
Optical Character Recognition (OCR) technology has definitely changed the way we extract textual data from documents. Previously, it was mostly a manual process. However, thanks to OCR, we can now automatically extract accurate text/information from different types of documents. These include scanned paper documents (printed text or handwritten), PDFs, and images containing text. OCR basically converts these documents into editable and searchable data and extracts useful information from them. Recently, cloud-based OCR data capture is becoming highly popular due to its scalability, efficiency, and ease of integration.
One of the biggest benefits of cloud-based OCR is scalability. These solutions can handle large volumes of data without the need to invest in hardware or infrastructure. They can scale up or down based on the workload. Thus ensuring that performance remains optimal.
An example of a cloud-based OCR data capture software is Filestack. Filestack is essentially a reliable cloud-based file management platform that offers powerful OCR capabilities. Its scalability, secure processing, ease of integration, and high accuracy make it a leading cloud-based OCR solution.
In this article, we’ll:
- Explore how to implement cloud-based OCR data capture using Filestack’s platform.
- Discuss key aspects of cloud-based OCR, such as scalability, cloud OCR integration, and handling large volumes of data.
Key Takeaways
- Filestack provides a robust cloud-based OCR solution that allows for the scalability and handling of large volumes of data.
- Implementing OCR microservices helps develop scalable cloud OCR architecture.
- Enabling batch processing helps handle large datasets efficiently.
- Serverless OCR implementation enhances scalability and reduces costs.
- Automating the OCR data pipeline involves efficiently designing OCR pipelines and integrating them with ETL processes.
- Implementing OCR across multiple cloud platforms offers benefits like high availability, disaster recovery, and reduced latency.
- Cloud OCR security involves security mechanisms like end-to-end encryption, TLS, HTTP encryption, and access control.
- Integration with enterprise systems involves connecting cloud OCR with on-premises systems and implementing Single Sign-On (SSO) for OCR services.
Setting Up Cloud-Based OCR with Filestack
Filestack provides a complete file-handling platform that includes features for:
- File uploads
- Transformations
- Storage
- File delivery
All of which are managed through cloud services. Filestack offers OCR capabilities through its processing API. These OCR capabilities are also cloud-based.
This means Filestack’s OCR processes the documents and images for OCR data extraction through Filestack’s powerful cloud infrastructure. This allows for scalability and the ability to handle large volumes of data.
Filestack’s OCR is backed by advanced machine learning algorithms and neural networks. This significantly enhances the OCR data accuracy. It also utilizes a powerful digital image analysis system and robust document detection and pre-processing solutions.
Also read: Difference Between OCR and ICR | A Complete Guide.
Implementing OCR with Filestack
First, you need to sign up for a Filestack account. You can then obtain your API key from the Filestack dashboard. This key will be required to authenticate your requests.
To implement Filestack cloud-based OCR, we can use Filestack File uploader to upload documents of OCR data capture. Filestack automatically stores uploaded files to an internally managed S3 bucket. ?However, we can also connect the upload to our own cloud storage solution. Here’s an example of how you can use a different storage provider instead of the default S3 bucket:
const client = filestack.init(YOUR_API_KEY);
const options = {
storeTo: {
location: 'azure',
path: '/site_uploads/'
}
};
client.picker(options).open();Code Snippets
Below is an example code for a simple app that uses Filestack File Picker to upload images. The app then performs OCR on the uploaded image. In the next sections, we’ll discuss various techniques and strategies that you can implement with Filestack cloud-based OCR for high scalability.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>OCR Data Extraction</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 0;
background-image: url('https://blog.filestack.com/wp-content/uploads/2023/12/Online-File-Delivery.png');
background-position: center;
height: 100vh;
display: flex;
justify-content: center;
align-items: center;
}
#upload-btn {
padding: 10px 20px;
font-size: 16px;
background-color: #4CAF50;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
margin-bottom: 20px;
}
#ocr-output {
border: 1px solid #ccc;
padding: 20px;
border-radius: 5px;
background-color: #f9f9f9;
max-width: 600px;
}
#ocr-text {
white-space: pre-line; /* Preserve line breaks */
}
</style>
</head>
<body>
<!-- Filestack file uploader will be triggered when this button is clicked -->
<button id="upload-btn">Upload Image</button>
<div id="ocr-output" style="display:none;">
<div id="ocr-text"></div>
</div>
<script src="https://static.filestackapi.com/filestack-js/3.x.x/filestack.min.js"></script>
<script>
const FILESTACK_API_KEY = 'Your API Key';
const policy = 'Add Policy Here';
const signature = 'Add signature here';
document.addEventListener('DOMContentLoaded', function() {
document.getElementById('upload-btn').addEventListener('click', function() {
// Open Filestack file uploader
filestackFileUpload();
});
// Function to open Filestack file uploader
function filestackFileUpload() {
const client = filestack.init(FILESTACK_API_KEY);
const options = {
onUploadDone: function(result) {
console.log('Filestack upload result:', result);
const fileHandle = result.filesUploaded[0].handle;
performOCR(fileHandle);
},
accept: ['image/*']
};
client.picker(options).open();
}
function performOCR(fileHandle) {
const ocrUrl = `https://cdn.filestackcontent.com/${FILESTACK_API_KEY}/security=p:${policy},s:${signature}/ocr/${fileHandle}`;
fetch(ocrUrl)
.then(response => response.json())
.then(data => {
console.log('OCR data:', data);
const ocrText = data.text;
document.getElementById('ocr-output').style.display = 'block';
document.getElementById('ocr-text').textContent = 'OCR Result:\n' + ocrText;
})
.catch(error => console.error('Error performing OCR:', error));
}
});
</script>
</body>
</html>In the above code, remember to replace Your API Key, Policy, and Signature with your actual API key, policy, and signature.
