
Extracting data manually from documents and scanned images was pretty common back then. However, many businesses today use OCR or optical character recognition to automate data extraction. OCR basically extracts data from scanned documents (printed or handwritten text) and images containing text automatically. It then converts the extracted data into machine-readable text. Due to its high demand, many mobile apps implement OCR functionality. Fortunately, OCR SDKs and APIs have made it easier and simpler to integrate OCR data capture functionality in mobile apps. For instance, iOS developers often utilize OCR iOS SDKs to integrate built-in OCR capabilities seamlessly into their apps.
While OCR data capture software and SDKs had their limitations in their early stages, we now have highly advanced OCR engines that can extract text with higher accuracy and efficiency. This article will explore the evolution of OCR technology and advancements in iOS SDKs for OCR data capture and image processing.
The evolution of OCR in iOS SDKs

Challenges and limitations in earlier iOS SDKs for OCR
OCR has been a valuable technology ever since it was invented. However, earlier solutions had their limitations. For example, these SDKs and solutions relied on pattern-matching algorithms to extract text. This involved comparing text in documents/images (character by character) to various patterns saved as templates in the internal database of the OCR software.
The problem with this process was that it was nearly impossible to store all the diverse types of fonts and handwriting styles in the database. As a result, the OCR system couldn’t extract data with high accuracy for all kinds of fonts and handwriting styles, especially complex ones. This often led to omissions of characters, misinterpretations, and substitutions.
The processing speed of the OCR engine was another significant limitation. Earlier algorithms weren’t highly optimized for speed, which led to slow and efficient text recognition and extraction processes. Moreover, hardware constraints also contributed to slow processing speed. This negatively impacted productivity, especially when dealing with large volumes of documents or images.
Earlier OCR solutions and SDKs also had limited support for multiple languages and different document layouts.
Advancements in iOS OCR SDKs
With technological advancements, OCR SDKs for iOS have also evolved. Today’s OCR systems are highly efficient, extracting data with high accuracy. Here are the key advancements in iOS SDKs for OCR:
High accuracy
Today’s OCR SDKs leverage machine learning algorithms, neural networks, and AI to recognize and extract text from scanned documents or images with high accuracy. These sophisticated algorithms are based on feature extraction, meaning they analyze various image features, such as lines, curves, loops, and intersections. They then combine these results to provide a more accurate final result (text extraction).
Moreover, these OCR engines and SDKs are capable of detecting a diverse range of fonts and handwriting styles with high accuracy. Thus, today’s iOS OCR tools can reliably extract text from various documents and images, including handwritten notes, with higher precision.
Image pre-processing
Many OCR data capture solutions and SDKs today come with built-in image pre-processing features. These include despeckling, deskewing, cleaning up the lines, and image binarization. These features make it easier for the OCR engine to recognize text, significantly improving the OCR data accuracy.
Speed and efficiency
The processing speed of OCR engines in iOS devices has improved significantly thanks to optimized algorithms. Moreover, today’s OCR solutions and SDKs leverage the computational power of modern mobile devices. This leads to faster text recognition and extraction processes, enhancing productivity.
Enhanced support for various document and data types
Today’s iOS OCR SDKs and tools support a broader range of documents and data types. These OCR solutions can efficiently handle:
- Various handwritten styles
- Different fonts
- Multiple languages
- Complex document layouts
This advancement allows users to extract text from diverse types of documents, such as invoices, receipts, and business cards, making iOS OCR tools indispensable for various tasks and industries.
Filestack iOS SDK: An example of an advanced OCR system
Filestack iOS SDK allows you to integrate Filestack File Picker/Uploader and other Filestack services into your iOS app, including OCR. The iOS SDK supports iOS 11 and later, including iOS 16.
You need to make an API call to Filestack Processing API to implement OCR in your iOS apps. Filestack OCR leverages advanced machine-learning algorithms and neural networks for high data accuracy. Moreover, it relies on a powerful digital image analysis system to detect features efficiently. Filestack OCR is also backed by advanced document detection and pre-processing solutions. These solutions enable the OCR system to detect complex, wrinkled, rotated, or folded documents.
Enhancing business processes with OCR

Automating data extraction and data entry
OCR technology is widely used by businesses to automate data extraction and data entry tasks. Back then, employees used to extract information from documents, forms, or receipts and type it into a computer system manually. However, with OCR data capture, they just need to scan paper documents and provide them as input to the OCR data capture solution. The OCR engine then automatically recognizes and extracts text from these documents. Businesses can then populate databases with the extracted data automatically using data integration tools.
