


Document Detection and Preprocessing is one of Filestack’s latest intelligent products. Not only is its main objective detecting the documents in the images, transformations, and denoising, but it can also serve as an advanced tool for enhancing and improving OCR results. The following article explores and elaborates on the details of how this tool has been generated, its specific use case, how it works, and what is under the hood.
Why Document Detection and Preprocessing?
In 2018, when Filestack released their first Machine Learning (ML) -based OCR (optical character recognition), there were a lot of applications created by customers to extract the text inside of the complex documents.




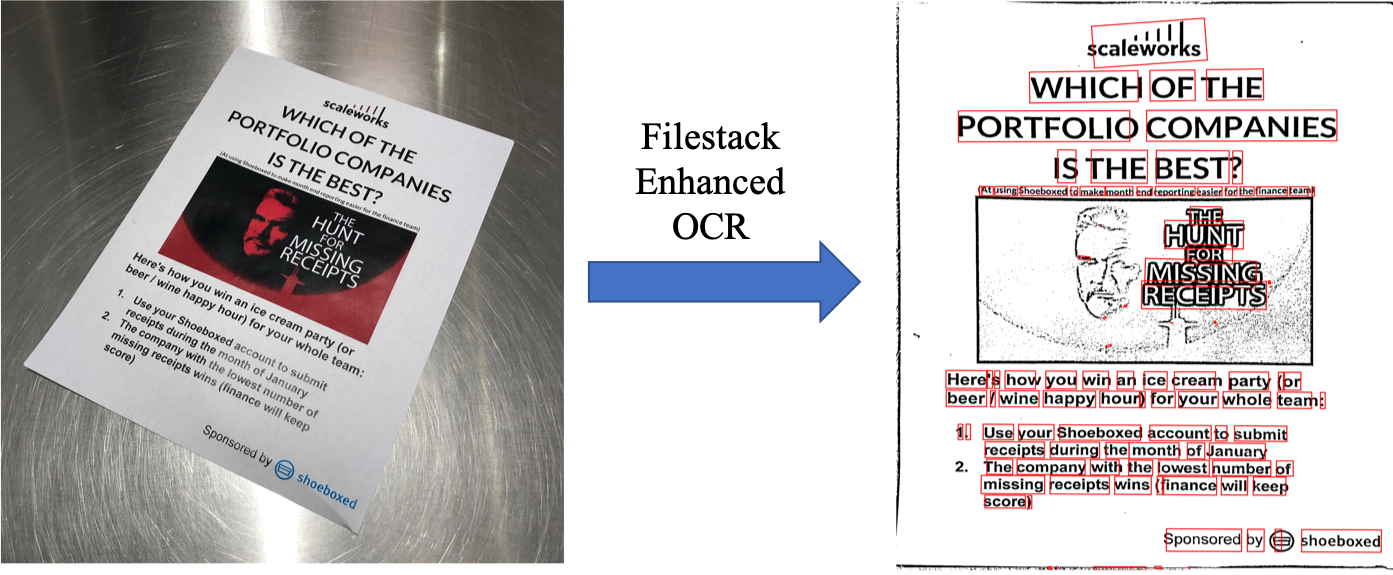
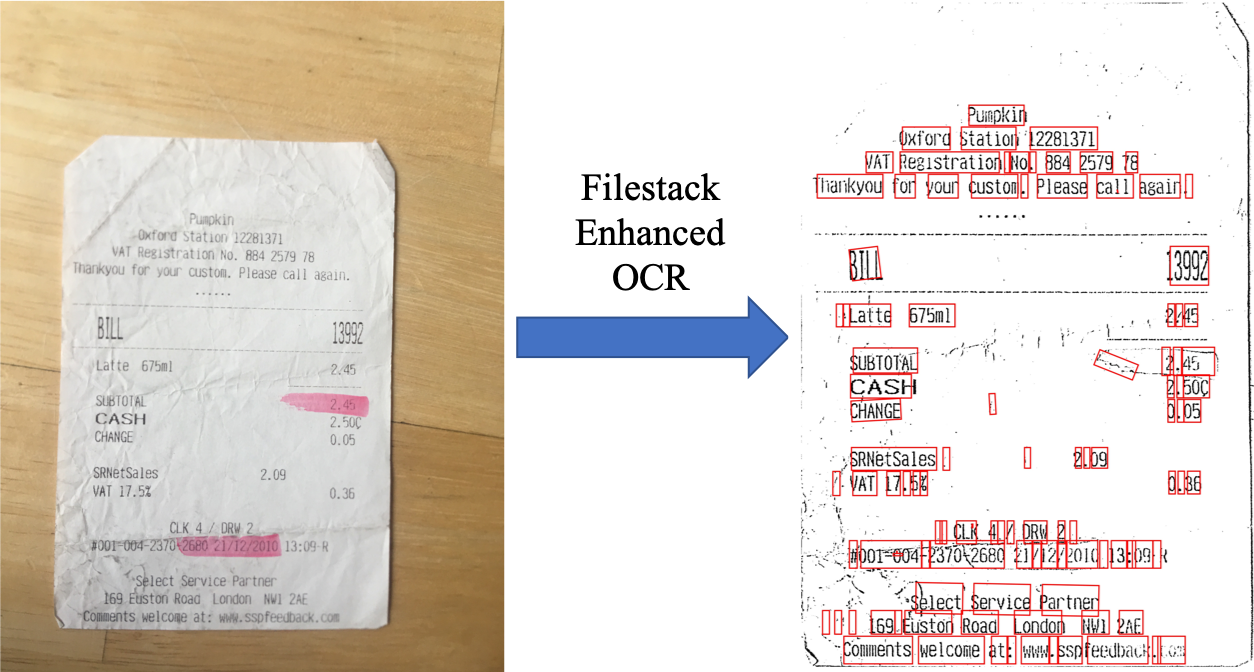
The word “complex” is used to refer to any document which is rotated, folded, noisy, etc. For instance, Figure 1 shows a document that appears rotated in the image, and Figure 2 shows the noisy image of a folded document which is not easily read by the OCR engine. A complex document can make the OCR results less accurate and non reliable. Having experienced this issue with several batches of images, Filestack decided to develop a custom tool to detect the outlines of images, enhance them, and make them less-noisy and legible enough to be fed to the OCR engine.
The Filestack Solution
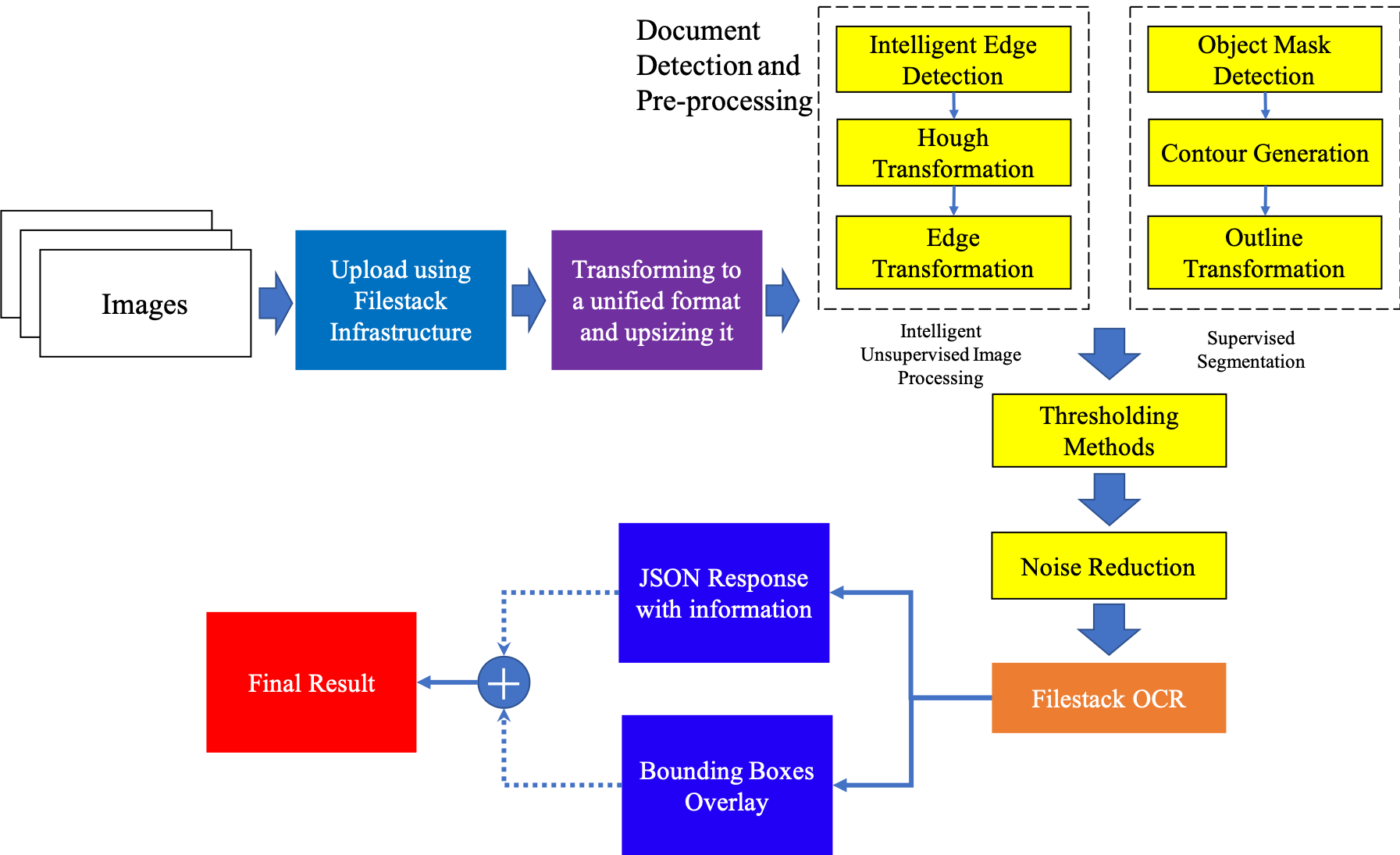