Demo
Input image:

Output:
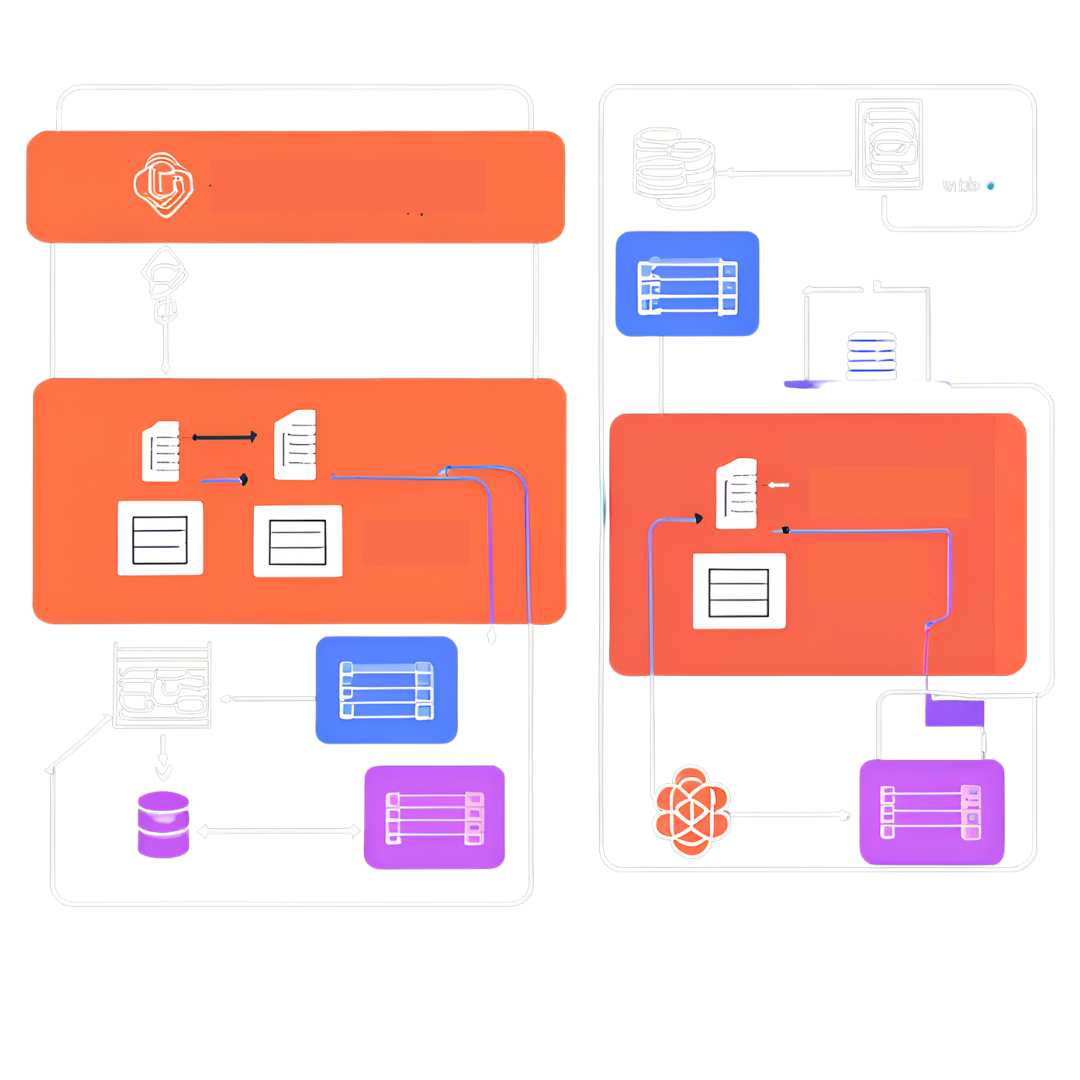
Scalable OCR Architecture
Designing a scalable OCR architecture involves various key considerations:
Designing for high-volume OCR processing
You can design a high-volume OCR processing system from scratch. However, it’s best to use a pre-built OCR engine, such as Filestack, Tesseract, or AWS Textract. This way, you don’t have to build the OCR functionality from scratch.
