

Automated analysis and information extraction from pictures of structured documents is one of the use cases we have at Filestack for applied machine learning. We are working with envelopes, receipts, invoices, and most recently: checks. Checks are a medium of a little archaic form of monetary transfers – almost unseen outside United States, nevertheless used for billions (1e9) of transactions each year.
There are plenty of interesting problems to solve when you’re building a “check processing API” that has to change an image like that:


Into a response like that:
{
'amount': 100.55,
'check_number': 243,
'date': {
'year': 2006,
'month': 12,
'day': 1
},
'routing_number': '011234567',
'receiver': 'Wikimedia Foundation',
'sender': 'Mr John Jones'
}
In this tutorial we’ll focus on the string of weird looking characters at the bottom of every check, called the MICR line. It was designed in the 1950s to make the processing and clearance of checks simpler and faster. It was a huge success and because it is printed with magnetic paint full of iron, the dedicated readers have no problem with deciphering the digits, even if they are obstructed visually.


Unfortunately, most modern document scanners don’t provide any information about the magnetic field in the vicinity of the scanned document So, to retrieve the information from the MICR line we have to rely on methods of image processing, computer vision and deep learning.
There is a great introductory tutorial done by Adrian Rosenbrock: https://www.pyimagesearch.com/2017/07/31/bank-check-ocr-opencv-python-part-ii/ where he shows a “traditional” (non-ML) approach to the very same task we are dealing with – it’s a great proof of concept, but the final reliability is not nearly at the level we need.
To solve this problem in a business oriented environment, we had to develop a full blown OCR engine dedicated to work with that particular set of symbols. Even though the ten digits look familiar to all of the common Latin fonts, there are 4 special characters (on the right) and a strict requirement for very high accuracy. If you get 1 digit of an 8 digit routing or check number wrong, the error rate is 100%, not just 12.5%.
Detection and classification
These are the two steps that make a foundation of every successful OCR engine – first you have to localize every symbol you want to read, and next, classify it as one of the characters in your alphabet. We will focus on the latter, as single character classification is the bona fide introductory use case of deep learning – mostly thanks to Yan Le Cunn and all of his great work on the MNIST dataset.


In the case of hand-written digits stored as a 28×28 image, the problem of classification has been considered solved for years. We want to use this as a starting point for our OCR engine. In order to mimic the MNIST approach we need to create a congenial dataset with MICR characters instead of common digits. There is no inherent reason to keep the name closely related (or to name our dataset at all) but in order to feel like a part of the machine learning community, we’re going to call it MICRST.
Unreasonable effectiveness of synthetic data
Creating such dataset from MICR encountered in the real world would require manual cropping and labeling of thousands of check images. In principle it is most definitely possible (and in more complex cases may be unavoidable) – but we are going to advocate an alternative approach: making the whole dataset from scratch programmatically.
Since in the case of MICR we don’t have to worry about handwriting variability, we can focus on other problems that we stumble upon while working with scans of checks of our clients: lightning differences, various resolutions, distracting backgrounds and all kinds of other visual artifacts that introduce confusion to the predictive models. With a small bunch of free textures and some drawing routines we can generate any number of small (28×28) backgrounds:


Overlaying MICR characters and it’s almost ready for training:


For the final step we process each image through a random set of blurring, stretching, distorting, rotating and other noise adding procedures:


After a quick glance one can guess that achieving high accuracy on that set with simple deep learning approach is very much possible, while there is still a lot of images with high level of obscurity that make it at the same time challenging and forces you to develop versatile models.

Building on that, we were able to develop a proper OCR engine reading MICR lines from large images with high accuracy, which is now a crucial part of our automated check analysis service. It’s designed to use together with document detection service (https://blog.filestack.com/thoughts-and-knowledge/gain-more-control-over-your-documents-with-document-detection/) and can ingest images like that:


And return:
{
'amount': 23.00,
'check_number': 0025,
'date': {
'year': 2012,
'month': 12,
'day': 12
},
'routing_number': '789123456',
'receiver': 'Richard Hendricks',
'sender': 'Peter Gregory'
}
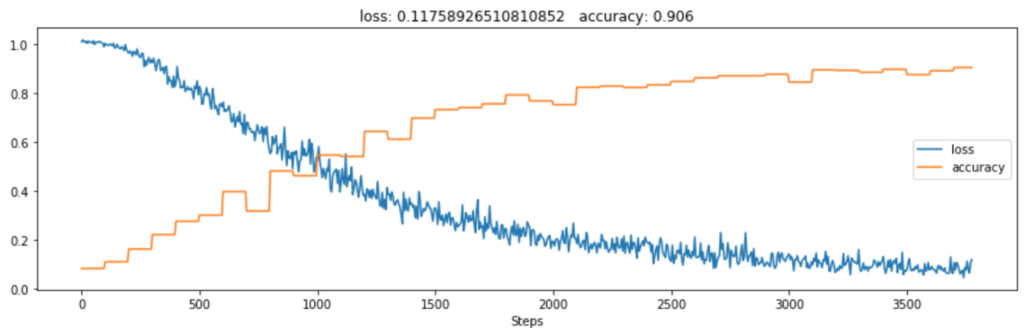
With this article we are sharing a small, self contained repository (https://github.com/filestack/micrst-competition) with full source code and other resources necessary for recreating the dataset on your own, along with simple pytorch dataset implementation and super basic, not very deep neural network achieving ~90% accuracy on that dataset. We encourage you to try and beat that result and share your score with us at support@filestack.com.


Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.