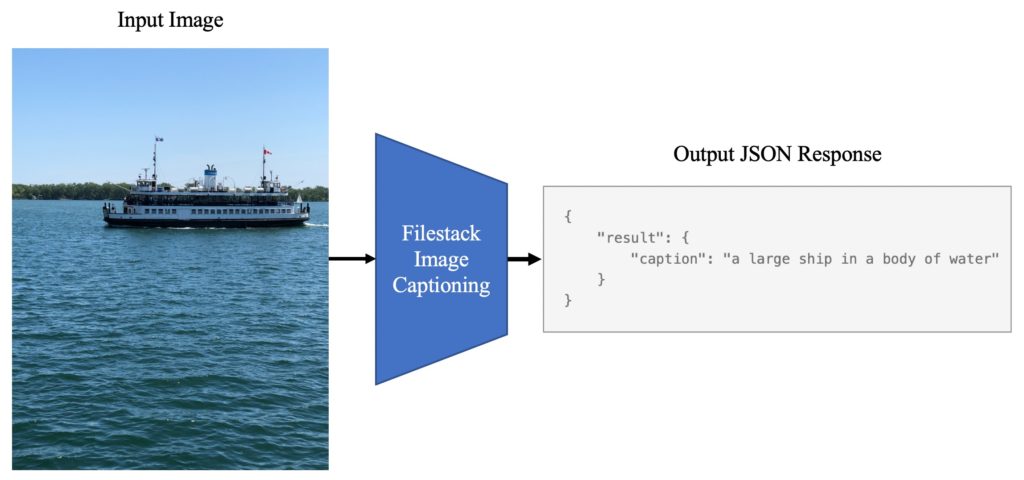
The twenty-first century or, in other words, the Artificial Intelligence Era was started with the advent of deep learning in computer vision. Here, data scientists’ main goal was to extract visual features from images, classify them, and detect objects. As another point of view, during the past years, Natural Language Processing algorithms played an inevitable role in deep learning science to make machines capable of learning from the world of words, understanding them, classification, and feature extraction.
Today we’ve reached the point where plenty of state-of-the-art algorithms in these fields can fulfill the aforementioned objectives. But recently, one of the main questions was how to translate images into sentences? How can you translate your image from the pixel values to the alphabet characters’ ascii codes? If you were asking this question a couple of years ago, perhaps it was impossible to answer, but today, it’s among the next generation of deep learning models.
Here at Filestack, we developed an advanced algorithm to receive your images and return a set of semantic words in phrases or sentences to describe it. Looking at this service as a black box, it extracts features from your image, and generates a set of words corresponding to detected features. This story reveals the algorithm and technology behind what we used to solve this problem.
Model Architecture
Filestack Image Captioning module mainly consists of two sections, “encoder” and “decoder”.