When it comes to scalable OCR systems, it’s best to use best to use a cloud-based solution like Filestack. Moreover, use scalable storage solutions, such as cloud storage,. This will ensure that the system can store large volumes of OCR data without affecting performance.
Load balancing and auto-scaling strategies
- Distribute tasks evenly across all OCR instances.
- Distribute tasks based on the client’s IP address to ensure consistent routing.
- Implement horizontal scaling by adding more OCR instances when the load increases.
- Implement vertical scaling by increasing the resources, such as CPU and memory of existing instances.
Implementing OCR microservices
- Divide the OCR functionality into smaller, independent services called microservices. For example, you can create a microservice for image pre-processing, OCR processing and post-processing.
- Use lightweight communication protocols like HTTP/REST.
- Implement a mechanism for services to communicate with each other.
- Use a platform like Docker to containerize microservices.
- Manage containerized services using Kubernetes or Docker Swarm
Batch Processing for Large Datasets
Implementing efficient batch processing
Implementing batch processing helps with the efficient handling of large datasets or high volumes of data. With batch processing, we can process multiple documents concurrently. This saves time, optimizes resources and improves overall efficiency.
Here’s how you can ensure efficient batch processing:
- Determine optimal batch sizes. This depends on various factors, such as document complexity, OCR engine capabilities, and system resources.
- Implement retry mechanisms for failed OCR requests
- Ensure each OCR instance has sufficient resources (CPU, memory). This ensures fast and timely processing.
- Distribute OCR jobs evenly across available processing resources.
- Log errors and exceptions to detect issues and improve reliability.
Optimizing for various document types and sizes
- Convert documents to a common format, such as PDF
- Apply preprocessing techniques to improve OCR accuracy.
- Implement mechanisms to handle multi-page documents and ensure accurate segmentation for processing.
Serverless OCR Implementation
Leveraging serverless functions for OCR tasks
Implementing OCR using serverless functions offers various benefits:
- Scalability: Serverless platforms, such as AWS Lambda and Azure Functions, scale resources automatically based on workload.
- Cost-effectiveness: You only have to pay for the computing resources and time used for each OCR request. This results in significant cost savings compared to traditional server-based architectures.
- Ease of use: With serverless functions, you don’t have to worry about infrastructure management and server maintenance.
Event-driven OCR processing
- Automatically trigger OCR functions when certain events occur, such as file uploads or HTTP requests.
- Implement asynchronous processing to handle OCR tasks.
Cost optimization for serverless OCR
- Optimize cost and performance by adjusting memory allocation and timeout settings for OCR functions.
- Set reasonable concurrency limits to limit the number of OCR functions executing simultaneously.
- Ensure your OCR functions and data storage are within the same cloud region to minimize data transfer costs.
OCR Data Pipeline and Workflow Automation
- Design the system to accept various input files, such as scanned documents, images, PDF files, and digital files.
- Implement mechanisms to ingest documents into the pipeline, such as file uploads
- Implement pre-processing techniques to enhance image quality. This, in turn, improves OCR accuracy. Pre-processing involves techniques like noise reduction and binarization.
- Utilize an OCR engine for document processing to extract text from scanned documents. While various OCR solutions are available, it’s best to use a cloud-based solution like Filestack, as it allows for scalability.
- Enable batch processing for large volumes of documents.
- Implement post-processing mechanisms. These include techniques like data normalization, error correction, and data formatting.
- Convert captured data/OCR output into structured data formats, such as JSON and CSV, for storage and analysis. You can use tools like Apache Spark and AWS Glue.
- Load the structured data into your target systems, such as databases or data lakes.
- Implement data quality checks, such as schema validation, within ETL processes. This helps ensure high-quality OCR data.
