![]()
Have you ever dropped code in to a project, and watched it magically work as intended on the first try? It’s a good feeling, but somewhere in the back of your mind there may be a little voice whispering: “I have no idea why that just worked.” You’re not alone. With the explosive rise in packages, libraries, SDKs, and services, it’s hard to keep a firm grip on how everything is wired up under the hood.
Developers can find themselves calling functions, generating code, and auto-completing their way through complex challenges. This is both powerful and disorienting; powerful, because we don’t have to think about lower-level problems, but disorienting when we need (or want) to play in that space. The opposite can also be true: sometimes we focus on solving problems at a lower level than we should, because we approach the problem first by trying to understand everything. This can lead us to reinventing the wheel, because we’re not taking advantage of the powerful features available to us.
Finding a balance between understanding our tools and just invoking them blindly really comes down to a question of trust. When developers evaluate tools, frameworks, libraries, and services, we look at a number of factors. Is the implementation going to save me time? Is it well-rounded, mature enough to use in production, and supported by people focused on improving, maintaining, and updating it over time? If the answers are “yes”, we’re able to leverage that functionality and trust the solution. We can stop worrying about the problems that solution solves, freeing us up to focus on what makes our project unique.
With this in mind, let’s look at best practices for file uploads, and then indulge in a deep dive under the hood to see what makes these best practices tick. If you’re looking for a “Curl upload file tutorial,” you’re in the right place to explore the inner workings of file uploads and gain a better understanding of how they function.
Best Practice: File Uploads
Filestack’s SDKs and open source offerings are the best way to upload files. You can upload, transform, and deliver files with automated Machine Learning intelligence with as little as one line of code. If you’re building a production solution, you should be using these officially supported tools. You can safely ignore the entire second half of this post; Filestack handles files so you don’t have to think about them.
If you’re interested in what’s happening under the hood, thinking about coding an integration with Filestack’s file handling in a unique environment, or if you’d like to geek out on some lower-level tech stuff, read on!
Under the Hood: What Makes it Tick?
Filestack’s officially supported SDKs are basically wrappers around lower-level functionality. It’s code our amazing Engineers wrote to save you time. It’s also open source, so you can read for yourself and see how it was put together!
- https://github.com/filestack/filestack-js
- https://github.com/filestack/filestack-python
- https://github.com/filestack/filestack-ruby
- https://github.com/filestack/filestack-php
- https://github.com/filestack/filestack-react
- https://github.com/filestack/filestack-swift
- https://github.com/filestack/filestack-rails
- https://github.com/filestack/filestack-android
- https://github.com/filestack/filestack-java
- https://github.com/filestack/filestack-ios
- and the Adaptive Image library: https://github.com/filestack/adaptive
Ultimately, whether you’re using one of the web SDKs, server-side language SDKs, or mobile SDKs, everything hits the same APIs behind the scenes.
Let’s take a look inside one of these SDKs to see how it works. I’ll check out the PHP SDK.
