Our journey starts out quite differently than any one company that is trying to build the most modern image recognition service. For one, we are not only focused on training, creating models, and building data sets. To us, these are table stakes. We are interested in abstracting key data points out of data oceans and helping you identify trends that will help you make better business decisions. What we are doing is being obsessed with providing a service to our customers that will help them pull relevant information from their images. This is why we’re building the Filestack Image Recognition Engine (FIRE).
The basis of FIRE is to be an abstraction layer that sits atop the world’s leading object recognition services. Technology industry giants have dipped their toes into the object recognition arms race, as well as start-ups who are fighting tooth and nail to carve out their niche in a white-hot category.
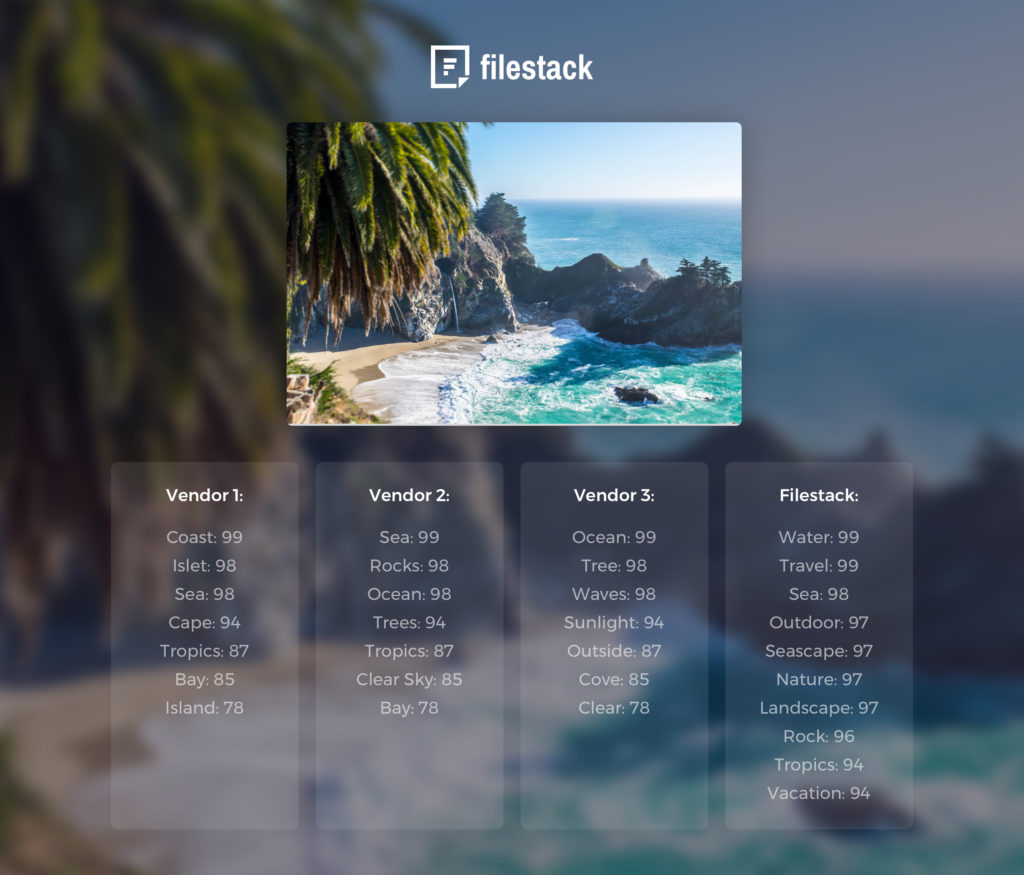
In March of 2017, we launched an image tagging API that our customers could consume to get a list of image tags from their photos, as well as detect NSFW content. I blogged about our experience and findings in our image tagging research, which includes who we tested, the performance, and the accuracy of leading services at the time. This was our first foray into the artificial intelligence and machine learning world, and will certainly not be our last. As we’ve continued to learn from customers, quick and accurate image object recognition is a growing need for all companies that are looking to maximize the intelligence of digital assets.
As with any fast-moving start-up, the time has come for us to iterate and improve our product. Filestack Image Tagging was highly requested by our customers, and originally implemented as a standalone feature added to our Files API via Google Vision. In our tests, we found excellent accuracy and speed from Google, which ultimately won us over. As we continued to pound the Google Vision service and test new AI services, we found Clarifai to have an impressive set of models, training capabilities, and accuracy. With a little bit of engineering, we were able to add Clarifai as an additional service provider which gave our customers the best of Google Vision and Clarifai. This naturally led to where we are today, building a full on service that will bring the best out of multiple object recognition platforms to one API.
This strategy is nothing new to Filestack, as we built our company around being the best ingestion platform on the planet. Integrations with cloud storage services like S3, Dropbox, Azure Blob Storage, and Box have been part of our story since day one, and the Filestack Content Ingestion Network ™ and Intelligent Ingestion ™ are recent additions that have continued to raise the bar when it comes to world-class file uploading. As the Filestack platform evolves from standalone ingestion to also enabling intelligent content, there is no reason you should rely on one AI platform for all your object recognition needs. Filestack is here to help you take advantage of all the best features of every AI platform and put it behind one API.
FIRE is still in its very early stages, but I figured you should at least get a sneak peek at our proof-of-concept.
FIRE is in development today, but we’re actively looking for alpha and beta testers. If this FIRE looks like something that could be useful to you, we’d love to chat. You can email us at support@filestack.com, or tweet at myself or Filestack. Someone will be in touch to learn more about your use case, and we can also update you on the latest happenings of FIRE.
Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.
Read More →