Overview
In late 2018 when we released the Document Detection service at Filestack, no one anticipated it to become an essential intelligence task alongside OCR. If you are working with images that contain documents inside, it’s essential to find your document in the image by detecting the edges and border of the document, transforming its perspective angle to fit the largest possible rectangle, reducing its distortion, enhancing the quality, and making a perfect document. This way, other intelligence tasks such as OCR engine can be able to extract the text with maximum possibility out of your image. For example running:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/doc_detection/<HANDLE>
in your web browser with configured security values and your image handle would trigger Document Detection service to find, transform, and preprocess your document. Following references can be helpful in order to deep dive in this service and learn how to use it using Filestack Processing API or Workflows.
Resources:
- Document Detection Documentation
- Blog: Document Detection, Enhancement, and Preprocessing API
- Blog: Document Detection: An Intelligence Task for Intelligent Applications
- Filestack Security
Latest Update
Based on the demands of our customers, we decided to add multiple endpoints to the latest update of our Document Detection service. This way, you would have more degrees of freedom in leveraging it in your business. We also added two more inputs to this intelligence task so that by defining them, the final result would be different. Figure 1 shows a simple pipeline of Document Detection with different outputs.
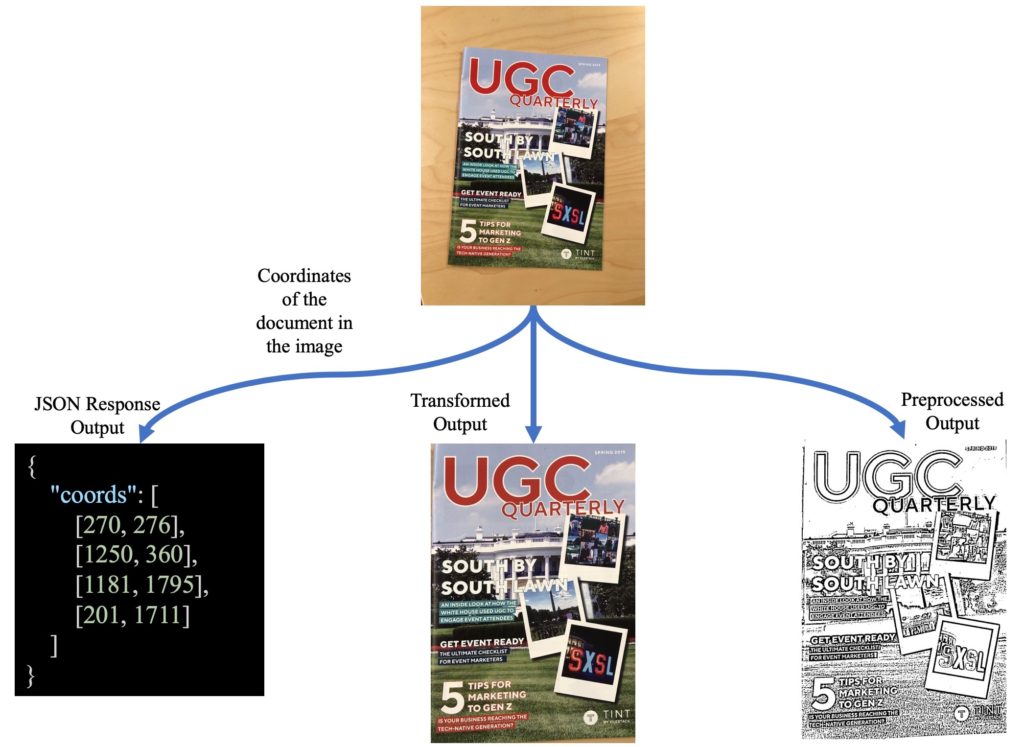
New Pipelines
Document Detection now has two new input parameters; coords and preprocess, and depending on these parameters, the output result would vary. This service can have up to three different pipelines as follows:
- Detect the document in the actual image and return its coordinates
- Detect the document in the image, find the coordinates, transform the document based on its corners to fit the largest rectangle, also known as warping.
- Detect the document in the image, find the corners, warp the document, and apply preprocessing filters to make it cleaner for OCR.