In order to detect the outlines of the document in the images, Filestack has two different Machine Learning based solutions which work accurately. The first model is in the category of “Unsupervised Learning with Intelligent Image Processing”, and the second solution is in the category of “Supervised Segmentation”.
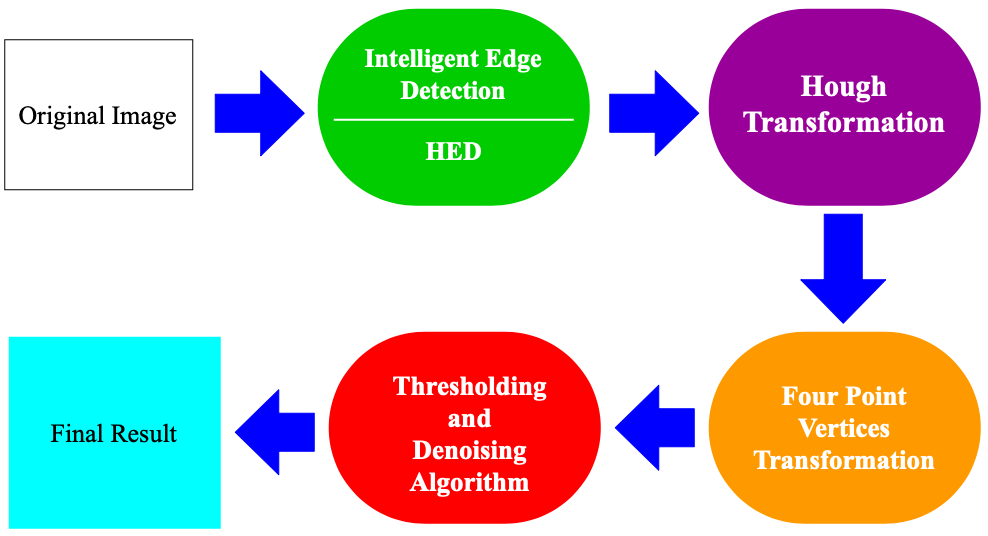
Solution 1: Intelligent Unsupervised Image Processing
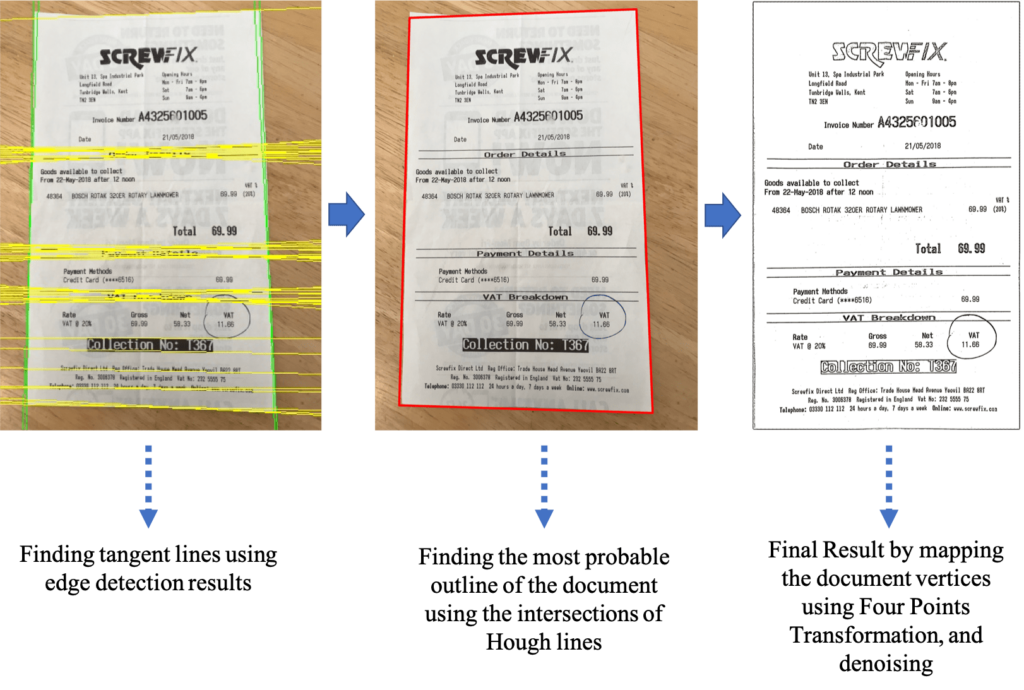
Figure 3 shows a simple block diagram of this approach. The first operating block is Intelligent Edge Detection.

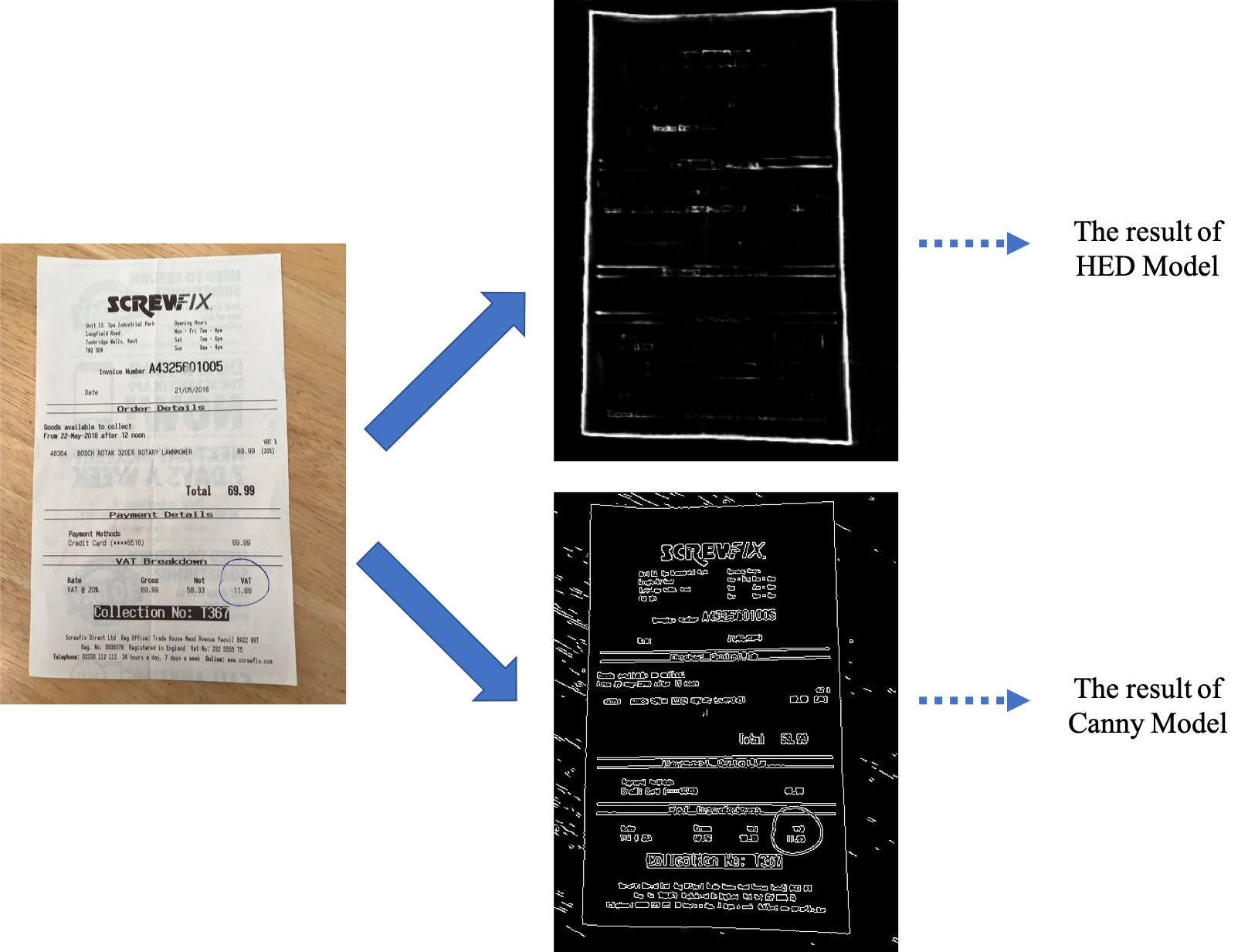
Training a state-of-the-art neural network edge detection model (HED, or Holistically-nested Edge Detection) using a customized edge-map-layer generated dataset helps find the most probable edges of the document in the image. After finding the edges in the document, using a mathematical algorithm called Hough Transformation, we can find the tangent lines on the detected edges, and by finding the intersections, the four most-probable vertices of the document can be found. By detecting the vertices, the document’s contour can be generated, transforming the document and fixing distortions using pixel-by-pixel mapping to cover the whole image.
Finally, using different thresholding methods (Local, Mean, and Otsu), the result is a simplified noise-reduced and grayscale image. Figure 4 and Figure 5 show an insight process of this model to an example step by step.



Solution 2: Supervised Segmentation Solution
This approach is mainly based on Supervised Learning methods, among which are the family of segmentation methods. Relying on the benefits of U-Net, an efficient segmentation architecture with backbone of ResNet, we trained our network with a customized, segmented dataset. Figure 6 shows a simplified block diagram of this approach showing the process of mask detection, contour generation, outline selection, and transformation of the object to fit the image. The last block is similar to the previous approach for denoising the image and making it more visible for the OCR engine.

