EdTech is a challenging space to write code. On the one hand, you’ve got the need to ensure the highest standards in security, performance, availability, and integrity. On the other hand, the size of your team or department, the time you have available, and the budget for your project may be very constrained. To get around these constraints, student volunteers sometimes contribute entry-level development, or features that should be at the top of a project’s priority list simply get dropped. With reality pushing back against project goals, how can we break free and build amazing experiences in this space?
Who Has the Time?
Some educational institutions have a dedicated budget for technology research and development, but that doesn’t mean they want to spend their time and resources on every layer of managing a fully operational IT and Operations effort. The rise of cloud services, API-driven integrations, and Software as a Service (SaaS) has set EdTech free to solve the problems that are interesting, and leave the expensive, time-consuming grunt work out of the picture.
In House Resources
My last experience with EdTech was working with a technology-focused university in the United States several years ago as a consultant. They have their own in-house servers and are able to spin up as many virtual environments as they want for students, teachers, and University projects. They can run production servers in house with fiber trunk lines direct to the campus, and most certainly have the skilled employees that are more than capable of implementing even the most daunting technical requirements.
What do most Universities not have? Unlimited file storage space, pre-written file transformation tools, any form of production-ready Machine Learning microservices with ML models customized with myriad training inputs, and servers distributed around the world for fast, scalable delivery. So how do we avoid reinventing the wheel and solving the wrong problems? Where’s the line between what we can do and what we should do?
Use Case: Student Uploads
Let’s consider one of the many types of content that EdTech works with: student-generated files. These may be images, PDFs, Microsoft Office docs such as Word or Excel files, videos, and others. The same basic things need to happen regardless of the type of file, and really even without regard to its eventual usage context.
Students creating docs, images, and videos for assignments, group projects, or any collaborative use will need a way to associate their stuff with the website, whether internal or external. This means that no matter how many edits, transformations, resizes, and different versions of a file are uploaded, there needs to be a unique ID assigned to each file. We’ll want to keep track of metadata, or in some cases strip it before the files are delivered. We’ll need to make sure that these files are landing in a scalable storage location, like an S3 bucket or another cloud storage provider. Putting uploaded files on the same hard drive as the website’s back end code is a recipe for tears.
Have you opened up an image file from a recent model cell phone camera lately? They’re huge! The file size of a photo taken by a DSLR camera is even bigger. That’s great for quality, but not so great for displaying on the web. Whether you’re sharing these files with one group within a single class, or worldwide to thousands of viewers, displaying media on the web requires the proper dimensions, compression, and file formats.
Let’s drill down to one specific example of students uploading files: imagine a historical preservation project where students are asked to document a museum’s process for capturing and archiving old written artifacts. Put on your Indiana Jones hat and picture fragments of papyrus, old books, or clay tablets engraved with a lost language, and let’s think through the problem:
Preserving History: An Adventure in Uploads
Students are at the museum, working with their team to preserve history. They’re taking high-resolution photos, shooting some videos, and generally having a great time. Back on campus, the IT and Media departments are setting up a website to share this project with the world. The high resolution photos are being transferred from an SD card, and the students are ready to upload copies to the project website.
Let’s follow the implementation the IT and Media Department will go through to handle this project.
Hello, IT
At our fictional University, IT sets up a virtual machine on their in-house hardware. They set the DNS for the .edu domain such that a canonical site hits that virtual environment. They set up a database, and ask the Media department what kind of storage needs they will have, and Media says “we’re not sure yet; be ready for anything!” They set up an S3 container so the storage can scale as much as needed, and all the pieces are in place.
Design
The site is ready to begin development, and simultaneously a designer sits down with the organization’s design guidelines and puts together the look and feel of the site.
Front End Development
A Front End Developer takes these designs and builds them out in an HTML page. In a private page intended only for the students, they drop in the Filestack File Picker with a few lines of JavaScript, and then style the upload button to match the look and feel of the site.
Back End Development
A back end developer creates public-facing routes to serve the project’s pages, and puts together an admin login system with private routes for students (and only students) to upload their images. The user ID of each student will be associated with the handle of each uploaded file in the database.