Three above-mentioned pipelines can occur by defining the following parameters.
/doc_detection=coords:Boolean/
This parameter is Boolean, i.e. it can only accept two values; True or False. The default value of this parameter is set to false. When this parameter is true, the first pipeline is followed, which means Document Detection service would find the document in your image and return the coordinates of four edges belonging to the document. When this parameter is true, the output would be a JSON response containing four pairs of (x, y) in an array, for example:
[ [97, 112], // coordinates of top left edge [1340, 87], // coordinates of top right edge [1928, 1125], // coordinates of bottom right edge [165, 1438] // coordinates of bottom left edge ]
These four coordinates represent each corner of the document in the actual image. For instance, bottom left edge, upper left edge, upper right edge, and bottom right edge (sorting in a clockwise order) would be represented. When coords is false, then the service would return an output image depending on preprocess parameter.
/doc_detection=preprocess:Boolean/
Like the first parameter, “preprocess” is also a Boolean parameter with two possible values: true or false. The default value to this parameter is set to True. If this parameter is false, then the second pipeline is followed. The output would then be detected as the document in the image and transformed to fit the largest circumscribed rectangle to fix the angles in the image. Setting this parameter to true would cause the service to follow the third pipeline which is returning the detected document in the image after being warped and preprocessed.
How to use Document Detection
Following our instructions for using Document Detection, you can either use Processing API or Workflows tasks. In order to use this service in Processing API, you should run the following template in your web browser with proper values followed by your image handle:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/doc_detection=coords:<TrueOrFalse>,preprocess:<TrueOrFalse>/<HANDLE>
Hint: It is essential to know that if you do not provide either of these parameters, the default values (coords=False and preprocess=True) would be set.
Examples
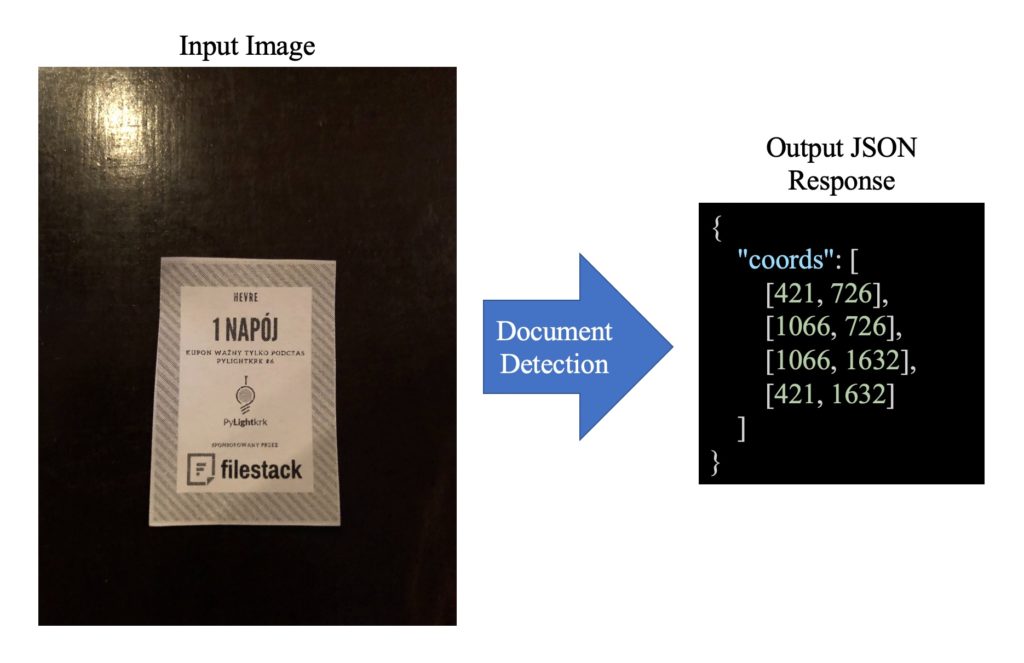
Following examples show different outputs of Document Detection.
Hint: If there is no document in the image, then the service would return “None” as the coordinates and the input image and its preprocessed as the visual results.





Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.
Read More →