



Every day, companies handle millions of documents like invoices, contracts, patient forms, insurance claims, and shipping papers. But in many cases, people still have to read these documents and manually enter the data into systems.
This isn’t just an IT issue. It directly affects how competitive a business is.
McKinsey estimates that automating document workflows can reduce processing costs by up to 40% and reduce turnaround times by as much as 70%. The technology behind this is called intelligent document processing (IDP), and it has evolved a lot in the last two years with the rise of generative AI.
This guide focuses on the modern version of IDP. If you still think of it as just “advanced OCR,” it’s time to take a fresh look.
Key Takeaways
- IDP automates the full document process, from collecting files to sending clean data to your systems.
- It does more than OCR; it understands and uses the data, not just reads it.
- Modern IDP uses AI, so it works faster and needs less training.
- It helps save time, reduce errors, and cut costs.
- Best results come from using AI with human review and starting small, then scaling up.
Now, let’s understand what intelligent document processing actually is.
What Is Intelligent Document Processing?
Intelligent document processing (IDP) is an AI-powered technology that automatically captures, classifies, extracts, validates, and routes data from documents, no matter the format or structure, without needing a person to handle each document manually.
Unlike basic optical character recognition (OCR), IDP does more than just turn images into text. It understands the meaning of the content, figures out which data is important, checks it for accuracy, and sends clean, structured data to the right business systems.
Now that we know what IDP means, let’s break it down in simple terms.
IDP in Plain English
Think of IDP as a very fast, very accurate clerk who can read any document in any format, pull out the relevant data, check it for accuracy, and send it to the right system, without ever getting tired, taking a lunch break, or making a typo.
Where a human clerk might process 50 to 100 documents per day, an IDP system handles thousands per hour.
IDP handles all three categories of business documents:
- Structured documents: Fixed formats like standard forms, tables, or government documents.
- Semi-structured documents: Things like invoices or purchase orders, where layouts differ but the required data is similar.
- Unstructured documents: Contracts, emails, doctor notes, or handwritten forms.
To understand how we got here, it helps to look at how IDP has evolved over time.
A Brief History: From Manual Entry to AI-Driven Processing
Understanding how IDP evolved makes it clear why today’s systems are so much more powerful.
| Era | Technology | Limitation |
| Pre-2000s | Manual data entry | Slow, error-prone, and costly |
| 2000s | Basic OCR | Converted text to digital form, but couldn’t understand it |
| 2010s | Rule-based automation & RPA | Worked only for structured data; broke when formats changed |
| 2015–2022 | Machine learning IDP | Improved accuracy, but needed lots of labeled training data |
| 2023–2026 | Generative AI & LLM-powered IDP | Understands context and can handle new document types with little or no training |
The shift from machine learning–based IDP to LLM-powered IDP is the biggest leap so far. Earlier systems needed months of training for every new document type. Now, modern systems can process documents they’ve never seen before with minimal setup.
Now let’s see how modern IDP actually works step by step.
How Intelligent Document Processing Works
IDP works in simple steps, from collecting documents to turning them into clean, organised data in your systems. Each step builds on the previous one, so raw files are automatically converted into useful information.