Drilling down into the /filestack folder, I see a file called FilestackClient.php:
https://github.com/filestack/filestack-php/blob/master/filestack/FilestackClient.php#L4
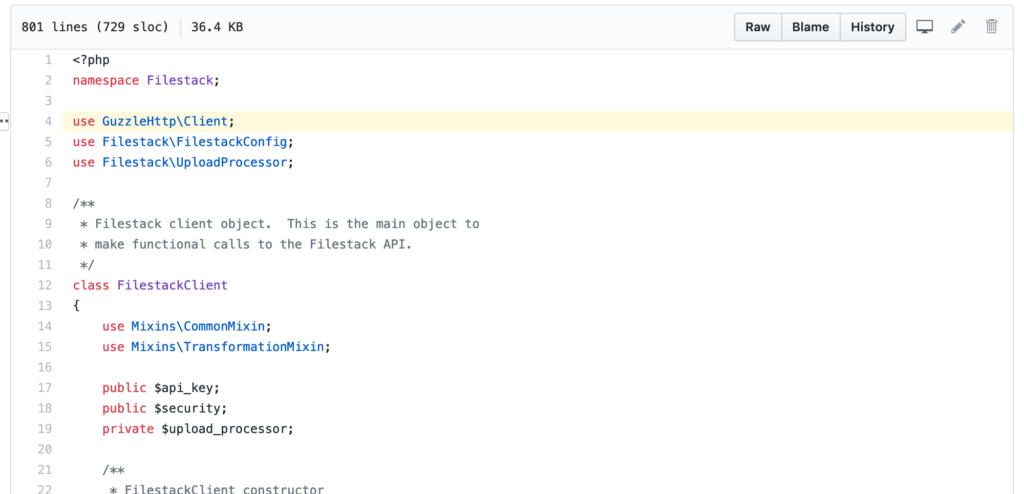
Here, we see the GuzzleHttp Client package is being used. It is instantiated during initialization of the FilestackClient class within the __construct() method:
https://github.com/filestack/filestack-php/blob/master/filestack/FilestackClient.php#L38
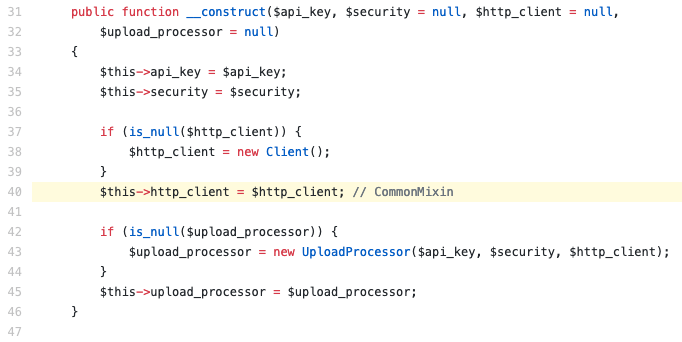
And this then is assigned to the object’s $http_client property. Reading further into the class definition, we can see several methods dealing with CDN URLs, but let’s skip down to a common use case: uploading a file. There’s a method for that:
https://github.com/filestack/filestack-php/blob/master/filestack/FilestackClient.php#L664

This method accepts two arguments: the path to the file we wish to upload (from disk), and an array of options (which can be empty by default).
What is REST?
The Filestack SDKs are language-specific wrappers around RESTful API calls. What does that mean? Basically REST is HTTP being used as it was designed to be used.
In the O’Reilly book, “RESTful Web APIs” by Leonard Richardson & Mike Amundsen, they describe RESTful APIs as being “designed for managing change.” (Introduction, pg. xv.)

It’s a great read if you want to dig deeper into the philosophy and technical constraints that comprise RESTful API design, but for now let’s move forward to a practical exercise in manually interacting with Filestack’s API.
Filestack’s docs show how you can directly access these HTTP requests from the command line using cURL:
https://www.filestack.com/docs/concepts/uploading/#upload-file
Again, you should be using one of the official Filestack SDKs if you’re deploying a production website or app in a language/platform covered by one of the SDKs. But if you’re looking to integrate with Filestack’s services in any HTTP-capable environment, you can directly interact with the API using GET, POST, and other HTTP request methods like DELETE.
What is cURL?
What if we wanted to interact with this RESTful API manually, on the CLI or in a shell script? As we saw looking under the hood in the SDKs, many languages ship with packages that make working with HTTP requests a bit of an abstracted pursuit. cURL shares that goal in the sense that it abstracts the way you interact with things like HTTP requests, but it’s more targeted to human use and shell scripting. It offers some powerful features like sets. If you pass `http://site.{one,two,three}.com` as a URL, for example, it will iterate through each substitution.
What is HTTP?
The HyperText Transfer Protocol is really just text that computers agree upon when exchanging information. A library might let you do something like `req.send(“Hello!”);`, but it in turn is likely calling another library (like cURL in many cases). That in turn ultimately shakes down to simple text being passed between computers. The format of these exchanges uses different sets of rules, each of which are established as protocols. HTTP is one of several protocols that the curl command supports, including DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, TELNET and TFTP (from the curl MANPAGE).
How do I make HTTP requests with cURL?
