seamless integration.
Can I try Filestack optical character recognition for free?
Filestack may offer a free trial for their Optical Character Recognition services. However, pricing and trial offerings can change.
What are the features of Filestack OCR?
Filestack OCR features effortless text extraction, high accuracy with AI, seamless integration, diverse document support, and scalable solutions for businesses.
Can I integrate Filestack OCR into my application?
You can integrate Filestack OCR into your application. It will help you enable easy text extraction and enhance functionality.




Ayesha Zahra is a Geo Informatics Engineer with hands-on experience in web development (both frontend & backend). Also, she is a technical writer, a passionate programmer, and a video editor. She is always looking for opportunities to excel in her skills & build a strong career.