
Creating software for Education Technology (EdTech) comes with specific challenges. First, it requires strong security to protect student data. Additionally, it needs reliable performance, so everything runs smoothly, and always-on access, which means users can get to it anytime. Moreover, accurate data is crucial for making informed decisions.
However, EdTech teams often face obstacles. They usually work with small groups of people, tight deadlines, and limited budgets. As a result, they might have to delay important features or hire less experienced developers.
In this situation, special tools called Application Programming Interfaces (APIs) can really help. APIs streamline complex tasks, allowing teams to focus on what matters most and meet their goals effectively.
With reality pushing back against project goals, how can we break free and build amazing experiences in this space?
Key Takeaways
- Specialized APIs help EdTech teams overcome resource limits, such as small budgets and tight deadlines.
- These tools simplify file management by making it easy to handle diverse file types like images, documents, and videos.
- The system automates optimization by automatically resizing images for fast web loading on any device.
- You can integrate multiple sources, which allows users to upload files directly from Google Drive, Instagram, and more.
- It is possible to ensure scalable security by implementing content moderation and virus scanning for public uploads without extra coding.
Who Has the Time?
While educational institutions may allocate funds for technology, dedicating internal resources to manage the full spectrum of IT operations, particularly for file management infrastructure, can be inefficient.
Cloud services, API-based integrations, and Software as a Service (SaaS) models allow EdTech projects to delegate specialized tasks, such as file uploading, storage, processing, and delivery, enabling development teams to concentrate on core educational functionalities.
Evaluating In-House vs. Specialized Services
Schools and educational institutions usually have good IT resources, which include servers and virtual spaces for different academic projects. They often have skilled workers to handle complicated technical tasks. However, there are certain specialized needs that can be hard to meet with their regular in-house resources. These include things like scalable file storage, the ability to change file formats, advanced content moderation (like identifying inappropriate content), and a global network to deliver content efficiently.
Therefore, using a dedicated file handling API like Filestack can be very helpful. It provides these essential features right away, so institutions can focus on their main educational goals instead of spending time and effort to build and maintain a large file management system.
Technical Scenario: Managing Student-Generated File Uploads
EdTech platforms handle different types of files created by students, like images (JPEG, PNG, HEIC), documents (PDF, DOCX, XLSX), and videos (MP4, MOV). To manage these files correctly, several important steps are necessary.
First, the system needs to give each uploaded file a unique identifier, or file handle. This helps track versions, edits, and changes easily. Next, the system should gather information about the files, called metadata, to keep them organized. However, if privacy is a concern, it’s important to remove this metadata before sharing the files.
Additionally, it’s best to store uploaded files in a cloud system instead of the app’s local storage. This choice improves reliability and prevents slow performance. By following these steps, EdTech platforms can manage files more effectively.
Modern digital cameras and smartphones create high-resolution images that are large in size.
While these images are great for storage, they may not be suitable for display on the web, as they can slow down loading times and use up too much bandwidth. For effective web use, it’s important to optimize images by resizing, compressing, and converting them to formats like WebP or AVIF.
Let’s look at one example of students uploading files: imagine a project where they document how a museum captures and archives old written items. Think about pieces of papyrus, old books, or clay tablets with ancient writing, and let’s explore the challenges involved.
Preserving History: An Adventure in Uploads
Students are at the museum, working with their team to preserve history. They take high-resolution photos, shoot videos, and have fun in the process. Meanwhile, back on campus, the IT and Media departments set up a website to share this project.
First, the students transfer the high-resolution photos from an SD card. Then, they prepare to upload copies to the project website. Next, the IT and Media departments will implement the necessary steps to handle this project effectively.
Hello, IT
The IT team creates a virtual machine at our fictional University using their own hardware. Then, they set the DNS for the .edu domain so that it connects to this virtual environment. Next, they set up a database and consulted the Media department about their storage needs. The media team responds, “We’re not sure yet; be ready for anything!” In response, the IT team sets up an S3 container, which allows storage to grow as needed. Finally, all the pieces are in place for the system to work smoothly.