They create an endpoint to consume webhooks from the upload process. The data received from this webhook will be used by the back end developers for conditional logic and association of the file handles with the users in the database.
Ready, Set, Upload!
Students try out the new site. They log in with their credentials and see the custom-styled File Picker. With the SD card inserted into their laptops, they simply open the picker and navigate to the card to select and upload the high resolution photos taken by the museum’s cameras. Now, the photographers are shooting RAW+JPG files, but they’re only interested in the JPG files for the website. However, these are some rootin’ tootin’ file sizes! Not to worry – the students don’t have to think about that. They simply upload the JPEG images and they’re done. The URLs used to display the images on the site will actually do all of the work to resize and compress their uploads; they don’t have to do a thing!
As the huge JPG images are being uploaded, they’re landing on the University-controlled S3 bucket. The web team has logged in to the Filestack Developer Portal and configured their account such that their S3 bucket is being used instead of the default storage provided with each Filestack account.
Displaying the Uploads
How do we display all of these uploads? We should probably set up a batch process to create multiple image sizes from each source image for display on the web, right? Well hold on now, it’s 2019 and there’s a better way. Filestack offers an open source drop-in solution for responsive images. It leverages the Filestack API to intelligently request the best image for the size required. Cell phones, tablets, desktops, laptops… Every browser, every size, will receive the best web-ready version of the images by wiring up this solution.
A Wild Challenge Appears
Let’s take our example case to an extreme. The project is growing, and as is the way of the world, unforeseen challenges begin to arise.
Students have begun using Dropbox and Google Drive to store Excel files where they’ve started tracking the work they’re doing. They have also been using their cell phones to take pictures of each other at work on the project, and are uploading these photos to Instagram and Facebook. They’re shooting videos of each other describing their work, and the Media department is starting to take notice. Media asks the developers: “What would it take for us to add these behind-the-scenes photos from the students to the site?”
The developers just smile and explain, “We’re using Filestack: it’s already done.”
Filestack’s File Picker allows uploads from Instagram, Facebook, Dropbox, Google Drive, and more by default. Students simply select Instagram, for example, and authorize their Instagram account to pick any of their images to upload into the site.
With the Filestack Document Viewer, the Excel files can even be displayed directly in the browser. Better yet, those Excel files can be directly converted to PDF or even PNG or JPG files with zero code simply by asking for them using a file conversion URL.
Then one day, the project leaders have an idea. They’re going to crowd-source file uploads from the public, around the world, in a global search for related content. During the archival of these old documents, they’ve discovered evidence of an ancient global trade network and they want to see if anyone around the world can provide additional clues.
Simultaneously, University leadership takes note and, in light of the growing popularity of the project, dictates some business requirements around what needs to happen to all files:
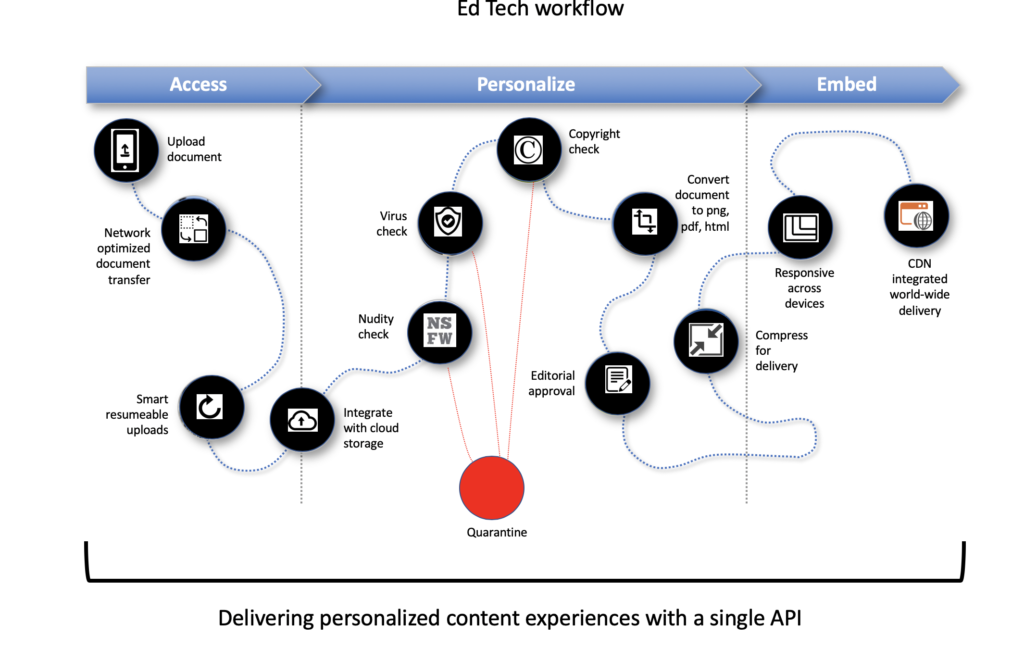
Uh-Oh… Now what?