To make it easier to understand, here’s a simple diagram of how IDP works:
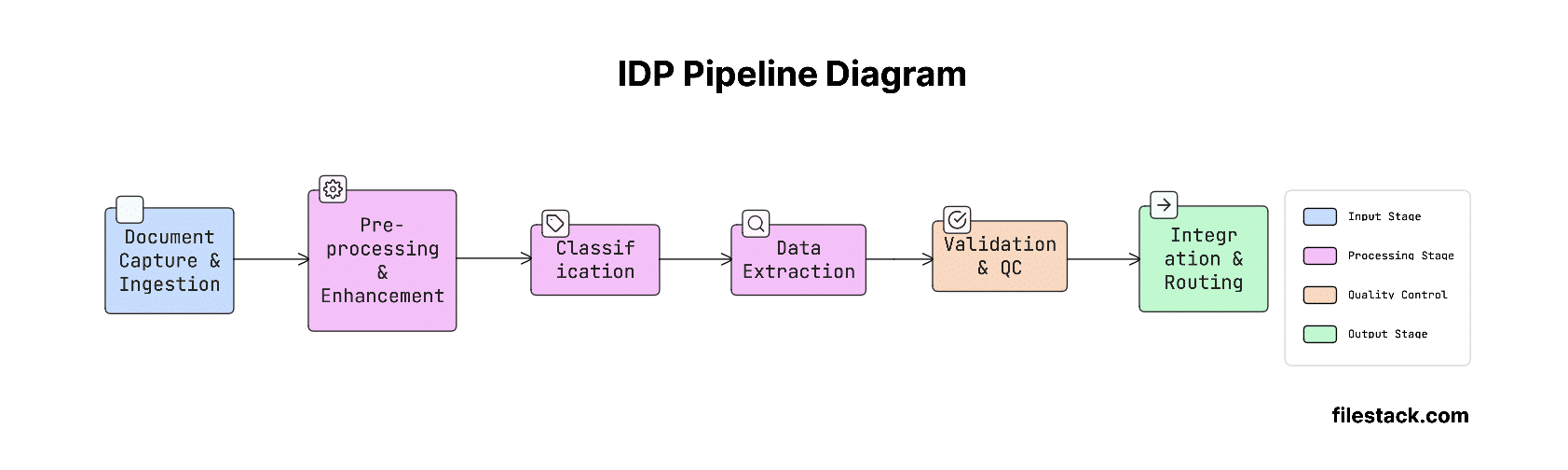

Stage 1: Document Capture and Ingestion
Every IDP pipeline starts here. Documents don’t come from a single clean source. They can come from email attachments, web uploads, mobile photos of paper documents, scanned batches from multifunction printers, shared drives, partner portals, and direct API calls.
At the ingestion stage, the IDP system needs to handle:
- Different file formats: PDF, TIFF, JPEG, PNG, DOCX, XLSX, email body, HTML.
- Varying quality: Mobile photos taken at an angle, faded fax copies, handwritten annotations.
- Sudden spikes in volume: Month-end invoice batches, post-storm insurance claims, tax season filings.
- Metadata tagging: Recording the source, upload timestamp, and intended document type so the processing pipeline knows what to do next.
This is where Filestack Capture comes in; it helps collect documents from multiple sources through a single API, making ingestion much easier.
Once documents are collected, the next step is to clean and prepare them.
Stage 2: Pre-processing and Image Enhancement
Most raw documents are messy, and that can quietly reduce accuracy later. This step cleans and fixes the documents before any AI starts working on them.
Common pre-processing steps include:
- Deskewing: Straightening scanned pages that were fed at an angle.
- Binarization: Converting images to black and white to make text clearer.
- Noise reduction: Removing unwanted marks, background patterns, or blur.
- Resolution normalization: Improving low-quality images so they meet OCR requirements.
- Orientation correction: Rotating pages that were scanned upside down or sideways.
This step is often underestimated. Even small improvements here can boost data extraction accuracy by 10–15%, especially for poor-quality documents.
After cleaning, the system needs to understand what type of document it is.
Stage 3: Document Classification
Before extracting any data, the system first needs to understand what kind of document it is. For example, an invoice, a medical form, and a contract all need different handling.
Modern systems use two main approaches:
- ML-based classification: Trained on many labeled examples for each document type; very accurate but takes time to set up.
- LLM-based classification: Uses AI to understand the content and purpose of the document; can handle new document types with little or no training.
A key part of this step is confidence scoring. If the system isn’t sure about the document type, it flags it for human review instead of processing it automatically. This is important because a wrong classification can lead to errors in all the next steps.
Once the document type is clear, the system can start extracting the data.
Stage 4: Data Extraction
This is the main step, where the system pulls out specific data from each document.
To do this, IDP uses a mix of technologies:
- OCR (Optical Character Recognition): Converts the document image into machine-readable text.
- NLP (Natural Language Processing): Understands the meaning of the text (for example, knowing “Net 30” is a payment term).
- ML models: Locate the right fields even when document layouts vary significantly across vendors or issuers.
Table extraction is more complex than it seems. The system needs to keep rows and columns intact. Basic OCR often reads tables as plain text and loses the structure, so special logic is needed.
Handwriting recognition makes things even harder. Modern systems can read handwritten notes, but accuracy depends on how clear the writing is and is usually lower than printed text.
After extraction, the data needs to be checked for accuracy.
