
In this blog post, we will discuss Filestack Object Detection and Localization API in video frames . This process falls under the “Video Captioning” category of processing, which refers to any process of describing video frames and showing it as the result.
Our main objective is to divide the entire video file into individual frames, shrinking the frames into batches of data for parallelized processing (master and slave processing units), sending each batch to the proper processing unit. We then apply our object detection and localization models (Regional Convolutional Neural Networks) on each data batch in the slave nodes, generating the inferred results, and sending all of the results back to the master computation node. Here’s how it looks in action (This is a clip from an interview Sameer Kamat, Filestack CEO, did for KENS5 News):

The applications for this are virtually limitless, but let’s go over a specific example. Say a construction software company uses drones to monitor their clients’ sites. A client calls in asking for specific footage of one of their cranes that was damaged. Without parallelized object detection and localization in place, this endeavor could take hours. With this technology in place however, all it would it take is a simple search using the term “crane” in their database, and they could deliver the results in minutes. Let’s dive into exactly how this process would work.
Introduction to Parallelized Object Detection and Localization
During recent years, AI has affected almost everything regarding human life. AI can also be referred to as Machine Learning and Deep Learning, going back to the 1990s. In Machine Learning, in the classes of deep and feed-forward artificial neural networks, Convolutional Neural Networks (CNN) were made for analyzing visual imagery. Along with the advent of Machine Learning and its applications, high performance computing has evolved several times from each generation to the next.
One of most recent standardized architectures for increasing computation speed is Message Passing Interface, also known as MPI. This architecture uses both shared memory or distributed memory infrastructures to divide the whole processing unit into subunits called nodes to share the entire computation loads among them. Nodes can be different processors of a cluster or even a part of the main processor. Using this architecture can boost any computational tasks in terms of execution time.
In this project, the main goal is to use the Message Passing Interface as a parallelized architecture for implementing convolutional deep neural networks into video frames for describing them. This video description objective is to classify the frames, find the pre-defined objects, localize them, and then show them inside their bounding boxes with their rates of probability. All of the project has been prepared in the Python 3.x language using frameworks of TensorFlow and Keras (on TF Backend).
Multiple Parallelized Processing using Message Passing Interface
Figure 1 shows the general schema of the MPI architecture using shared memory. In this scenario, the master node; e.g. Processor 1; has the ability to distribute the entire computation task into the slave nodes; e.g. Processor 2, 3, …, n; simultaneously in order to maximize their capability to do the assigned tasks.
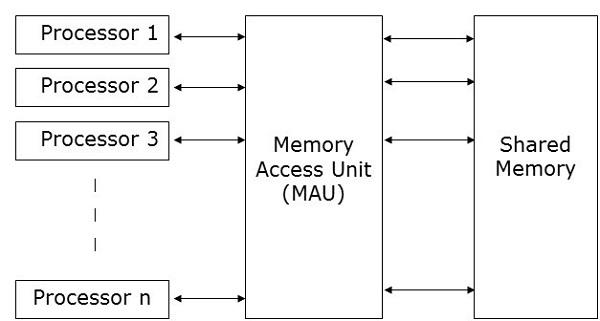
After finishing the tasks on each slave node, they send their resulting messages to the master node to be generated into the final result. Figure 2, on the other hand, shows the distributed memory architecture for MPI parallelized processing, which can be either equally or weighted memory allocation. Although the distributed memory scenario decreases the power of the memory by dividing it for each node, it can make the entire process operate synchronously, while the shared memory is an asynchronous procedure.
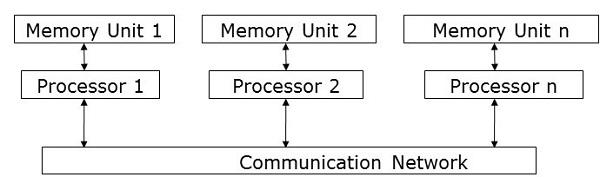
Although the distributed memory scenario decreases the power of the memory by dividing it for each node, it can make the entire process operate synchronously, while the shared memory is an asynchronous procedure.
CNNs for Object Detection and Localization
Returning to the 1990s, Convolutional Neural Networks were invented with the main goal of generating mutual patterns from images as the feature maps to infer the information and classify them.
Figure 3 shows a simplified block diagram of CNNs.