- Handle dependencies between tasks to ensure data flows smoothly through the pipeline.
- Implement error handling and retry mechanisms to manage failed OCR requests.
Hybrid Cloud and Multi-Cloud OCR Solutions

Implementing OCR across multiple cloud platforms and hybrid cloud environments offers several benefits. These include:
- High Availability: When we distribute OCR tasks across multiple cloud platforms, we minimize the risk of downtime due to a single cloud service provider’s failure. This ensures the availability of OCR services at all times.
- Reduced Latency: By using different cloud regions across multiple providers, you can deploy OCR services closer to end-users. This minimizes latency and improves response times.
- Disaster Recovery: Multi-cloud setups provide built-in disaster recovery options. If one cloud provider experiences an outage, you can seamlessly switch to another provider without service interruption.
- Load Balancing: By distributing OCR workloads across various cloud environments, it’s easier to balance the load.
Strategies for data consistency and synchronization
- Implement cross-region data replication. This will ensure that data is synchronized across multiple cloud platforms.
- Use real-time synchronization tools like AWS DataSync or Azure Data Factory. This will help keep data consistent between on-premises systems and cloud environments.
- Automatically trigger data synchronization based on events, such as new file uploads.
Advanced OCR Techniques in the Cloud
- Utilize pre-trained deep learning models like Filestack, Google’s Tesseract or AWS Textract. These are optimized for basic OCR tasks.
- Fine-tune these models for improved accuracy for certain document types or languages.
- If your OCR system is expected to deal with complex fonts, implement custom CNNs (Convolutional Neural Networks) for character recognition.
- Utilize cloud GPUs for complex OCR tasks. GPUs provide significant computational power. This allows for faster processing of large and complex datasets. Moreover, GPUs can handle multiple OCR tasks simultaneously.
- Continuously update the OCR model with new data. This will improve accuracy and allow the model to adapt to changing document types and formats.
- Implement automated pipelines for regular model retraining using new data.
Cloud OCR Security and Compliance
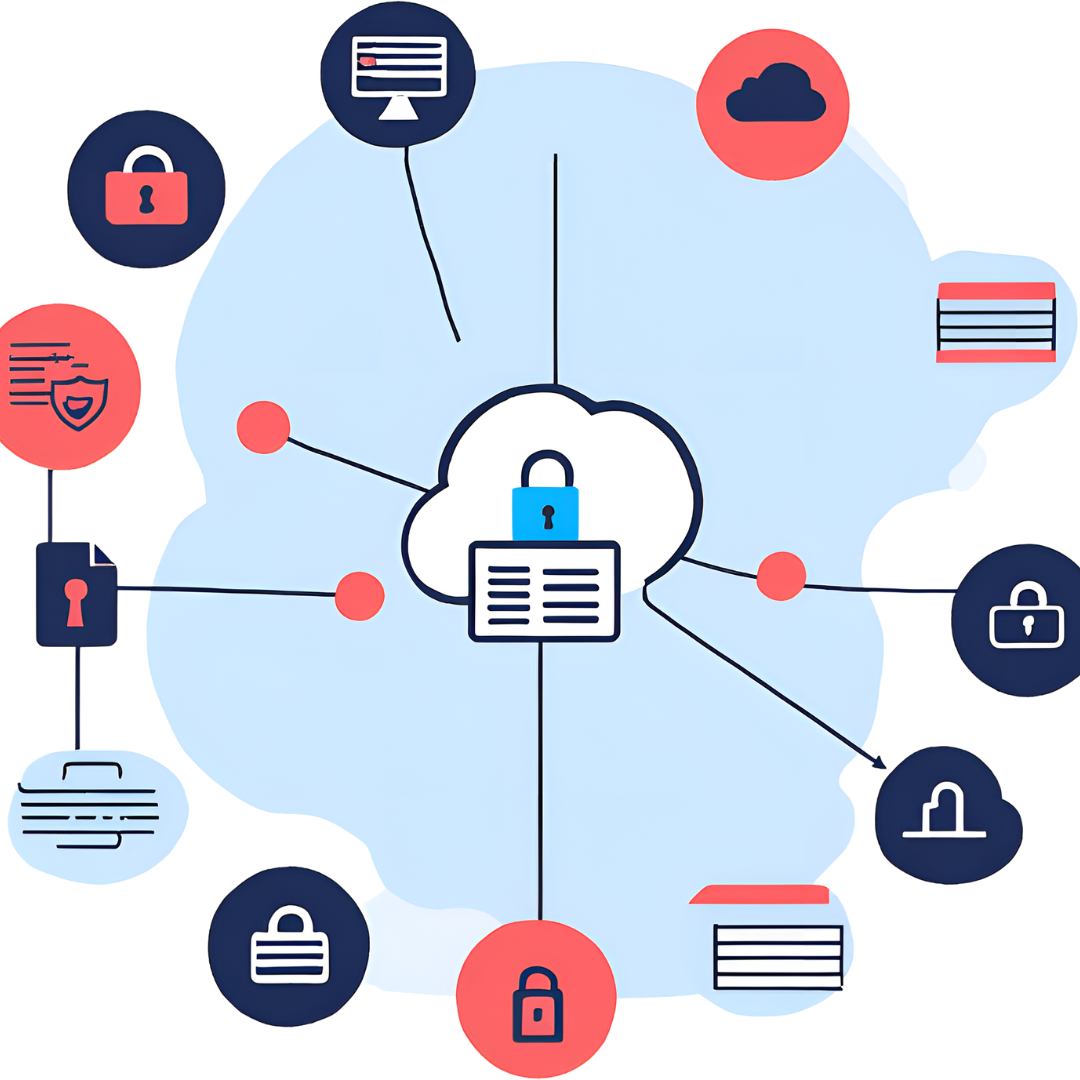
Since the documents that OCR processes can contain sensitive and confidential information, it’s essential to ensure cloud OCR security and compliance. If you’re using Filestack and its OCR capabilities, you get the following security features:
- End-to-end encryption
- Adherence to GDPR
- Robust authentication and authorization mechanisms for API calls
- OAuth authentication
- HTTPS encryption for processing API, including OCR
- TLS to encrypt the data transmitted between clients and servers
- Filestack also supports network isolation, providing an additional layer of security.
In addition to these security features, you can also implement Role-Based Access Control to protect OCR data.
Monitoring and Analytics for Cloud OCR
- Ensure you have a detailed logging mechanism for all OCR activities. This includes file upload, preprocessing, OCR processing, and post-processing.