Stage 5: Validation and Quality Control
The extracted data isn’t sent directly to other systems. First, it’s checked to make sure everything is correct.
Common validation checks include:
- Business rule validation: Does the invoice total match the sum of line items? Is the date format valid? Does the PO number follow the expected format?
- Cross-referencing: Matching extracted vendor IDs against the vendor master file, or purchase order numbers against the open PO database.
- Format validation: Confirming that tax IDs, routing numbers, and policy numbers match expected patterns.
A key part of this step is human-in-the-loop (HITL). If the system isn’t confident about certain data, it sends it to a human instead of processing it automatically. The person reviews and fixes it if needed.
This isn’t a weakness; it’s by design. HITL helps companies automate most of the work (around 90–95%) while still keeping accuracy high for tricky cases.
Once everything is verified, the data is ready to be sent to other systems.
Stage 6: Integration and Workflow Routing
Once the data is clean and validated, it’s sent to the systems that need it, like ERP, CRM, data warehouses, or other business tools.
Common integration methods include:
- REST API: The most flexible option for custom integrations.
- Webhooks: Event-driven delivery to any endpoint.
- Native connectors: Pre-built integrations for SAP, Salesforce, ServiceNow, Workday.
- File export: Structured CSV, JSON, or XML for systems without API support.
This stage can also include smart routing. For example:
- High-value invoices go to a manager for approval.
- Low-value invoices are processed automatically.
- Contracts with unusual terms are sent to legal teams.
Routing decisions are based on the extracted data, not where the document came from.
Filestack Workflows fits here by handling automation and routing, helping connect document ingestion with your downstream systems through webhooks and configurable workflows.
Now that we’ve seen how IDP works, let’s compare it with similar technologies.
IDP vs. OCR vs. RPA: What’s the Difference?
It’s easy to confuse these terms, but they solve different problems. Here’s a simple comparison to understand how they differ:
| OCR | RPA | Intelligent Document Processing | |
| What it does | Converts document images to machine-readable text | Automates repetitive digital tasks (clicking, copying, filling forms) | Captures, classifies, extracts, validates, and routes document data end-to-end |
| What it handles | Images of text; struggles with tables, handwriting, unusual layouts | Structured digital interfaces; cannot interpret unstructured content | All types of documents: structured, semi-structured, and unstructured |
| Accuracy | Varies widely; degrades on poor quality inputs | High on structured tasks, but cannot handle document variability | 95–99%+ on structured fields with HITL for exceptions |
| Handles layout variation | No | No | Yes |
| Learns over time | No | No | Yes (ML models improve with feedback) |
| Integrates with other systems | Limited | Yes, natively | Yes, via API, webhooks, and native connectors |
| Best for | Converting scanned text to a digital format | Automating structured, predictable digital workflows | End-to-end document automation across variable formats and sources |
This also helps explain why older tools like OCR or RPA alone are not enough.
Why OCR Alone Is Not Enough
OCR converts an image of text into machine-readable characters. That’s all it does. It has no concept of what the text means, where a specific field is located on the page, or what the system should do with the extracted characters once they exist.
OCR accuracy also degrades meaningfully on handwriting, low-quality scans, unusual fonts, and non-standard layouts, exactly the conditions that characterize real business documents.
IDP builds on top of OCR. It starts with text extraction, then adds intelligence, like understanding the document, finding the right data, checking accuracy, and sending it to the right system. In simple terms, OCR is just one part of IDP, not a complete solution.
But OCR isn’t the only limitation; RPA also has its own challenges.
Why RPA Alone Hits a Wall with Documents
RPA is exceptionally good at what it was designed for: automating structured, predictable, rule-based digital tasks. Clicking buttons, copying data between fields, and generating reports from fixed data sources.
The problem is that RPA requires structured data to work with. It cannot open a PDF invoice, understand that one vendor calls the field “Invoice Date” while another calls it “Bill Date,” and correctly extract the right value in both cases. It has no mechanism to handle that variability.
IDP and RPA are complementary, not competitive. IDP handles the extraction and understanding layer, turning documents into structured data. RPA handles the downstream automation once the data is clean and structured. Many enterprise document workflows combine both.
This is exactly why businesses are moving toward IDP.
Let’s look at the key benefits IDP brings.
Key Benefits of Intelligent Document Processing
IDP helps businesses save time, reduce errors, and scale faster. Here are the main benefits:
- Accuracy: Reduces errors that usually happen with manual data entry.