Glad you asked! Many systems ship with a version of cURL already included. Here’s the version on my Mac:

You can download the official distribution, but here’s another option you can use from anywhere: I’ve created a project on Glitch.com called, amazingly, curl! Here’s the link: https://glitch.com/~curl
You can’t access the terminal on my project, nor can you view the values of the APIKEY for my account, but you can fork that project and get your own copy. In your copy (or in any Glitch project), you can open the Tools menu, then click on the Terminal. Run the command `which curl` and you can see the path to the native executable in that container.
Whether you use a virtual environment in your browser, a remote system that you’ve SSH’d into, or a local copy of cURL on your system, the commands are the same. You specify options with flags, type out the commands, hit enter/return, and curl transmits the resulting message in the proper protocol.
The effect of running the command depends on what you’re doing. If you’re downloading a file, for example, you need to instruct curl to drop the output to a file as it receives the data.
Enough talk, though, let me show you.
curl -X GET "https://www.filestackapi.com/api/file/DCL5K46FS3OIxb5iuKby/metadata"
The command above should be entered on the command line. This makes a GET request directly to the Filestack File API, and the result should echo out to your terminal.
Pretty cool, huh? Filestack’s documentation provides cURL examples (where relevant) for direct interaction with the APIs so you can see this almost-raw request and response format. When you look inside the SDKs (remember, you should be using the SDKs if you can), you can find the same exact things happening under the hood. For example, here’s where the TypeScript used to generate the JavaScript SDK is handling this same metadata request:
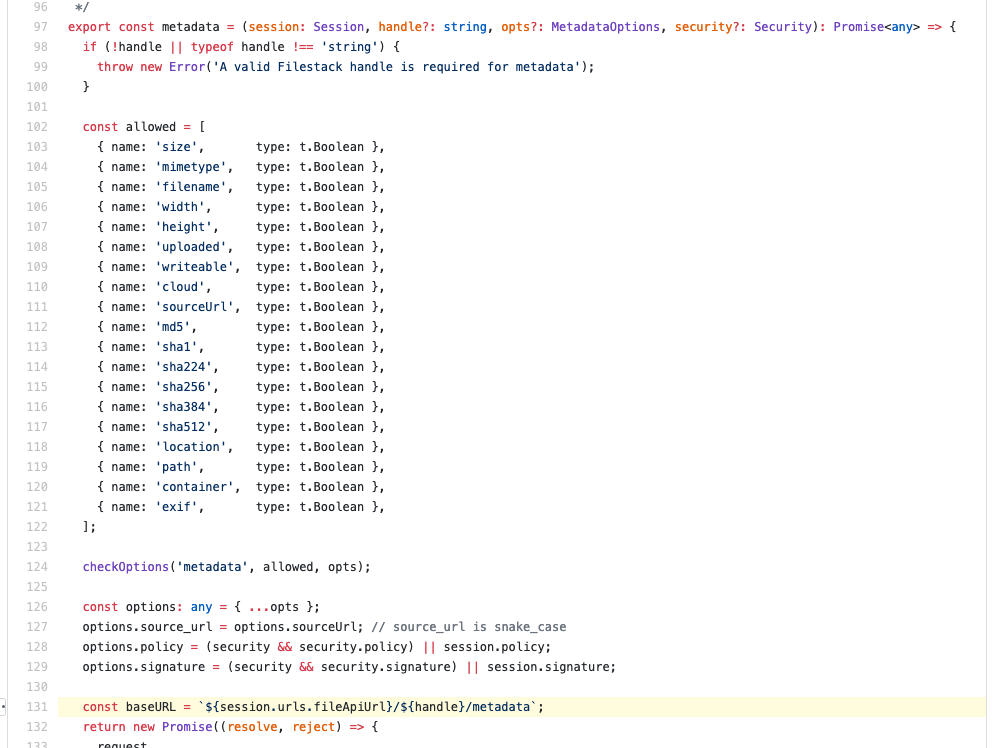
If you look around inside of that method, you’ll see there’s really quite a lot more going on. The SDK is checking that all of the options are correctly specified, and simplifying robust file handling processes so you can just call the SDK’s methods and get results fast.
David Liedle is Filestack’s Chief Evangelist. He works remotely in New York City with his wife and son, and their kitty. See more at https://DavidCanHelp.me/
Read More →