- Capture logs from cloud services involved in the OCR pipeline.
- Log application-level events and errors. These can include processing start and end times, successful and failed OCR requests, and any exceptions.
- Monitor the availability of OCR systems using cloud-native monitoring tools.
- Measure the average time required to process documents from file upload to completion.
- Track OCR error rates.
- Monitor CPU, memory, and GPU usage to analyze if the resources are being utilized efficiently.
Integration with Enterprise Systems
- Make sure the connection between the on-premises network and the cloud environment is secure. You can use tools like AWS VPN or Azure VPN Gateway for this purpose.
- Use dedicated network links for high-speed and low-latency connections.
- Use a cloud data transfer service like AWS DataSync to transfer large volumes of data between on-premises and the cloud.
- Implement Single Sign-On (SSO) for OCR services. You can use enterprise identity providers for user authentication and authorization. Moreover, using SAML(Security Assertion Markup Language) can ensure a secure exchange of authentication and authorization data.
Conclusion
Optical character recognition technology is widely used across industries. Recently, cloud-based OCR data capture has become increasingly popular due to its scalability, intelligent document processing, and ability to handle large volumes of data. An example of such an OCR solution is Filestack.
Filestack is an efficient cloud-based file-handling platform that also offers powerful OCR capabilities. Filestack allows you to save and upload files in the cloud for scalability. Moreover, Filestack OCR processing itself happens on Filestack’s robust cloud infrastructure.
In this article, we’ve discussed the implementation of cloud-based OCR data capture using Filestack’s platform. Moreover, we’ve explored various techniques and mechanisms for scalable cloud OCR architecture.
FAQs
How does cloud-based OCR handle sensitive data?
Filestack’s cloud OCR implements robust security measures. These include encryption and access controls to protect sensitive data during processing and storage.
Can cloud-based OCR handle documents in multiple languages?
Yes, Filestack’s cloud OCR supports multiple languages. It can be configured to process documents in various scripts and languages simultaneously.
How does the cost of cloud-based OCR compare to on-premises solutions?
Cloud-based OCR often provides cost benefits through scalability and pay-as-you-go models. It is especially useful for organizations with varying OCR workloads.
What kind of accuracy can I expect from Filestack’s cloud-based OCR?
Filestack’s cloud OCR leverages advanced algorithms and machine learning to provide high accuracy. Moreover, it can be further improved through custom training for specific use cases.
Sign up for Filestack and leverage its powerful cloud-based OCR capabilities!

Sidra is an experienced technical writer with a solid understanding of web development, APIs, AI, IoT, and related technologies. She is always eager to learn new skills and technologies.
Read More →