Design
The site is set to start development. At the same time, a designer checks the organization’s design rules and creates the site’s appearance and style. Additionally, they work together to ensure everything matches.
Front End Development
A Front-End Developer takes these designs and builds them out in an HTML page. In a private page intended only for the students, they drop in the Filestack File Picker with a few lines of JavaScript and then style the upload button to match the look and feel of the site.
Back End Development
A back-end developer creates public-facing routes to serve the project’s pages and puts together an admin login system with private routes for students (and only students) to upload their images. Each user ID of each student will be associated with the handle of each uploaded file in the database.
They create an endpoint to consume webhooks from the upload process. The data received from this webhook will be used by the back-end developers for conditional logic and to associate the file handles with the users in the database.
Ready, Set, Upload!
Students are exploring the new website. First, they log in using their accounts and see a special File Picker. Then, they insert the SD card into their laptops. Next, they open the File Picker and find the card to select and upload high-resolution photos from the museum’s cameras. The photographers take both RAW and JPG files; however, the students only need the JPG files for the website. Although these files are large, the students don’t need to worry about their size. So, they can just upload the JPG images, and that’s it.
After that, the website automatically resizes and compresses the uploads. This means the students do not have to do anything extra! When they upload the large JPG images, the files go into a storage area controlled by the University called an S3 bucket. Finally, the web team has logged into the Filestack Developer Portal and set up their account to use their S3 bucket instead of the usual default storage that comes with Filestack.
Displaying the Uploads
How do we display all of these uploads? We should probably set up a batch process to create multiple image sizes from each source image for display on the web, right? Well, hold on now, it’s 2025 and there’s a better way. Filestack offers an open-source drop-in solution for responsive images. This solution uses the Filestack API to smartly choose the best image for any required size. Cell phones, tablets, desktops, laptops… Every browser and size will receive the best web-ready version of the photos by wiring up this solution.
A Wild Challenge Appears
Let’s take our example case to an extreme. The project is growing, and unforeseen challenges arise, as is the way of the world.
Students have started using Dropbox and Google Drive to save their Excel files. In these files, they track their work. Additionally, they use their cell phones to take pictures of each other while working on the project. Afterward, they upload these photos to Instagram and Facebook to share their progress. The students are filming videos of each other to talk about their work. Meanwhile, the Media department is beginning to notice this. So, Media asks the developers, “What do we need to do to add these behind-the-scenes photos from the students to the site?”
The developers smile and explain, “We’re using Filestack: it’s already done.”
Filestack’s File Picker allows uploads from Instagram, Facebook, Dropbox, Google Drive, and more by default. Students simply select Instagram, for example, and authorize their Instagram account to pick any images to upload to the site.
Furthermore, the Filestack Document Viewer can display Excel files directly in the browser. Even better, you can convert these files to PDF, PNG, or JPG with zero code. Simply use a file conversion URL to request the format you need.
Then, one day, the project leaders had an idea. They’re going to crowd-source file uploads from the public around the world in a global search for related content. During the archival of these old documents, they’ve discovered evidence of an ancient global trade network, and they want to see if anyone around the world can provide additional clues.
At the same time, the university leaders pay attention to the project’s increasing popularity. As a result, they establish some business requirements for what should happen to all files.