Discovering that you already have something you need is a great feeling. In our example project, we’ve just introduced an idea that would normally get shot down without serious funding, allocation of development resources, and lots of time: asking the world to upload files to a site that started out as a small project.
We don’t have to change anything about our infrastructure to handle this new requirement. The File Picker can be displayed to outside users, and they can upload their images from whichever source they wish.
But hang on a minute… File uploads from strangers around the world? We’d better be responsible about that. What if the project is targeted by pranksters or even criminals? We should really filter these uploads to make sure there are no NSFW images or any files with viruses or malware passing through the system. Can we handle that? Yes we can.
Filestack offers a SFW (Safe For Work) check, and a Virus Detection service, and both can be dropped in to any project without any additional development work by creating tasks visually in the Workflows editor. The example project we’re talking about here already receives webhooks, so we just ask the Front End Developer to add one line to the JavaScript that displays the picker. That line specifies the unique ID of the Workflow, and everything else about the Workflow is configured visually in the Filestack Developer portal.
One More Thing
The Media department is ecstatic. The University is getting international media coverage, and the IT Department and the site developers are saying “yes” to every request they make, and delivering in record time. No energy is being spent on building this functionality, only on consuming it and displaying it as desired. File uploads, transformations, optimization, conversion, and delivery are all safe, secure, and as simple as typing out a URL that asks for the end result desired.
But not everyone is uploading interesting pictures into the website; there’s a lot of content in the wild on social media that the team would love to work with, if only there were a way to bring it in to the project. Students are posting Instagram photos of themselves standing in front of caves, statues, and scrolls, and they’re using the hashtag #UniversityOfAwesomeProject. Can we use this?
Without a user directly coming to the project’s website to upload their photos, we need a system that can crawl social media and import these photos based on search parameters like a set of hashtags. Filestack offers this functionality via Tint, an additional service that developers can add to the project site with a simple snippet of cut-and-paste code. Marketers can then configure one or more Tints in their browser, without needing any further involvement from the development or IT departments.
https://www.tintup.com/industries/education
Redefining Crazy
In our fictional example, we’ve started with something pretty small: taking archival photos of archeological writings. We’ve imagined scaling that tiny project to a massive worldwide, community-involved project, including the ability to display hashtagged content from social media on the project site. A few years ago, achieving this level of functionality would have sounded crazy, and the project would have had to limit their dreams to something “more realistic.” By offloading the infrastructure and development of a complete, end-to-end file handling system to Filestack’s API, we’ve gone from “this is crazy!” to the freedom of being able to just go crazy with feature after feature at our fingertips. The uploads are being converted, optimized, scanned for appropriateness and security, and delivered efficiently at any scale.
Better yet, implementing all of this powerful functionality is trivial. In fact, I taught a group of about 20 High School students in New Jersey how to implement Filestack’s functionality, and they all had it done individually on their laptops in 5 minutes. Are you ready to give it a try?
Read more about Filestack’s EdTech use case, and get started with a free account.
David Liedle is Filestack’s Chief Evangelist. He works remotely in New York City with his wife and son, and their kitty. See more at https://DavidCanHelp.me/
Read More →