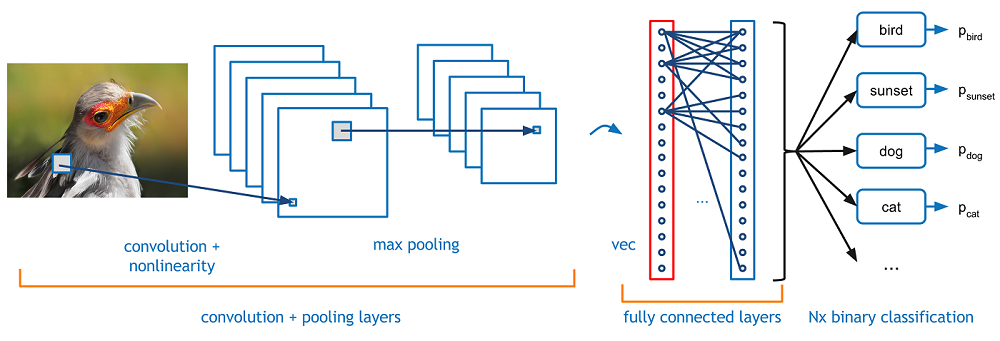
These models use kernel windows to extract samples of images with the convolution function, decrease their size by pooling them, and use neural networks to reach the desired labels outputs. All of the layers between input and output are considered hidden layers. Region-based Convolutional Neural Networks (R-CNN) methods concentrate on doing the both classification of CNNs and also finding the classified object inside the image. This process consists of Modeling, Training, and Validation.
In the case of video files, when the objective is to process all of the frames, find the objects and localize them, the computation speed of the used core algorithm would be the main concern. As a state-of-the-art which was released in 2017, Single Shot Multi-box Object Detectors (SSD) became very popular due their high accuracy as well as simple structure to make the process faster. This is why Filestack uses this algorithm in a new parallelized architecture to make the video captioning fast and accurate.
Filestack Video Captioning
In the previous section, it was mentioned that the core algorithm for processing the frames is SSD. Figure 4 shows the architecture of SSD versus YOLO. Unlike YOLO which process the resized images to 448×448 pixels, SSD makes the resizing smaller to the resolution of 300×300. This may lose more features of the original image, but it makes the inference, training, and validation faster. Also, as it can be seen in the following image, the main structure focuses on convolutional layers and more feature layers comparing to YOLO. That would be the main reason why SSD can process up to 60 images per second.
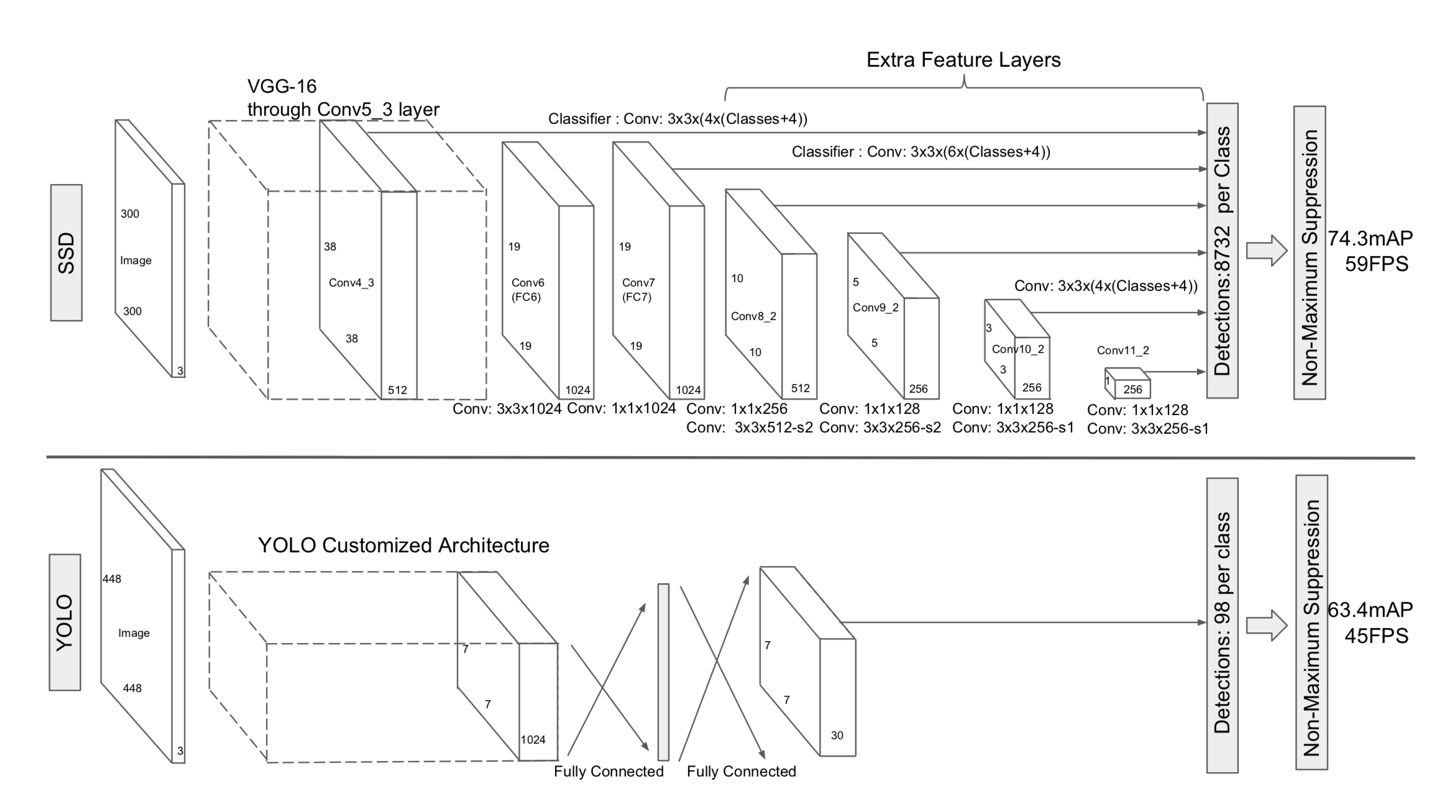
Filestack’s main goal here is to make the processes faster, more reliable, and accurate. Using this approach, our structure is not only one of the most precise Machine Learning models for detection and localization, but we have also made a new parallelized architecture for distributing the computation into the different cores of the processor in order to get the fastest result.