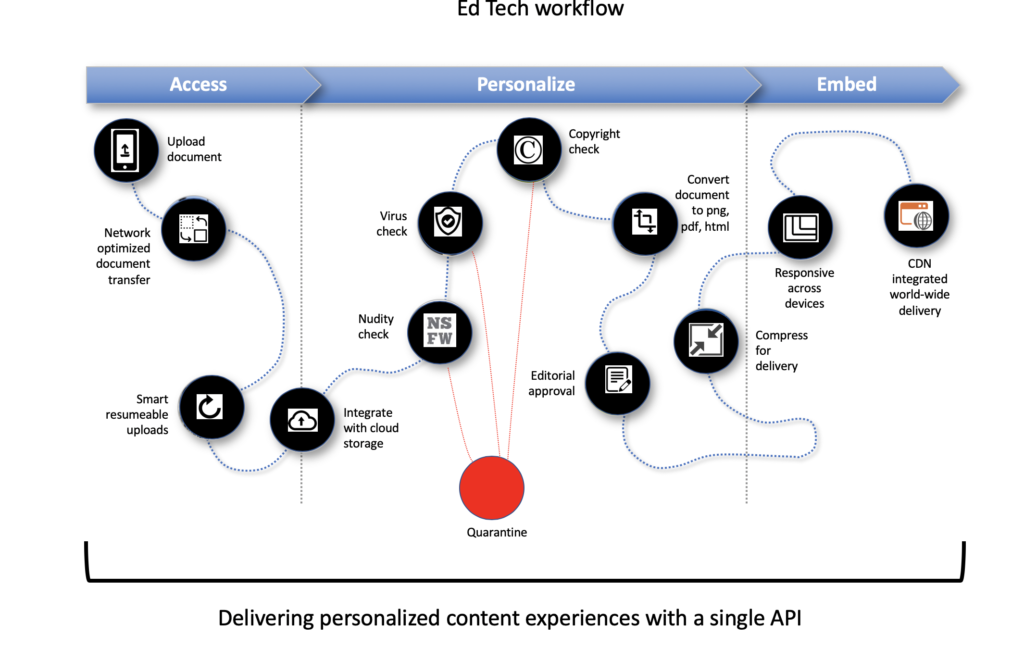
Uh-Oh… Now what?
Finding out that you already have what you need feels great. In our project, we talked about an idea that might often get rejected without enough money, development resources, and time. This idea involves asking people to upload files to a site that started small.
Luckily, we don’t need to change our system to make this work. The File Picker can be shown to users outside our team, allowing them to upload their images from any source they prefer.
However, we need to be cautious. After all, file uploads from strangers could lead to issues. What if pranksters or criminals try to misuse the system? Therefore, we should filter these uploads to make sure no NSFW images or harmful files with viruses or malware get through. Fortunately, we can manage that.
Filestack offers an SFW (Safe For Work) check and a Virus Detection service, and both can be dropped into any project without any additional development work by creating tasks visually in the Workflows editor. The example project we’re talking about here already receives webhooks, so we just ask the Front-End Developer to add one line to the JavaScript that displays the picker. That line specifies the unique ID of the Workflow, and everything else about the Workflow is configured visually in the Filestack Developer portal.
One More Thing
The Media department is excited because the University is getting attention from international media. The IT Department and site developers quickly agree to every request and deliver results on time. Instead of creating new features, the team simply uses what they have and shows content as needed. Filestack keeps file uploads, transformations, optimization, conversion, and delivery safe and secure. By just typing a URL, they can achieve the results they want.
However, not everyone is sharing exciting photos on the website. Many great photos are available on social media that the team would love to use. Students post Instagram photos in front of caves, statues, and scrolls with the hashtag #UniversityOfAwesomeProject. So, can we use these photos?
To gather photos without users needing to visit the project’s website, we need a system that can search social media and import them using hashtags. Thankfully, Filestack offers this feature through Tint, an extra service that developers can easily add to the project site with a simple code snippet. Consequently, marketers can set up one or more Tints in their browser without needing help from the development or IT departments.
https://www.tintup.com/industries/education
Redefining Crazy
We started with a small project: taking old photos of archaeological writings. Now, we imagine growing this project into a large, community-driven effort that can share content from social media on its website. A few years ago, this idea would have seemed unrealistic, and the project would have had to settle for smaller goals. But now, by using Filestack’s API, we can handle all the complex technical work. This allows teams to think big and try out many new features. Filestack helps us convert, optimize, scan for safety, and deliver uploads efficiently at any scale.
Better yet, implementing all of this powerful functionality is trivial. In fact, I taught a group of about 20 High School students in New Jersey how to implement Filestack’s functionality, and they all had it done individually on their laptops in 5 minutes. Are you ready to give it a try?
Read more about Filestack’s EdTech use case, and get started with a free trial.
David Liedle is Filestack’s Chief Evangelist. He works remotely in New York City with his wife and son, and their kitty. See more at https://DavidCanHelp.me/
Read More →