- Speed: Processes thousands of documents per hour instead of just a few per day.
- Cost reduction: Can lower document processing costs by up to 40% (McKinsey).
- Scalability: Handles large volumes without needing more people.
- Compliance: Keeps proper records and access controls for every document processed.
Accuracy
Manual data entry usually has a 1–4% error rate. That might sound small, but on 100,000 invoice lines, it means 1,000 to 4,000 mistakes, each one needing time to fix later.
Modern IDP systems are much more accurate. They typically reach 95–99% accuracy on structured data. With newer AI models, accuracy can get close to 100% for well-defined documents.
For the few uncertain cases, human review (HITL) steps in. This keeps errors very low and makes everything traceable.
Speed and Throughput
A person can usually process around 50–100 documents a day. An IDP system can handle thousands every hour.
Processing time also drops a lot—from minutes (including waiting time) to just seconds. According to McKinsey’s automation benchmarks, this can reduce turnaround time by up to 70%.
For things like invoice approvals or insurance claims, this speed directly improves cash flow and customer experience.
Cost Reduction
The biggest savings come from needing fewer people for manual data entry. But the indirect savings are often even more important; fewer errors mean less rework, fewer compliance issues, and fewer disputes caused by wrong data.
McKinsey benchmarks suggest that document processing costs can drop by up to 40% after using IDP. For a mid-sized team handling around 50,000 invoices a month, that can lead to significant savings.
Scalability
With manual work, scaling means hiring more people. If the workload doubles, you need double the staff.
IDP works differently; it scales with computing power, which can increase on demand.
This is especially useful during peak times. For example, insurance companies after a disaster, accounting teams during year-end, or retailers in busy seasons. An IDP system can handle 10x more documents without needing extra hiring.
Compliance and Auditability
Every document processed by an IDP system is tracked. It records what data was extracted, when it happened, how confident the system was, and whether a human reviewed it.
This creates a clear audit trail, which helps with compliance requirements like:
- GDPR Article 17 (right to erasure): Makes it easier to track and delete document data when requested.
- HIPAA §164.312: Ensures secure access and proper logging for sensitive patient data.
- SOC 2 Type II: Controls who can access data and keeps records of processing decisions.
In short, IDP not only processes documents but also keeps everything transparent and traceable.
These benefits become clearer when we look at real-world use cases.
Intelligent Document Processing Use Cases by Industry
Different industries use IDP in different ways, but the goal is the same: reduce manual work, improve accuracy, and speed up processes.
Finance and Accounts Payable
Finance teams handle a large number of repetitive documents every day, which makes them one of the best areas to use IDP.
Key use cases:
- Invoice processing: Extract vendor name, line items, totals, payment terms, and PO numbers; match against purchase orders for 3-way matching.
- Bank statement analysis: Extract transactions, balances, and account identifiers for reconciliation.
- Loan origination: Process mortgage applications, bank statements, pay stubs, and tax returns; extract and validate data against underwriting criteria.
The BFSI (banking, financial services, and insurance) sector makes up about 30% of global IDP spending as of 2025, according to Docsumo’s IDP market report.
While finance focuses on transactions, healthcare deals with more sensitive data.
Healthcare
Healthcare deals with a large number of documents that are complex and sensitive. There’s high volume, strict regulations, and many different formats across hospitals, clinics, and insurance systems.
Key use cases:
- Patient intake: Extract data from insurance cards, referral forms, consent forms, and ID documents into EHR systems.
- Clinical documentation: Process physician notes, lab reports, and discharge summaries into structured entries.
- Medical claims: Extract claim data from CMS-1500 and UB-04 forms for faster adjudication.
HIPAA note: If IDP systems handle patient data (PHI), they must follow strict rules, like having a Business Associate Agreement (BAA), using encryption, and maintaining proper access controls with full audit logs.
Similar challenges exist in the insurance industry as well.
Insurance
The insurance industry handles a huge number of documents in different formats across the entire policy lifecycle.
Key use cases:
- Claims intake: Extract loss descriptions, policy numbers, dates of loss, and claimant details from First Notice of Loss (FNOL) forms.
- Underwriting: Process application forms, inspection reports, and supporting documentation; flag missing items automatically.