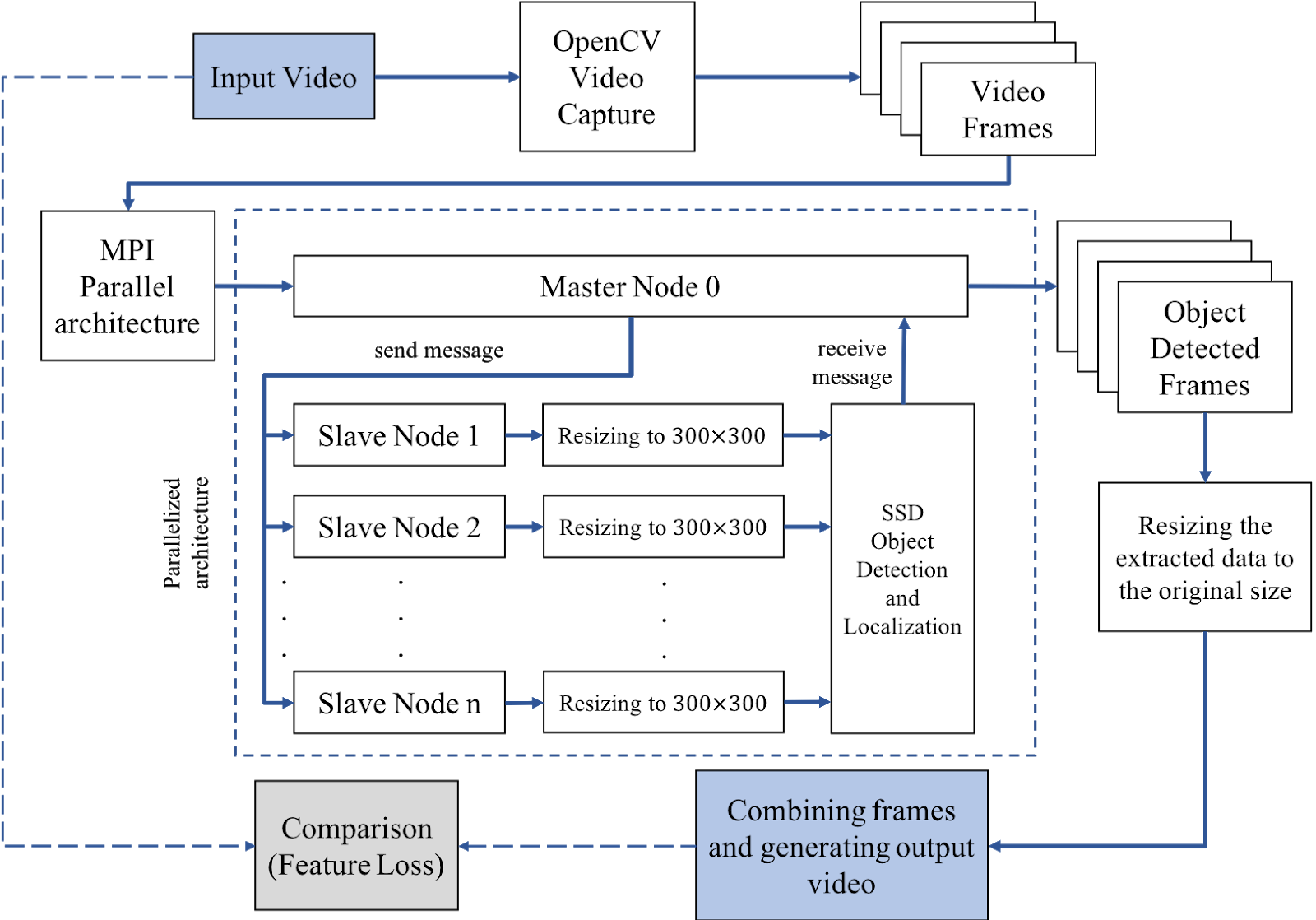
Figure 5 shows the main architecture of the Filestack Video Captioning API. First, by feeding the input video and using OpenCV library and captioning tools, the video file is shrunk to all of the frames; after that, the total frames are divided into batches for each slave node. Using MPI structure in each processing node, the batches of images are resized to the proper resolution for SSD processing.