Thus, OCR accelerates the data extraction and entry processes and minimizes the risk of human errors. Moreover, it saves valuable time and costs.
Improving data accessibility
OCR enables businesses to digitize physical documents and convert them into searchable formats. This significantly improves data accessibility. Any employee can access the required documents from anywhere and search for the required information quickly. Thus, OCR helps improve business operational efficiency and productivity.
For example, healthcare institutes can digitize patients’ paper records. This way, they can quickly retrieve required patients’ details and data to provide timely healthcare services. OCR also enables educational institutions to digitize textbooks, course materials, and library resources. This makes these learning resources easily accessible to students and faculty members.
Automating invoice processing
Manual invoice processing is a long process involving various steps, such as:
- Extracting relevant information from invoices and entering it into the computer system
- Validating the extracted data and comparing it with purchase orders
- Sending the invoice for final approval and payment processing
Fortunately, businesses can leverage OCR to automate invoice processing. They can use OCR to extract information from invoices and utilize tools to validate and verify the extracted data automatically. Additionally, they can implement mechanisms for automatic approval workflow to automate the entire process. This reduces human errors, improves accuracy, and accelerates the whole process.
Streamlining inventory management
OCR software can also be a valuable tool for the retail industry. Businesses can utilize it to streamline inventory management, order processing, and customer service operations. For example, retailers can use OCR to scan product labels, barcodes, and shipping documents automatically. This helps fulfil orders efficiently, track inventory levels, and provide real-time updates to customers.
Retailers can also use OCR to extract data from customer feedback forms, surveys, and social media posts. This will help analyze customer sentiment and preferences to enhance products and marketing strategies.
Verifying documents
Document verification helps businesses prevent fraud. Fortunately, OCR can be an effective tool for this purpose. Businesses can use OCR to accurately extract information from ID cards, driver’s licenses, passports, and more. They can then use this information to verify a person’s identity.
Technical deep dive: OCR and image processing
In this section, we’ll discuss the technical aspects of OCR data capture.
Image pre-processing
The OCR process starts with document scanning. Once the user uploads the scanned document, the OCR software first applies different image pre-possessing techniques. These techniques enhance the image quality and make it easier for the OCR engine to recognize text and complex documents with lists, tables, etc.
Image pre-processing techniques typically include deseckling, deskewing, image binarization, and cleaning up the lines. However, you can also apply other techniques like upscaling, cropping, and resolution enhancement if your image is of low quality.
For example, Filestack allows you to utilize a diverse range of image processing and enhancement techniques to manipulate and enhance your image files.
Text recognition
As aforementioned, OCR data capture capabilities in iOS SDKs have improved significantly. Today’s OCR systems are based on feature detection, which utilizes ML algorithms and neural networks.
Once image pre-processing is done, the OCR system analyzes the image to identify individual characters and isolate them from one another. This is usually done using segmentation techniques or detecting spaces between words.
Next, the OCR system uses feature extraction techniques to determine the key characteristics of each character. This involves splitting the character into multiple features. These include lines, line direction, curves, loops, intersections, character shape, and more. The OCR system then finds the closest match for the character in the database based on these features and recognizes text with high accuracy.
Post-Processing
Post-processing is the final step in OCR data capture. It involves techniques like error correction, language modelling, and data validation and verification. This helps correct errors and refine the extracted text for improved data accuracy.
Code Snippets: Implementing OCR in iOS
Here, we’ll show you how to integrate Filestack iOS SDK into your apps and implement Filestack OCR. With Filestack iOS SDK, you can integrate a powerful file uploader for your OCR functionality. In other words, you can use this uploader to upload your scanned documents. You can then implement the OCR functionality via Filestack Processing API.
Here is how you can implement Filestack iOS SDK:
First, install the iOS SDK through CocoaPods.
gem install cocoapodsNext, integrate FilestackSDK into your Xcode project (remember to specify it in your Podfile):
source 'https://github.com/CocoaPods/Specs.git'
platform :ios, '16.0'
use_frameworks!