- Policy issuance: Validate application data against policy requirements and route exceptions for manual review.
Using IDP can make a big difference. A leading US commercial lines property and casualty insurer worked with Indico Data to implement an intelligent intake solution and achieved an 85% reduction in claims processing time, turning a document backlog that spanned weeks into a near-real-time workflow.
In contrast, legal workflows require even higher accuracy.
Legal
Legal documents are usually long, text-heavy, and unstructured. Even small mistakes can have serious consequences, so accuracy is critical.
Key use cases:
- Contract analysis: Extract parties, effective dates, renewal clauses, obligations, termination conditions, and governing jurisdiction.
- Due diligence: Process data rooms containing hundreds of documents; flag missing items against a standard checklist.
- Court filings: Extract case numbers, parties, filing dates, and deadlines from variable-format legal documents.
Logistics, on the other hand, deals with large volumes and global formats.
Logistics and Supply Chain
Logistics teams handle a large number of documents from different countries and partners, often in very different formats.
Key use cases:
- Bills of lading: Extract shipper, consignee, cargo description, quantity, and delivery terms.
- Customs documentation: Classify and extract from varying international document formats across different country requirements.
- Supplier invoices: Process invoices from hundreds of suppliers in varying formats without per-supplier template setup.
HR also benefits from IDP across the employee lifecycle.
Human Resources
HR teams deal with documents throughout the entire employee lifecycle, from hiring to exit.
Key use cases:
- Resume parsing: Extract candidate name, skills, years of experience, education, and certifications into ATS fields.
- Onboarding documents: Process offer letters, tax forms (W-4, I-9), direct deposit forms, and benefits enrollment documents.
- Performance reviews: Extract structured ratings and comments from review forms for HR analytics.
A big reason IDP has improved so much recently is the rise of generative AI.
How Generative AI and LLMs Are Changing IDP
This is the biggest shift in IDP so far. Nothing in the past decade has changed document automation as much as generative AI and large language models (LLMs).
What Changed and Why It Matters
Traditional ML-based IDP required large labeled training datasets for each new document type. Building a model to extract from a new invoice format meant collecting hundreds or thousands of labeled examples, annotating them, training the model, validating it, and iterating. The time from “we need to process this document type” to “the system is processing it accurately” was measured in weeks or months.
LLMs and foundation models change this entirely. Zero-shot and few-shot learning means that a modern IDP system can process a document type it has never seen before, with no retraining and in some cases no examples at all. The model understands the document’s content and intent from its training on the broader universe of text.
Generative AI also adds a layer of capability that goes beyond extraction: summarization, risk flagging, anomaly detection, and natural language querying of document data.
Specific GenAI Capabilities in Modern IDP
Context-aware extraction understands that “Net 30” means a 30-day payment term and calculates the actual due date, rather than just extracting the literal string “Net 30.” The model understands the semantics of the field, not just its location on the page.
Document summarization generates a plain-language summary of a 50-page contract for a busy executive, highlighting key dates, obligations, and risk factors, without requiring anyone to read the full document first.
Anomaly detection flags invoices where the total doesn’t match the sum of line items, or contracts that contain non-standard clauses that deviate from your standard template. These are the kinds of checks that would require a human legal or finance reviewer to perform manually.
Natural language querying allows non-technical users to ask questions like “show me all contracts renewing in Q3” or “which invoices have been pending approval for more than 14 days”, without writing a database query or building a report.
Multimodal processing handles documents that combine text, tables, images, stamps, signatures, and handwriting in a single file, common in healthcare forms, insurance documents, and government submissions.
Zero-shot classification can identify a document type it has never been explicitly trained on, based on its content structure and language patterns.
The Tradeoff: Accuracy vs. Auditability
LLM-based extraction can sometimes make mistakes by generating data that sounds correct but isn’t. This happens more often than with traditional ML models that are trained on specific document types.
For clearly defined fields like invoice numbers, tax IDs, or dates, the risk is lower. But for fields that need interpretation, like clauses in a contract or notes in a document, the risk is higher.
For high-stakes documents like legal contracts, medical records, or financial data, human review (HITL) is still necessary.
The best approach today is:
- Use generative AI for understanding and classifying documents.
- Use trained models for extracting critical fields where accuracy is crucial.
- Use human review for uncertain or edge cases.