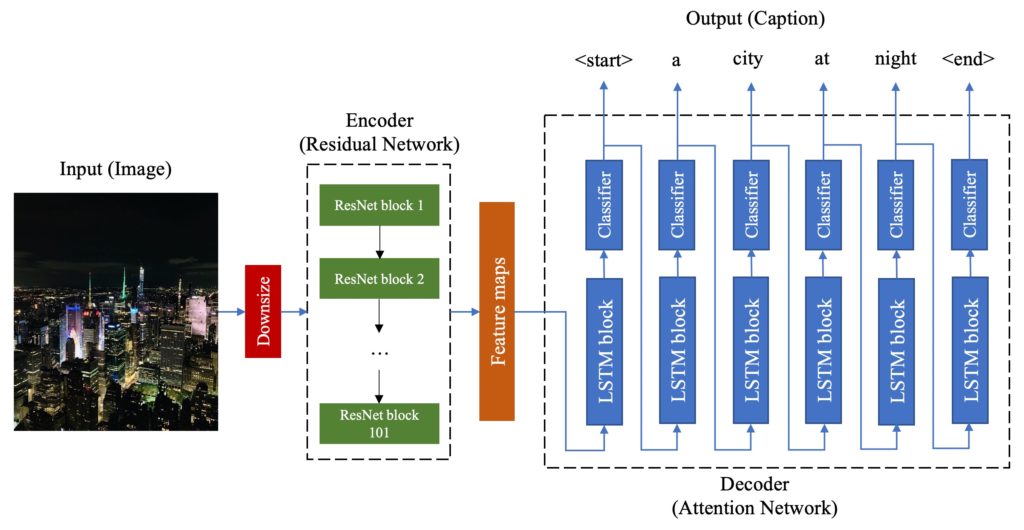
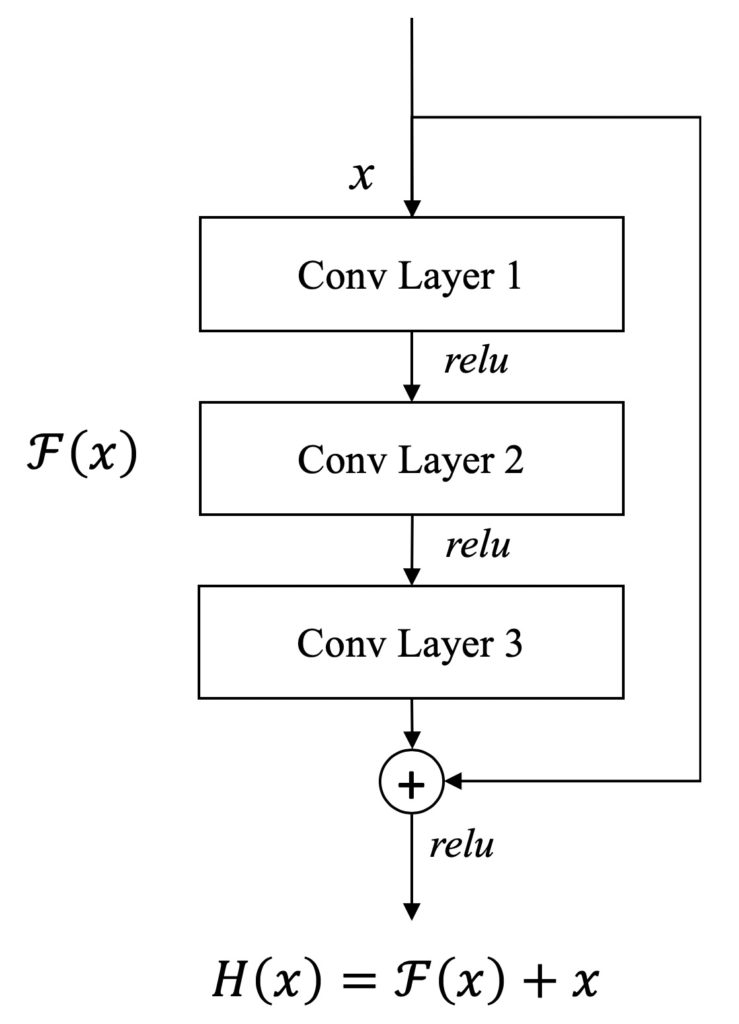
Having Shown in Figure 1, first, the image would be resized to the encoder’s required size, i.e. 256×256. The resized image would be fed into the encoder which is generally a Convolutional Neural Network. The encoder block consists of 101 blocks of residual network which is one of the benchmarks in object detection, but without the last layer (labels). A block of ResNet is shown in Figure 2. It has three Convolutional layers with “relu” activation function, following by their max pooling.