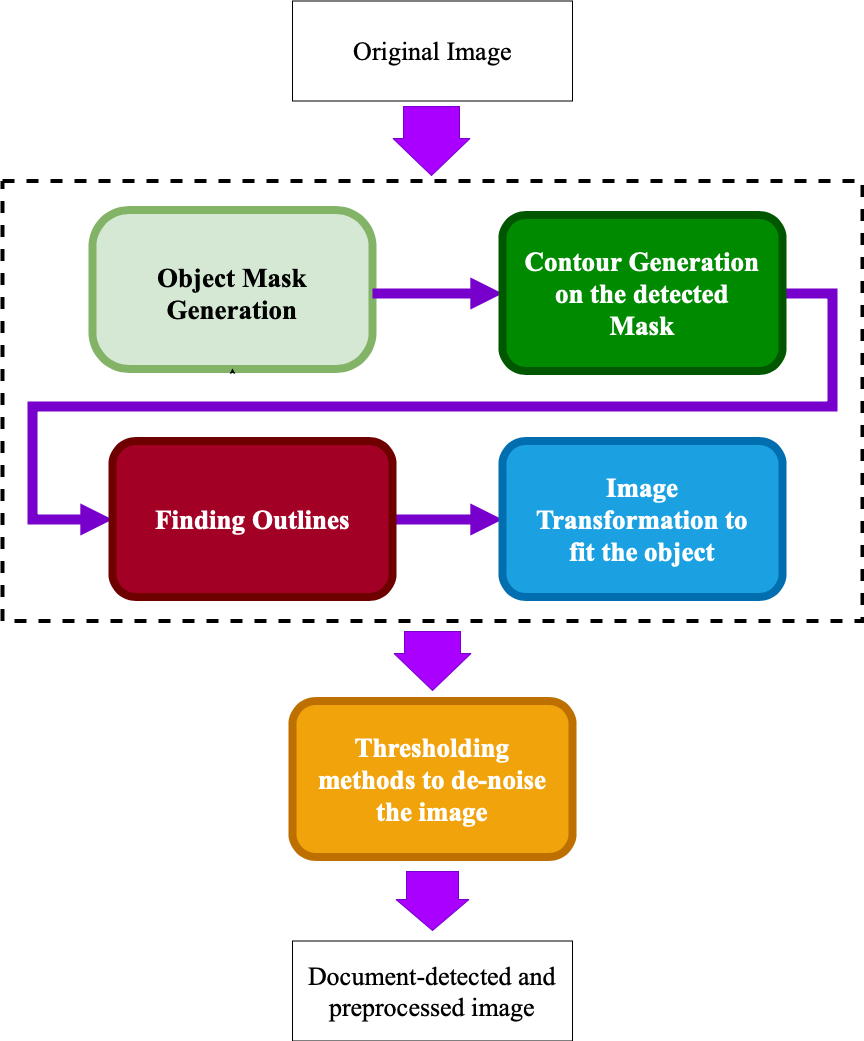


As an example of mask generation block, Figure 7 shows the predicted mask of the document. After detecting the mask of the main object using our trained network with the customized dataset, the next block would generate the polygon contour which contains the mask, and the mask is fully inscribed within it. By detecting the contour of the document, the rest of the parts would be similar to the previous approach for finding the outline of the document, transforming it to fit the whole image dimension, and thresholding and denoising for increasing OCR accuracy.
The whole process in step-by-step generation can be seen in Figure 8.


The next part would be a brief description of Filestack Enhanced OCR, and its features.
Filestack Enhanced OCR
Utilizing the benefits of our advanced document detection and preprocessing tools, we can increase the accuracy of our OCR engine. Shown in Figure 9, our general API is used to upload the images to our databases. After that, by transforming them to a unified format and resizing them to a standard size, they are fed into our document detection and preprocessing tools to make the image more clear for the OCR engine. By running the OCR capabilities, the results are generated as both a JSON response containing all of the information of the extracted texts, and the visualization of detected text into the original image.

The visualized results of Filestack Enhanced OCR (Document Detection and Preprocessing + OCR) on Figure 1 and Figure 2 are presented in Figure 10 and Figure 11.


Conclusion
In this blog post, one of the latest ML-based applications of Filestack, Document Detection and Preprocessing, has been introduced. Relying on the benefits of both Unsupervised and Supervised Learning approaches, we are able to detect the document in the images, transform them to fit the image dimension, and process them to get rid of the noise, and make the text more clear for the OCR engine.


Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.