The 2025 SER IDP Survey found that 78% of companies are already operational with AI in their IDP projects, though most use it as part of a broader, multi-layered workflow rather than a single all-in-one solution.
Now let’s look at how to choose the right IDP solution.
How to Evaluate and Choose an IDP Solution
There are many IDP tools in the market, and most of them sound similar. To choose the right one, you need clarity on your own requirements first.
Questions to Ask Before You Evaluate Vendors
Before looking at any vendor, answer these internally:
- What document types do you need to process? How many per day or month?
- What formats do your documents arrive in? (Scanned paper, digital PDF, email attachment, mobile capture, API upload)
- What systems do you need to integrate with? (ERP, CRM, RPA platform, data warehouse)
- What are your accuracy requirements? Can you tolerate a 1% error rate, or do you need near-zero with HITL for exceptions?
- What compliance requirements apply to your documents? (HIPAA, GDPR, SOC 2, PCI-DSS)
Key Capability Criteria
These are the core features you should compare when evaluating different IDP solutions. They help you understand how well a tool will perform in real-world use.
- Document type coverage: Can the solution handle structured, semi-structured, and unstructured documents? Can it handle handwriting and mixed-format documents?
- Training requirements: Does it require large labeled datasets for each new document type, or does it work with few-shot or zero-shot learning? The answer determines time-to-value for each new document category.
- Accuracy and confidence scoring: Does it provide field-level confidence scores so you can set HITL thresholds at the field level, not just the document level? This granularity matters.
- Integration options: REST API, pre-built connectors (SAP, Salesforce, ServiceNow), and webhook support. Check whether the connectors you need are included or cost extra. Major cloud providers like AWS and Microsoft offer managed IDP services that integrate natively with their broader ecosystems, worth considering if your infrastructure is already cloud-aligned.
- Document capture options: Can it ingest documents from email, mobile, scanner, web upload, and cloud storage? Or does it assume documents are already normalized digital PDFs? This is where the pipeline starts, and it’s frequently an afterthought. Filestack Capture provides multi-source document ingestion as the first stage of an IDP pipeline.
- Compliance certifications: SOC 2 Type II, HIPAA BAA availability, GDPR data residency options. Ask for the actual certification documents, not just the marketing copy.
Another important part that many teams overlook is document capture.
How Filestack Capture Fits Into an IDP Pipeline
Most IDP tools focus on processing documents, but the first step, getting those documents into the system, is often overlooked. That’s where tools like Filestack Capture come in.
The Document Ingestion Problem Most IDP Guides Ignore
IDP platforms are great once documents are inside the system, but they don’t always handle how those documents get there.
In reality, document ingestion is messy. Files come from many sources: email attachments, mobile photos, scanners, partner portals, or cloud storage, and each one can have different formats and quality.
Building this from scratch is not simple. It involves handling different file types, managing file sizes, scanning for security issues, improving image quality, adding metadata, and routing documents correctly, all before any AI processing even begins.
What Filestack Capture Provides
Filestack Capture handles the document ingestion layer as a managed service:
- Multi-source ingestion accepts documents from web upload, mobile camera capture, email, cloud storage (Google Drive, Dropbox, OneDrive), and direct API, from a single endpoint. Your IDP pipeline receives documents from any source without building separate integrations for each.
- Pre-processing at ingestion applies image enhancement, format conversion, and file validation before the document reaches your IDP processing layer. By the time a document enters the extraction pipeline, it’s already been cleaned and normalized.
- Virus scanning checks every uploaded document before it enters the processing queue, a requirement for most enterprise security policies.
- Metadata and routing attach document type, source channel, upload timestamp, and custom tags to each file. The IDP system knows what to do with each document the moment it arrives, without inferring context from the file itself.
Connecting Capture to Workflows
Once a document is captured with Filestack Capture, Filestack Workflows can automatically send it to the next step in the IDP pipeline.
This is done using webhooks, which can route documents to tools like AWS Textract, Google Document AI, or your own custom system.
The whole process happens automatically, no manual steps needed. You can also set rules to send different types of documents to different processing pipelines.


Once capture is set up, the next step is implementing IDP properly.
Getting Started with IDP: Implementation Phases
If you’re planning to implement IDP, it’s best to take a step-by-step approach instead of trying to automate everything at once.