By implementing the SSD in each slave node, the results (as the receiver messages) are sent to the master node and are prepared for the final result. The extracted information is adjusted to the original image size and can be either shown in a JSON format script or as a layer on top of the reconstructed images, and shown as the final result.
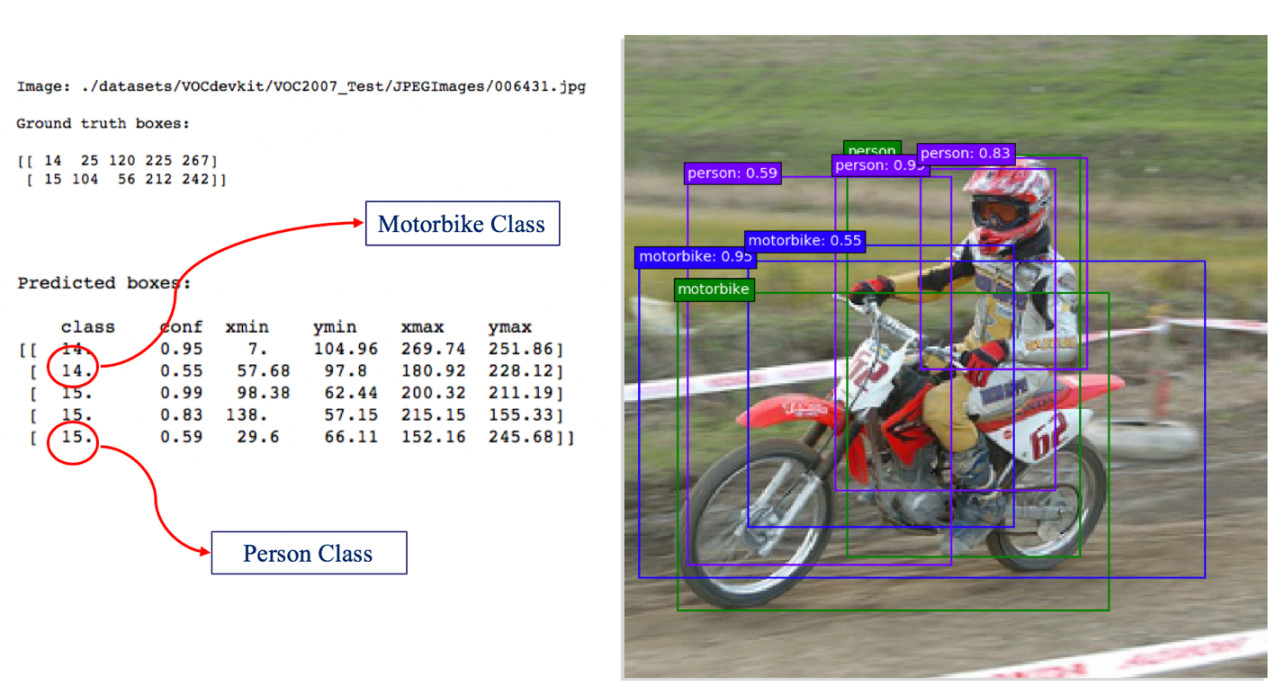
Figure 6 shows an example of running parallelized SSD on a single frame which has the reconstructed image and all of the inferred information from the model results as either visual or script results. All of the detected objects have the confidence number which represents the normalized probability of object presence inside. In the above example, three predictions have been made for the person which shows that the smallest and largest boxes have the lower confidence numbers.
Conclusion
In this blog post, Filestack’s optimized new technology for object detection and localization has been introduced. Using a parallelized processing architecture with the Message Passing Interface, we have leveraged the Single Shot Multi-box object Detection method to increase accuracy and the evaluation time, to achieve our goal of processing video frames and captioning them.
Do you have a use case for this technology? We’d love to talk about it! Also feel free to leave any comments in the comment section below.
Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.
Read More →