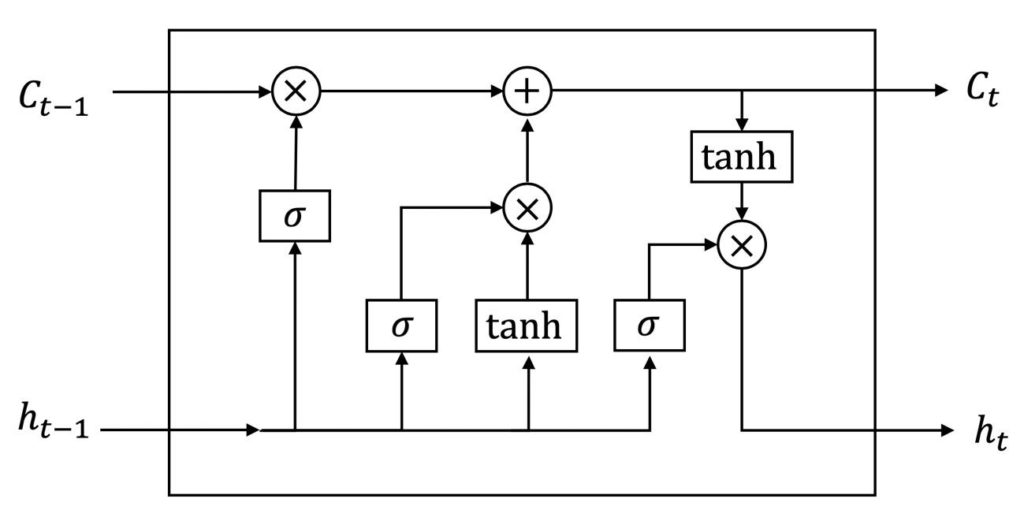
The output of the encoder is the feature map of the image. Feature map is one of the inputs in the decoder part. The decoder is a single layer with multiple blocks of “Long Short-term Memory” (LSTM) networks. The other input of decoder is the dictionary of words generated from the captions used during the training. Using a custom and extended image dataset labeled with approximately five captions individually each of which with at least four words, this network was trained and tuned. The library of words is the set of ~10k words which are repeated at least four times in the captions. Each result caption starts with a <start> state in the sentence and ends with <end> state which means the caption is complete. Each LSTM block gets the output of the previous block as well as the word dictionary to predict the next semantic word. The length of LSTM layer is variable and depends on when the <end> state happens. The simplified structure of one LSTM network block is shown Figure 3 coming with mathematical functions. It is essential to mention that the classifiers in all attention network blocks are “Softmax”.
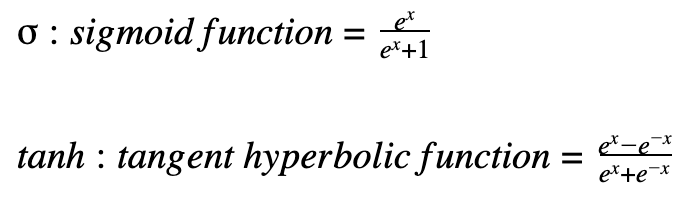
Attention Network
As mentioned in the previous section, the feature map of the image is one of the inputs in the attention network (LSTM layer). The LSTM blocks generate their output in regard to related regions in images. Figure 4 shows an example of attention plots for each word in the caption. Each predicted word in the semantic set are shown with their corresponding attention plot (related regions in the original image).

Conclusion
Image Captioning, one of the recently released intelligence tasks by Filestack, has been introduced in this story alongside with its architecture and the details in each block. It gets an image (a 3D matrix of intensity values) and returns a set of related words in a sentence or phrase describing the image. It has an object detector core (ResNet 101) without the last layer to generate feature maps of the image and uses those feature maps as well as the dictionary of words (generated from training procedure) in the Recurrent Neural Network (LSTM) to predict the next semantic words with their correlated image regions.
Reference
Filestack Image Captioning Documentation
Filestack is a dynamic team dedicated to revolutionizing file uploads and management for web and mobile applications. Our user-friendly API seamlessly integrates with major cloud services, offering developers a reliable and efficient file handling experience.
Read More →