The Five-Phase Approach
Phase 1 — Define scope: Start with one document type that has high volume and causes the most pain. Invoices are a good starting point because they’re common and give quick results. Don’t begin with the most complex documents.
Phase 2 — Set up document ingestion: Decide how documents will enter your system and what formats you need to support. This is the base of your pipeline. Tools like Filestack Capture can help handle this step.
Phase 3 — Configure extraction: Set up your IDP system to extract the required fields. Define accuracy thresholds and decide when to send documents for human review. Start strict (e.g., below 90% confidence goes to review) and adjust later.
Phase 4 — Integrate outputs: Connect the extracted data to your systems like ERP or CRM using APIs or webhooks. Test everything with a small batch before full rollout.
Phase 5 — Measure and expand: Track results like accuracy, speed, errors, and cost savings. Once it works well for one document type, move to the next. Scaling gradually works better than trying to do everything at once.
Common Implementation Mistakes
These are common mistakes teams make when starting with IDP, and avoiding them can save a lot of time and effort.
- Starting with your most complex document type: It’s tempting to solve the hardest problem first, but this usually fails. Start with the highest-volume, most standardized document you have, prove ROI in 90 days, and build from there.
- Skipping HITL: 95% accuracy sounds good until you calculate what it means at scale. On 10,000 documents per day, a 5% error rate means 500 documents with incorrect data entering your business systems daily. HITL helps catch these early.
- Underinvesting in document capture and pre-processing: Even the best AI won’t work well on blurry, skewed, or corrupted input images. Garbage in, garbage out applies to IDP as much as any data pipeline.
- Treating IDP as a set-and-forget system: document formats change. Vendors update their invoice templates. Government forms get revised. ML models need monitoring, retraining, and updating as document formats evolve. Build model governance into your IDP operations from day one. IDP is not “set and forget.”
Now let’s wrap everything up.


Conclusion
Intelligent document processing (IDP) automates the entire document workflow, from capturing documents to turning them into clean, structured data in your systems. With generative AI, it has become more powerful and much easier to set up than before.
The process starts with document capture and ingestion. If this step isn’t done well, it affects everything that comes after: accuracy, speed, and reliability.
If you’re getting started, focus on capture first. Sign up for Filestack and connect your first document source in minutes.
If you still have questions, here are some quick answers.
Frequently Asked Questions
What is the difference between IDP and OCR?
OCR converts images of text into machine-readable characters. IDP uses OCR as a first step but adds classification, named entity extraction, validation, and workflow routing on top. OCR tells you what the text says. IDP tells you what it means and what to do with it.
Does IDP require a lot of training data?
Traditional ML-based IDP did, often hundreds or thousands of labeled examples per document type. Modern LLM-based IDP systems use zero-shot or few-shot learning and can handle new document types with minimal or no labeled training data.
What accuracy can I expect from an IDP system?
On well-defined, structured document types, modern IDP systems achieve 95–99% accuracy. With human-in-the-loop review for low-confidence outputs, effective accuracy approaches 100%.
Is IDP suitable for HIPAA-covered documents?
Yes, with the right vendor configuration. Ensure your IDP vendor can provide a Business Associate Agreement (BAA), offers encrypted storage at rest and in transit, and maintains audit logs meeting HIPAA §164.312 requirements.
How long does an IDP implementation take?
A first-document-type implementation typically takes 4 to 12 weeks, depending on integration complexity. LLM-based systems reduce the training data requirement and can shorten this timeline significantly compared to traditional ML-based IDP.
What is human-in-the-loop (HITL) in IDP?
HITL is a pattern where documents with low extraction confidence scores are routed to a human reviewer rather than auto-processed. The human corrects the flagged fields, and those corrections can improve the model over time. HITL is how IDP achieves near-100% effective accuracy at scale.
Updated April 2026 to include generative AI and LLM coverage. Previously updated October 2025.
Sources:
- McKinsey Global Institute — The Economic Potential of Generative AI
- Docsumo IDP Market Report 2025
- 2025 SER IDP Survey
- AWS Textract Documentation
- Microsoft Azure Document Intelligence


Shefali Jangid is a web developer, technical writer, and content creator with a love for building intuitive tools and resources for developers.
She writes about web development, shares practical coding tips on her blog shefali.dev, and creates projects that make developers’ lives easier.