target '<Your Target Name>' do
pod 'Filestack', '~> 2.0'
endFinally, run the following command:
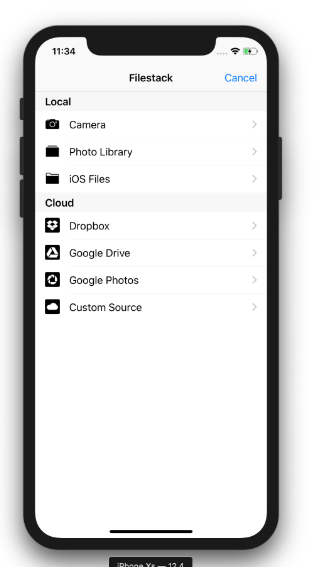
pod installBelow is an example code for presenting Filestack File Picker in your iOS apps:
// Create `Config` object.
let config = Filestack.Config.builder
.with(appUrlScheme: "YOUR-APP-URL-SCHEME")
.with(availableCloudSources: [.dropbox, .googledrive, .googlephotos, .customSource])
.with(availableLocalSources: [.camera, .photoLibrary, .documents])
.build()
// Instantiate the Filestack `Client` by passing an API key obtained from https://dev.filestack.com/
// If your account does not have security enabled, then you can omit this parameter or set it to nil.
let client = Filestack.Client(apiKey: filestackAPIKey, config: config)
// Store options for your uploaded files.
// Here we are saying our storage location is S3 and access for uploaded files should be public.
let storeOptions = StorageOptions(location: .s3, access: .public)
// Instantiate picker by passing the `StorageOptions` object we just set up.
let picker = client.picker(storeOptions: storeOptions)
// Optional. Set the picker's delegate.
picker.pickerDelegate = self
// Finally, present the picker on the screen.
present(picker, animated: true)Note: You must get your Filestack API key to integrate the File Picker and perform OCR.
Output
Implementing OCR
You perform OCR through Filestack processing API:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL/CDN URL>Here is an example code for implementing the OCR function:
func performOCRwithProcessingAPI(fileURL: String) {
// Construct the Processing API URL
let processingAPIURL = "https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL/CDN URL>"
// Create the URLRequest
var request = URLRequest(url: URL(string: processingAPIURL)!)
request.httpMethod = "POST"
// Set up the request body with the file URL
let requestBody = ["url": fileURL]
request.httpBody = try? JSONSerialization.data(withJSONObject: requestBody)
// Create a URLSession task to make the API request
let task = URLSession.shared.dataTask(with: request) { (data, response, error) in
// Handle the API response
if let error = error {
print("Error: \(error)")
} else if let data = data {
// Parse and handle OCR results
if let ocrResults = try? JSONSerialization.jsonObject(with: data, options: []) as? [String: Any] {
print("OCR Results: \(ocrResults)")
}
}
}
// Start the URLSession task
task.resume()
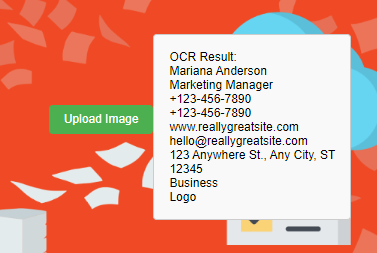
}Here is an example output of Filestack OCR:
Input image:

Filestack OCR output for the above business card:
Looking Ahead: The Future of OCR in iOS
Future OCR solutions are expected to leverage advanced deep-learning models to extract text with even higher accuracy. For example, these solutions can implement convolutional neural networks and recurrent neural networks. Additionally, these systems may combine NLP with OCR, allowing for a better understanding of the extracted text and its context.
Conclusion
Optical character recognition (OCR) is widely used in iOS apps, from language translation and document scanning to note-taking apps. Fortunately, various third-party iOS SDKs for OCR are available, making it easier to integrate OCR functionality. While early SDKs had their limitations, advancements in OCR technology have addressed many of these challenges. Today’s modern OCR systems and SDKs can handle diverse fonts and handwriting styles with higher accuracy. Moreover, they offer enhanced processing speed, improving efficiency.
FAQs
What is OCR data capture?
OCR is a valuable technology that automatically extracts text from scanned documents (printed or handwritten) and text images. It converts this text into machine-readable structured data. Thus, OCR eliminates manual data entry and data extraction.
What is OCR used for?
OCR has a wide range of applications. These include:
- Automating data entry
- Automating invoice processing
- Document digitization
- Document verification
- Streamlining inventory management
Is OCR only for text?
OCR extracts text from printed and handwritten scanned documents and text images.
Sign up for Filestack today and integrate its iOS SDK for powerful file management and OCR features!

Sidra is an experienced technical writer with a solid understanding of web development, APIs, AI, IoT, and related technologies. She is always eager to learn new skills and technologies.
Read More →